作者:vivo 官网商城开发团队 - Cheng Kun、Liu Wei
本文介绍了交易平台的设计理念和关键技术方案,以及实践过程中的思考与挑战。
点击查阅:《vivo 全球商城》系列文章
vivo官方商城经过了七年的迭代,从单体架构逐步演进到微服务架构,我们的开发团队沉淀了许多宝贵的技术与经验,对电商领域业务也有相当深刻的理解。
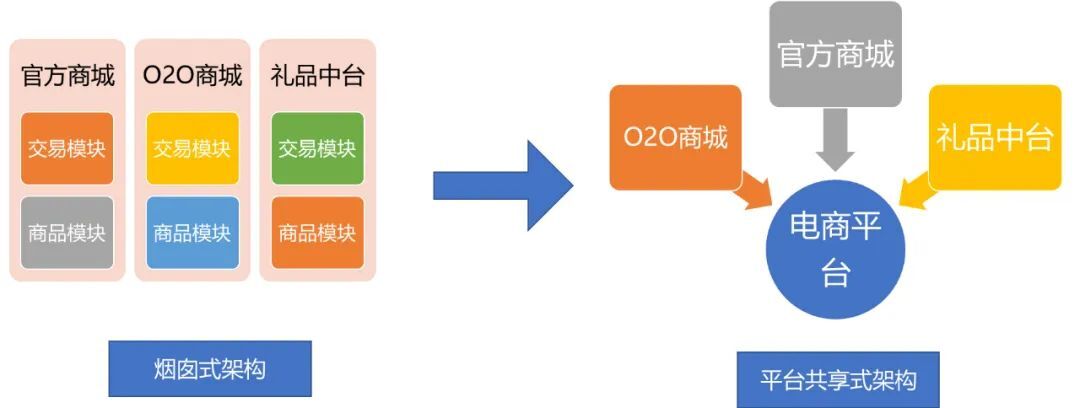
去年初,团队承接了O2O商城的建设任务,还有即将成立的礼品中台,以及官方商城的线上购买线下门店送货需求,都需要搭建底层的商品、交易和库存能力。
为节约研发与运维成本,避免重复造轮子,我们决定采用平台化的思想来搭建底层系统,以通用能力灵活支撑上层业务的个性化需求。
包括交易平台、商品平台、库存平台、营销平台在内的一整套电商平台化系统应运而生。
本文将介绍交易平台的架构设计理念与实践,以及上线后持续迭代过程中的挑战与思考。
除了高并发、高性能、高可用这三高外,还希望做到:
1.低成本
注重模型与服务的可重用性,灵活支撑各业务的个性化需求,提高开发效率,降低人力成本。
2.高扩展
系统架构简单清晰,应用系统间耦合低,容易水平扩展,业务功能增改方便快捷。
(1)电商平台整体架构中的交易平台
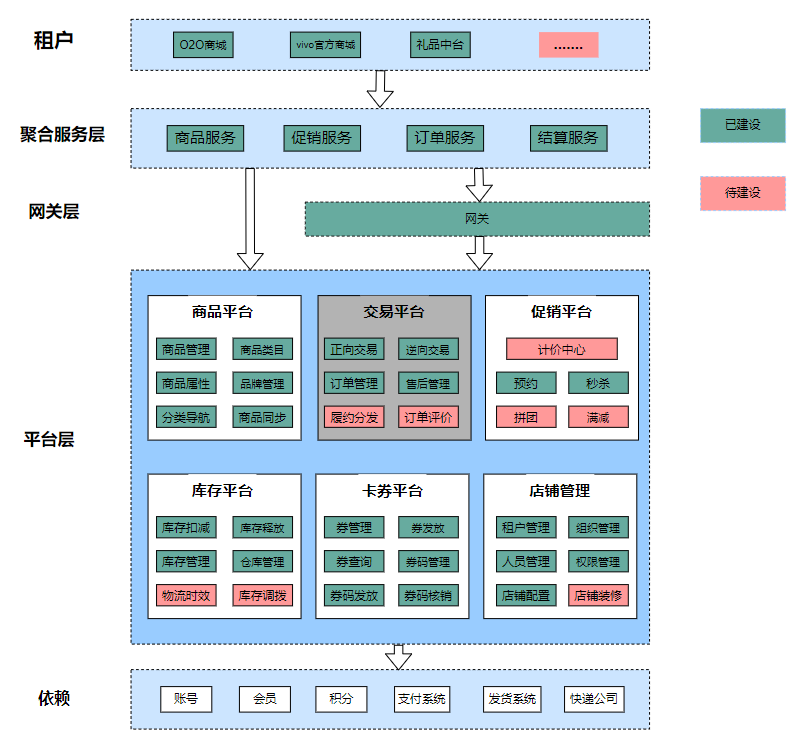
(2)交易平台系统架构
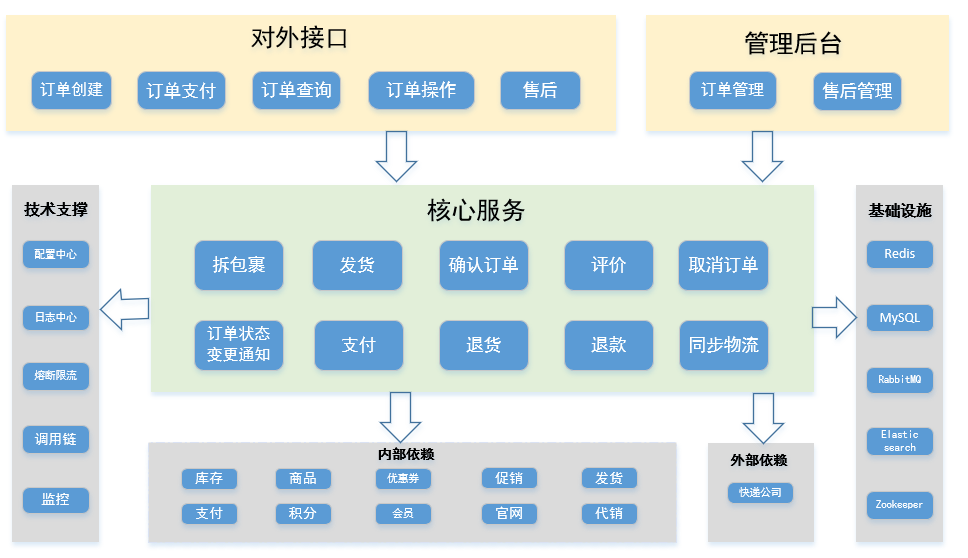
(1)背景和目标
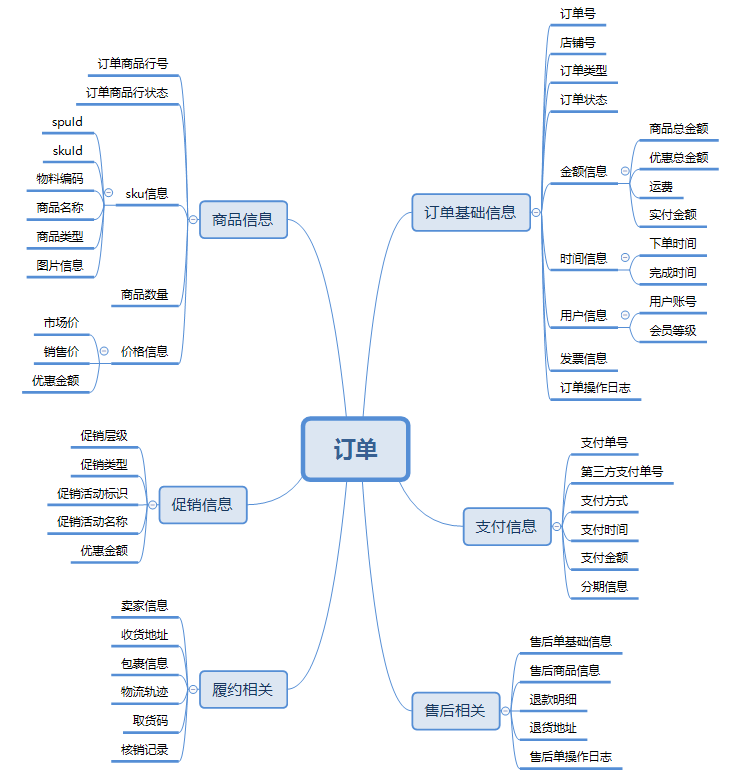
交易平台面向多个租户(业务方),需要能够存储大量订单数据,并提供高可用高性能的服务。
不同租户的数据量和并发量可能有很大区别,要能根据实际情况灵活分配存储资源。
(2)设计方案
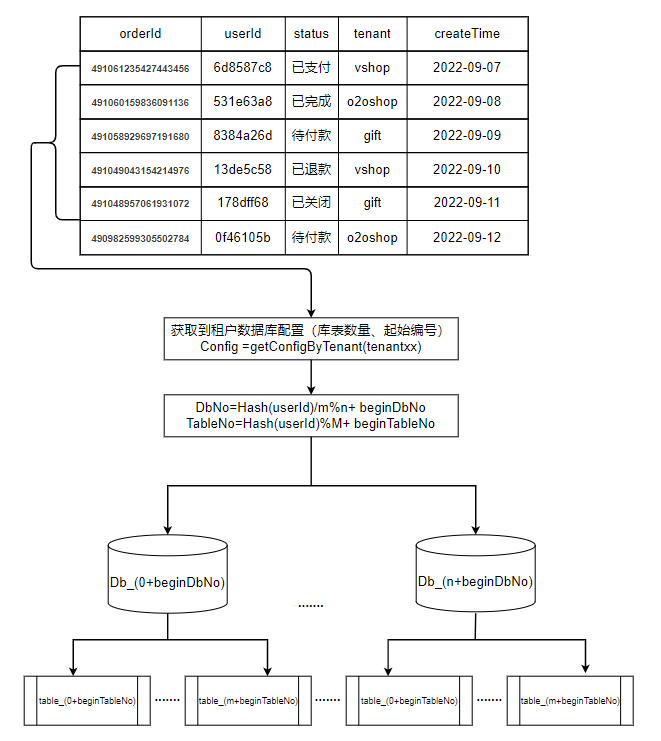
