作者:vivo 互联网数据分析团队 - Li Bingchao
AB实验是业务不断迭代、更新时最高效的验证方法之一;但在进行AB实验效果评估时需要特别关注“用户不均匀”的问题,稍不注意,产出的研究结论就可能谬以千里,给业务决策带来极大风险。因此我们游戏业务针对该问题,借助霍金实验团队已经实现的分层抽样(协变量平衡算法)能力,探究出一套基于用户分层逻辑的“事前用户分层”方案,和霍金实验平台项目团队、版本发布项目团队共同协作推进方案落地,提升游戏业务AB实验的用户均匀性。本文会基于实际应用案例,来给大家仔细阐述相关方法模型的思考过程,实现原理,应用结果,希望能够帮助大家在各自领域中解决用户不均匀问题时带来参考和启发。
业务通过不断迭代更新来持续进步,AB实验是最高效的迭代验证方法之一,分析师则通过研究优化实验方案,评估业务实验效果来展现数据价值。这也是数据分析师的核心工作职责之一;这就要求实验方案和效果评估具备极高的科学性与准确性,但是在实际工作中,因为用户不均匀问题的存在,会直接影响到分析师产出结果的准确性,进而影响产品相关决策。
过去的几年里,游戏业务的分析师团队不断探索和研究AB实验中用户不均匀问题的解决方案,目前已经较好地解决了游戏业务中的此类问题。本文首先以用户不均匀的概念和影响为铺垫,接着以解决方案为主线阐述游戏分析师团队在解决AB实验中用户不均匀问题的实践成果,并展望未来。
基于AB实验逻辑的业务迭代有一个至关重要的前提假设:实验的两个组除了产品本身发生改动的唯一变量外,其他相关因素,尤其是用户本身的特征都是一致的,即两个人群的用户属性分布是完全均匀的。
业务AB实验遇到的用户不均匀问题是指,用来评估业务效果的实验组、对照组两个人群集,由于人群划分方式(用户标识加密尾号分组等)、人群量级、或者观测指标本身特殊性等原因,导致两个人群集在核心效果评估指标的先验分布存在较大差异:
【人群划分方式】:有些业务直接用手机标识进行人群划分,但手机标识和手机型号批次等相关,不具有充分的随机性;
【人群量级】:人群量级过小时,抽样无法保证不同特征用户完全随机,导致用户分布不均;
【指标特殊性】:游戏付费指标具备高稀疏性、非正态分布、非连续等特点,常规的抽样方式难以保证好的均匀性。
如下图所示(不同颜色代表不同先验特征的用户):
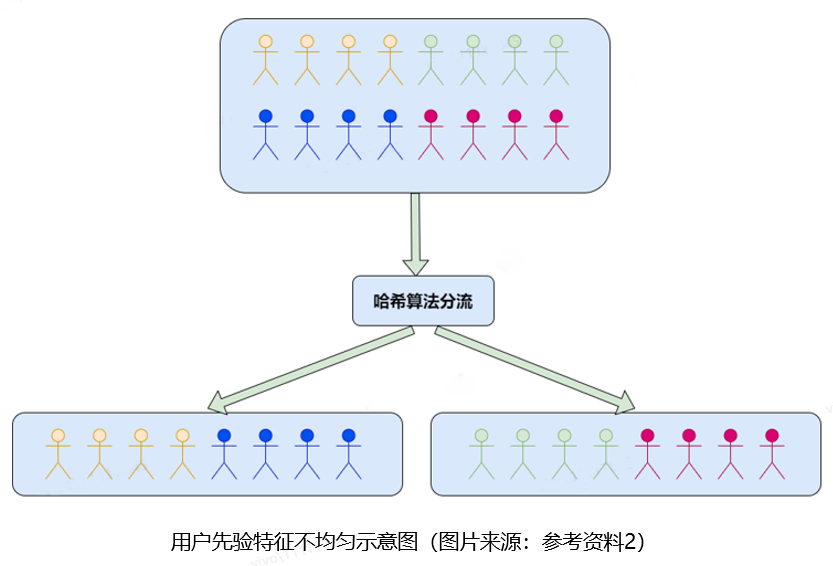