考虑到交易系统OLTP特性和开发人员熟练程度,采用MySQL作为底层存储、ShardingSphere作为分库分表中间件,将用户标识(userId)作为分片键,保证同一个用户的订单落在同一个库中。
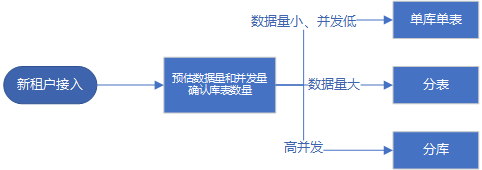
接入新租户时约定一个租户编码(tenantCode),所有接口都要带上这个参数;租户对数据量和并发量进行评估,分配至少满足未来五年需求的库表数量。
租户与库表的映射关系:租户编码 -> {库数量,表数量,起始库编号,起始表编号}。
通过上面的映射关系,可以为每个租户灵活分配存储资源,数据量很小的租户还能复用已有的库表。
示例一:
新租户接入前已有4库*16表,新租户的订单量少且并发低,直接复用已有的0号库0号表,映射关系是:租户编码-> 1,1,0,0
示例二:
新租户接入前已有4库*16表,新租户的订单量多但并发低,用原有的0号库中新建8张表来存储,映射关系是:租户编码-> 1,8,0,16
示例三:
新租户接入前已有4库16表,新租户的订单量多且并发高,用新的4库8表来存储,映射关系是:租户编码-> 4,8,4,0
用户订单所属库表计算公式
可能有小伙伴会问:为什么计算库序号时要先除以表数量?下面的公式会有什么问题?
答案是,当库数量和表数量存在公因数时,会存在倾斜问题,先除以表数量就能剔除公因数。
以2库4表为例,对4取模等于1的数,对2取模也一定等于1,因此0号库的1号表中不会有任何数据,同理,0号库的3号表、1号库的0号表、1号库的2号表中都不会有数据。
路由过程如下图所示:
(3)局限性和应对办法
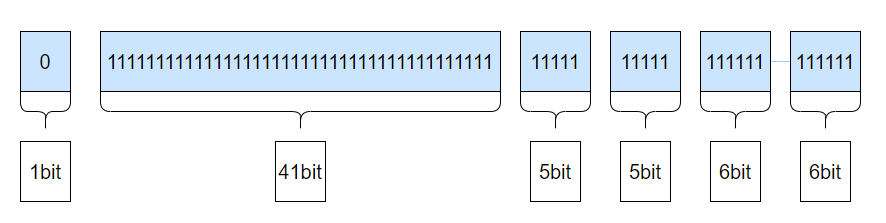
全局唯一ID
问题:分库分表后,数据库自增主键不再全局唯一,不能作为订单号来使用。且很多内部系统间的交互接口只有订单号,没有用户标识这个分片键。
方案:如下图所示,参考雪花算法来生成全局唯一订单号,同时将库表编号隐含在其中(两个5bit分别存储库表编号),这样就能在没有用户标识的场景下,从订单号中获取库表编号。
全库全表搜索