再简单举个例子,比如实验组人群A相较于对照组人群B因为先验特征分布的差异,导致在业务的核心指标上,先验的历史表现即为A>B;这就导致利用两个人群集进行试验后,在业务效果评估时,如果人群A的某个指标>人群B,那么是因为业务策略带来的提升还是历史用户本身的差异呢?这就陷入了业务决策的困境。
游戏中心业务迭代中使用AB实验的场景主要为,版本迭代灰度AB实验,以及中心业务策略优化AB实验;在过往的AB实验过程中,两种场景都多次遇到过用户不均匀的问题,但两个场景的业务目的存在差异,故面临的用户不均匀问题也有区别。下面我们详细介绍一下两种场景的异同点。
游戏中心版本迭代时,主要观测的指标为用户在中心活跃、游戏下载等指标;使用的人群划分方法为:利用对手机标识进行加密处理后的尾号进行分组,这种方法在大流量的情况下对于用户均匀性能保持不错的效果;但是版本迭代的关键特点就是小流量快速迭代,所以在小流量下就会导致不同活跃下载表现的用户在实验组、对照组中数量存在差异,进而导致两个人群在一些核心观测指标上存在不均匀现象,影响最终的版本放量决策。
游戏业务作为公司的主要创收业务,游戏中心策略实验时,除了观测活跃、下载指标之外,还需要观测游戏后向的收入指标变化;前面也提到活跃下载指标的均匀性在大流量下是可以保证的,而策略实验时的流量一般是较大的,历史数据也证明在策略实验的流量下,活跃分发指标的均匀性是可以保证的。
但游戏收入作为一种特殊的商业模式,与用户活跃、游戏下载存在较大差异,本身具有以下特殊性:
【付费用户规模有限】:整体游戏活跃用户中,付费用户规模有限,随机抽取两组用户中,即使活跃用户量级一致,但付费用户量级本身可能存在较大差异,尤其是高付费用户在两组中分布存在差异。
【收入分布非正态】:一定周期内游戏用户付费分布范围极大,但是大多数用户付费不高,所以几个极值高付费用户的差异就能够对整体收入结果产生较大影响。
【游戏付费水平不固定】:用户游戏付费是和游戏强相关的,故用户的付费情况除了自身因素外,还和用户最近玩的游戏有关,即用户付费水平是一个不断变化的过程。
【高付费值非连续分布】:高付费用户的定义是一个范围的概念,而且高付费的用户是有限的,所以具体高付费值并不是连续的,高付费之间也会存在明显差异,这个差异放到整体上时依然会产生较大的影响。
所以即使在中心策略实验场景较大的流量下,依然还是无法保证实验时收入指标的均匀性,原因可以归为两方面:
实验组和对照组中高、低付费用户的分布不均匀,付费用户量级存在较大差别。