问题:管理后台需要根据各种筛选条件,分页查询所有满足条件的订单。
方案:将订单数据冗余存储一份到搜索引擎Elasticsearch中,满足各种场景下的快速灵活查询需求。
(1)背景
之前做官方商城时,由于是定制化业务开发,各类型的订单和售后单的状态流转都是写死的,比如常规订单在下单后是待付款,付款后是待发货,发货后是待收货;虚拟商品订单不需要发货,没有待发货状态。
现在要做的是平台系统,不可能再为每个业务方做定制化开发,否则会导致频繁改动发版,代码错综冗余。
(2)目标
引入订单状态机,能为每个业务方配置多套差异化的订单流程,类似于流程编排。
新增订单流程时,尽可能不改动代码,实现状态和操作的可复用性。
(3)方案
在管理后台为每个租户维护一系列订单类型,数据转化为JSON格式存储在配置中心,或存储在数据库并同步到本地缓存中。
每个订单类型的配置包括:初始订单状态,以及每个状态下允许的操作和操作之后的目标状态。
当订单在执行某个动作时,使用订单状态机来修改订单状态。
订单状态机的公式是:StateMachine(E,S —> A , S’),表示订单在事件E的触发下执行动作A,并从原状态S转化为目标状态S’
每个订单类型配置完成后,生成数据的结构是
/**
* 订单流程配置
**/
@Data
public class OrderFlowConfig implements Serializable {
/**
* 初始订单状态编码
**/
private String initStatus;
/**
* 每个订单状态下,可执行的操作及执行操作后的目标状态
* Map<原状态编码, Map<订单操作类型编码, 目标状态编码>>
*/
private Map<String, Map<String, String>> operations;
}复制订单商品行状态机、售后单状态机,也用同样的方式实现
(1)背景
业务中通常都会有这样的延时需求,我们之前往往通过定时任务来扫描处理。
(2)目标
业务方有类似的延时需求时,能够有通用的方式轻松实现