高付费用户的付费值非连续分布,即使付费用户在各组分布均匀,但付费值依然存在一定差距。
vivo游戏中心作为公司专业的游戏分发平台,为了更好的服务好游戏中心用户,需要不断地对游戏中心产品进行优化迭代。AB实验作为主要的效果验证方式,通过对比业务关注的核心指标,选择最优的功能或版本进行全量,但用户不均匀问题会对整个流程闭环产生比较大的影响,主要包括以下几个方面:
1、影响业务数据的可解释性,导致业务效果的结论偏差
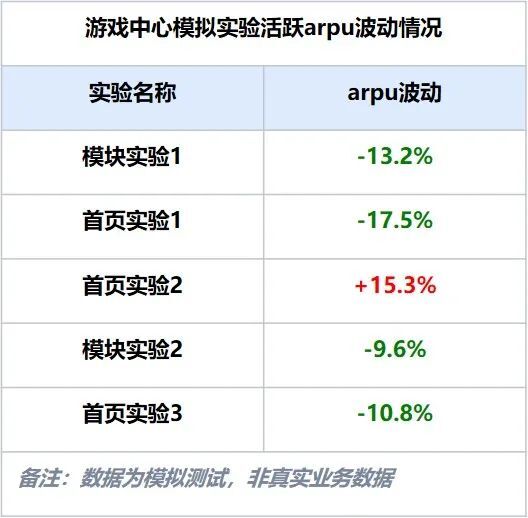
由下表可见,游戏中心历史一些业务策略实验中,策略对于收入项指标本无直接影响,但整个收入指标的波动均在10%以上;在此情况下,已经完全无法根据实验收入数据来评估业务策略对于收入的影响情况。
arpu=实验周期内活跃用户游戏下载后付费/活跃用户
2、带来业务策略放量错误的风险
这里主要存在的风险在于效果负向策略被放量、效果正向策略无法及时放量。
3、导致灰度发版的无效率高,异常排查浪费大量人力
游戏中心灰度发版中,一年有8-10次的版本异常是由用户不均匀导致的,而且单次异常排查需要耗费各方人力共5人日,全年版本异常排查累计浪费人力40人日+/年。
所以如何科学合理的解决游戏中心AB实验效果评估中的用户不均匀问题,对于整个游戏中心业务效果评估的发展具有重要意义。
AB实验中的用户不均匀问题是数据分析师进行实验效果评估时一直都面临的问题;过往几年里,针对如何更合理,更高效的解决该问题,准确评估实验效果,游戏数据分析组的同事研究尝试了多种不同的解决方案:
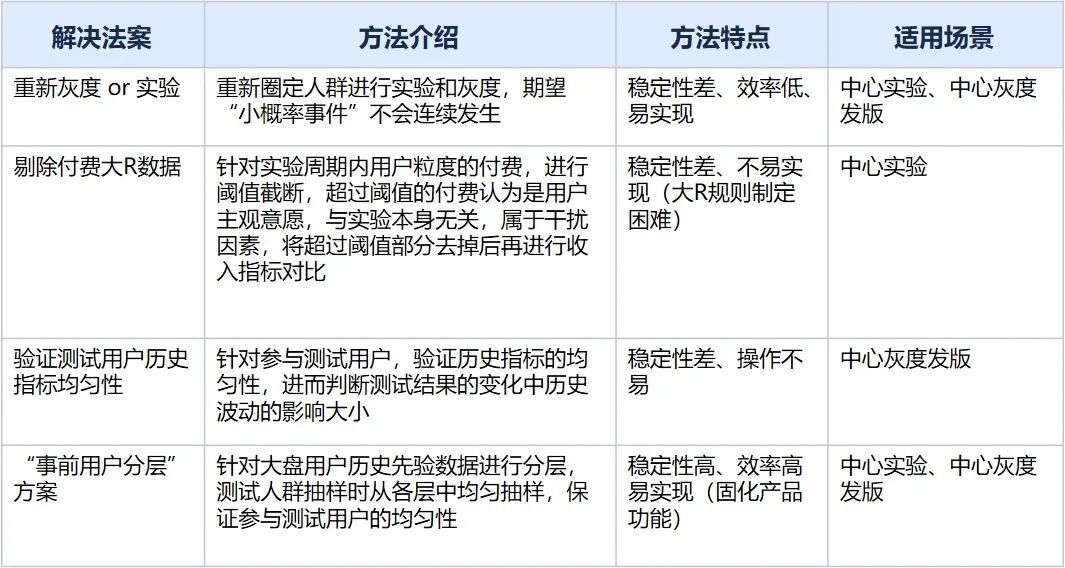
从上述几个方案对比中可以看出,基于用户分层逻辑的“事前用户分层模型”是现阶段最科学、合理且效果稳定的解决方案。
本部分主要针对“事前用户分层”模型进行介绍,同时包含模型的设计,产品化实现,以及在游戏中心业务中的实际运用效果,便于大家直观了解模型的逻辑和效果。
如前面用户不均匀介绍部分所述,虽然中心版本灰度场景和中心策略优化场景的AB实验都面临着用户不均匀问题,但两个场景面临的不均匀问题存在差别;所以我们针对这两个场景,基于用户分层逻辑分别搭建针对分发指标和收入指标的分层模型,实验人群抽样时从不同用户分层中抽取同样数量的用户进入实验组和对照组,以期解决业务效果评估中的用户不均匀问题。
常规分层抽样逻辑:假设大盘活跃用户为N,分层后第i层大盘活跃用户为Ni,实验时各组实验抽样的流量为n,则实验组中第i层的抽样量级应该为:
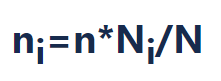
中心策略AB实验时业务核心关注的付费指标中受用户不均匀影响的主要是活跃用户arpu,故针对该指标的定义,选取部分中间变量作为用户分层的依据,然后根据这些指标在中心活跃用户大盘中的表现,先按照单一指标分组,然后多个指标交叉组合形成最终的分层方案。

针对中心版本灰度实验时业务核心关注且受用户不均匀影响的分发指标,选取部分中间变量作为用户分层的依据;然后与收入分层模型采取一样的方法形成最终的分层方案。

数据侧搭建完成用户分层模型后,想要实现在实验和灰度时依赖于分层模型进行分流抽样,需要借助产品平台的功能;于是我们和霍金实验平台、以及版本发布系统合作,由霍金和版本发布系统同事开发相关功能将我们搭建好的用户分层模型分别接入霍金实验平台和版本发布系统,实现在实验和版本灰度的用户分流时基于用户分层逻辑进行,保证实验和版本灰度时各个人群组之间的用户均匀性,提升后向效果评估的科学性和准确性。
具体分流逻辑示意图如下:(图中四个不同颜色代表不同的特征分层人群)
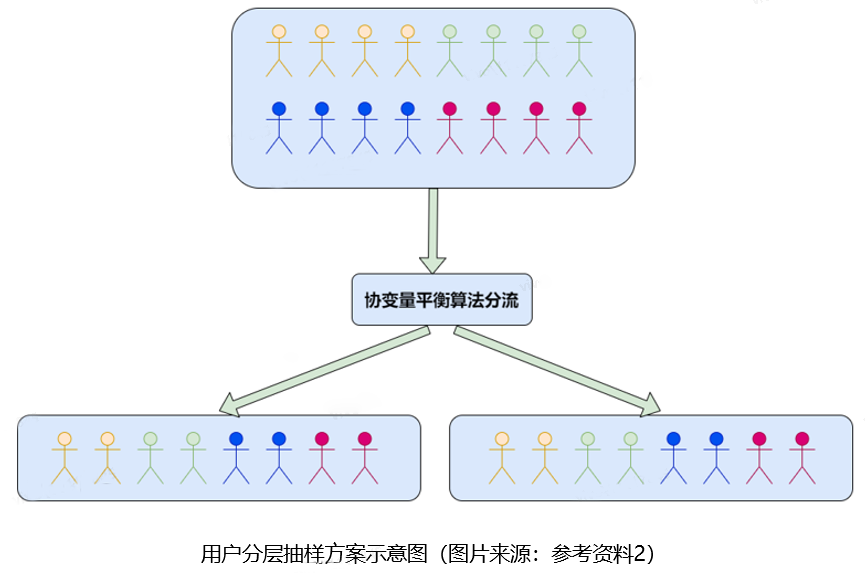
具体产品平台功能实现方式详见:参考资料[2]
霍金实验平台和版本发布系统相关功能上线后,数据分析侧开展了对应平台的AA实验,验证用户分层逻辑对于用户不均匀问题的解决效果是否达到预期水平。
用户分层模型在不影响原有分发指标均匀性的前提下,能够大幅提升中心实验收入数据的均匀性。
分发均匀性:两种分流逻辑下,分发相关指标波动均不显著,但用户分层逻辑下指标波动绝对值远小于hash分流逻辑。
hash分组逻辑下,收入arpu1波动11.6%;但用户分层抽样逻辑下,两个实验组收入arpu1波动分别为4.8%和1.9%,收入arpu2波动分别为3.3%和1.5%,均匀性大幅提升。
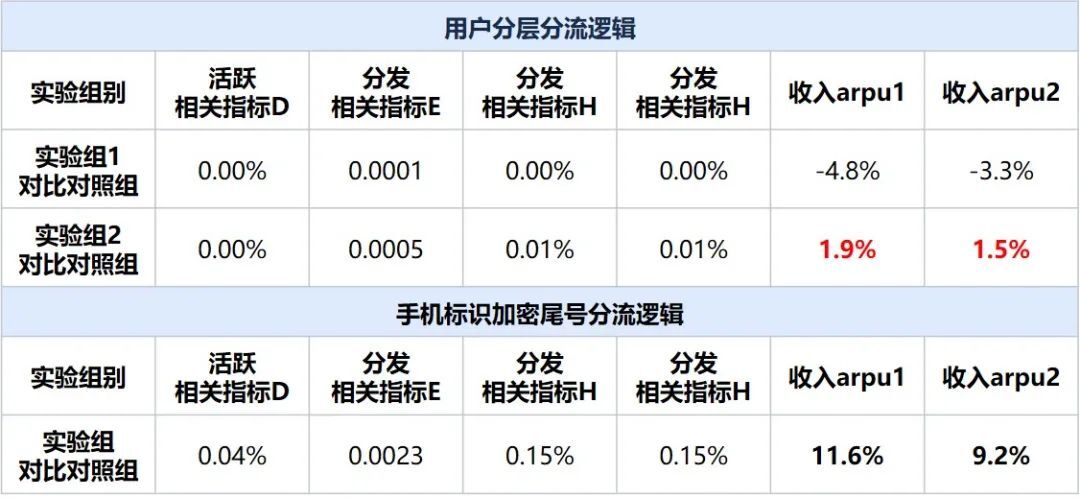
备注:收入指标及活跃相关指标对比计算相对变化值;分发指标对比计算绝对变化值;收入arpu1、2代表不同的收入计算逻辑。
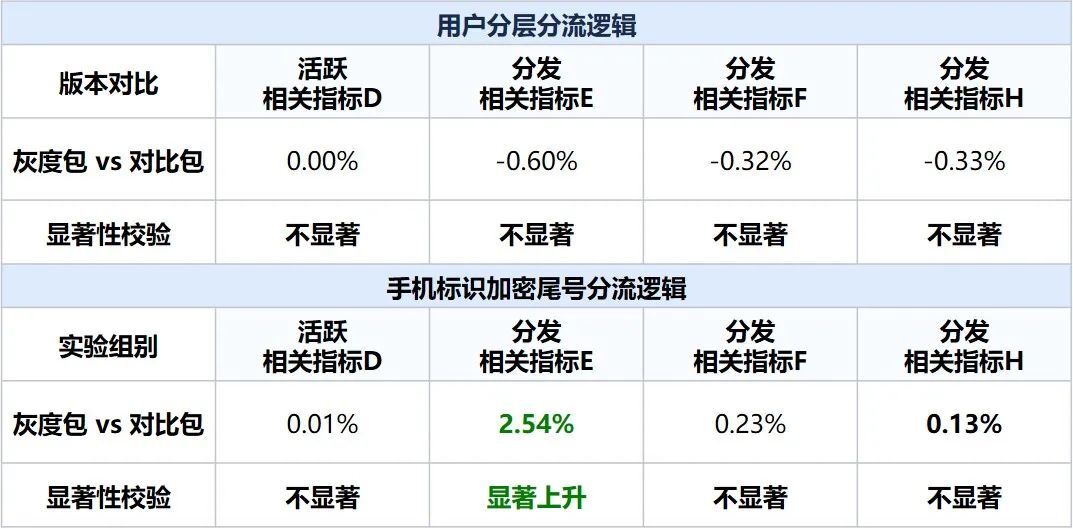
用户分层模型在分发指标的均匀性上,优于原有的手机标识加密尾号分流方式。