(3)方案
设计通用操作触发器,具体步骤为:
配置触发器,粒度是状态机的流程类型。
创建订单/售后单时或订单状态变化时,如果有满足条件的触发器,发送延迟消息。
收到延迟消息后,再次判断执行条件,执行配置的操作。
触发器的配置包括:
注册时间:可选订单创建时,或订单状态变化时
执行时间:可使用JsonPath表达式选取订单模型中的时间,并可叠加延迟时间
注册条件:使用QLExpress配置,满足条件才注册
执行条件:使用QLExpress配置,满足条件才执行操作
执行的操作和参数
对交易平台而言,分布式事务是一个经典问题,比如:
创建订单时,需要同时扣减库存、占用优惠券,取消订单时则需要进行回退。
用户支付成功后,需要通知发货系统给用户发货。
用户确认收货后,需要通知积分系统给用户发放购物奖励的积分。
我们是如何保证微服务架构下数据一致性的呢?首先要区分业务场景对一致性的要求。
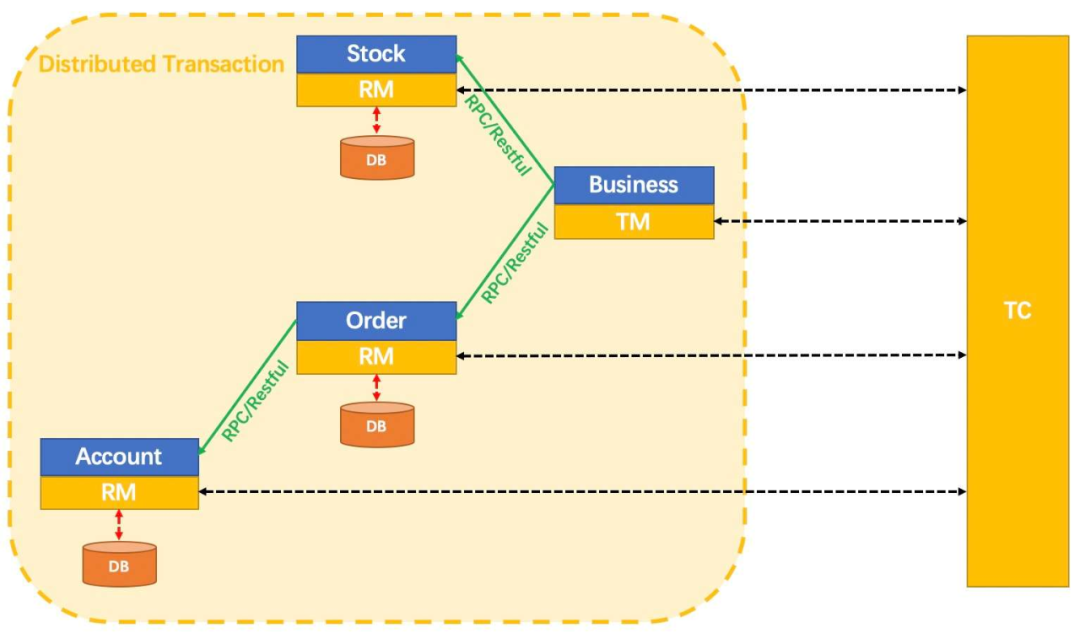
(1)强一致性场景
比如订单创建和取消时对库存和优惠券系统的调用,如果不能保证强一致,可能导致库存超卖或优惠券重复使用。
对于强一致性场景,我们采用Seata的AT模式来处理,下面的示意图取自seata官方文档。
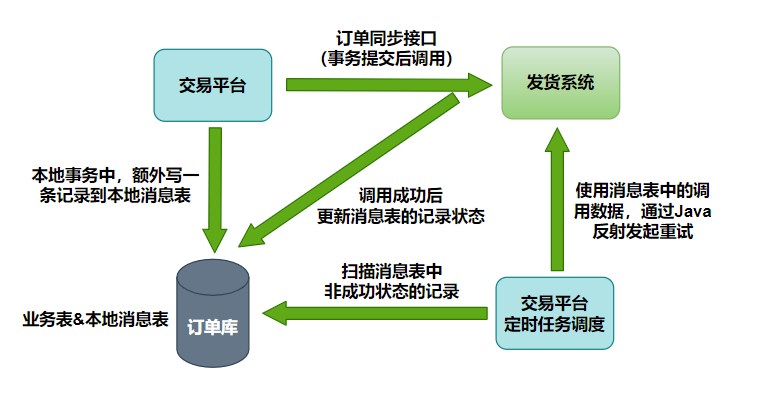
(2)最终一致性场景
比如支付成功后通知发货系统发货,确认收货后通知积分系统发放积分,只要保证能够通知成功即可,不需要同时成功同时失败。
对于最终一致性场景,我们采用的是本地消息表方案:在本地事务中将要执行的异步操作记录在消息表中,如果执行失败,可以通过定时任务来补偿。
熔断
使用Hystrix组件,对依赖的外部系统添加熔断保护,防止某个系统故障的影响扩大到整个分布式系统中。
限流
通过性能测试找出并解决性能瓶颈,掌握系统的吞吐量数据,为限流和熔断的配置提供参考。
并发锁
任何订单更新操作之前,会通过数据库行级锁加以限制,防止出现并发更新。
幂等性