分发均匀性:用户分层逻辑下,各个分发指标均波动不显著;但手机标识加密尾号分流逻辑下,游戏分发相关指标E显著变化,即在该指标上存在用户不均匀。
“事前用户分层”模型在游戏中心业务实验和灰度发版中上线使用后,能够带来以下几方面的显著收益:
【灰度有效发版率显著提升9pt】:分层逻辑上线后,游戏中心有效灰度发版(用户均匀)的概率从86% 提升到95%,不均匀次数从10次/年,下降到2~3次/年(近半年仅有1次)。
【节省异常排查人力35人日/年】:发版异常减少7次/年,单次异常排查需各方共5人日,共节省版本异常排查人力35人日/年。
【正向策略实验提前全量带来中心年收入+0.2%】:用户分层逻辑上线后,正向策略提前得出结论全量,能够带来游戏中心年游戏分发+0.1%,年游戏收入+0.2%。
【负向策略实验及时下线减少收入损失】:提升实验负向时的判断及时性和准确性,降低负向实验长期观察带来的收入损失,约占中心年收入的0.1%。
对于AB实验中面临的用户不均匀问题,我们借鉴过往经验,经过不断尝试和探索,基于用户分层的逻辑开发了“事前用户分层”模型,并在霍金项目团队和版本发布系统项目团队的大力支持下,对不同场景进行差异化处理,在解决游戏中心AB实验中的用户不均匀问题中取得了较好效果;在游戏中心版本灰度场景中,事前用户分层方案已基本解决了用户不均匀问题;但在中心策略实验中,由于游戏收入数据的特殊性,用户分层方案能够解决高、低付费用户在实验组中分布不均的问题;但并不能完全解决高付费值非连续的问题,故收入的波动依然在1%~2%,但已经远低于原有分流方式下的收入波动幅度。
此外,现阶段采用的“事前用户分层”方案能够大幅提升用户的均匀性概率,并不能完全杜绝用户不均匀问题;一方面原因是对业务指标的分层逻辑依赖于工作者的经验判断,但人工分层的逻辑存在较大的主观性;另一方面原因是选取的指标较少,依赖信息不够全面;后续我们也会不断尝试探索,卷入更多的指标信息,同时将机器学习等模型运用到用户分层体系搭建中,以求进一步解决游戏业务中用户的均匀性问题。
最后希望本文能为不同业务解决AB实验时面临的用户不均匀问题带来参考和启发。
参考文献:
茆诗松, 王静龙, 濮晓龙. 《高等数理统计(第二版)》
vivo互联网技术《vivo霍金实验平台设计与实践-平台产品系列02》
本文会基于实际应用案例,来给大家仔细阐述AB实验相关方法模型的思考过程,实现原理,应用结果,希望能够帮助大家在各自领域中解决用户不均匀问题时带来参考和启发。