所有接口均具备幂等性,上游调用我们接口如果出现超时之类的异常,可以放心重试。
网络隔离
只有极少数第三方接口可通过外网访问,且都有白名单、数据加密、签名验证等保护,内部系统交互使用内网域名和RPC接口。
监控和告警
通过配置日志平台的错误日志报警、调用链的服务分析告警,再加上公司各中间件和基础组件的监控告警功能,让我们能够能够第一时间发现系统异常。
是否用领域驱动设计
考虑到团队非敏捷型组织架构,又缺少领域专家,因此没有采用
高峰期性能瓶颈问题
大促和推广期间,特别是爆款抢购时的流量可能会触发限流,导致部分用户被拒之门外。因为无法准确预估流量,难以提前扩容。
可以通过主动降级方案增加并发量,比如同步入库切为异步入库、db查询转为cache查询、只能查到最近半年的订单等。
考虑到业务复杂度和数据量级还处在初期,团队规模也难以支撑,这些设计有远期计划,但暂时还没做。(架构的合适性原则,杀鸡用牛刀,你愿意也行)。
我们在设计系统时并没有一味追求前沿技术和思想,面对问题时也不是直接采用业界主流的解决方案,而是根据团队和系统的实际状况来选取最合适的办法。好的系统不是在一开始就被大牛设计出来的,而是随着业务的发展和演进逐渐被迭代出来的。
目前交易平台已上线一年多,接入了三个业务方,系统运行平稳,公司内有交易/商品/库存等需求的新业务,以及存量业务在遇到系统瓶颈需要升级时,都可以复用这块能力。
上游业务方数量的增加和版本的迭代,对平台系统的需求源源不断,平台的功能得到逐渐完善,架构也在不断演进,我们正在将履约模块从交易平台中剥离出来,进一步解耦,为业务持续发展做好储备。
本文主要介绍在Node.js应用中, 如何用全链路信息存储技术把全链路追踪数据存储起来,并进行相应的展示,最终实现基于业界通用 OpenTracing 标准的 Zipkin 的 Node.js 方案。
经过几年的平台建设,vivo监控平台产品矩阵日趋完善,在vivo终端庞大的用户群体下,承载业务运行的服务数量众多,监控服务体系是业务可用性保障的重要一环,监控产品全场景覆盖生产环境各个环节。