作者:vivo 互联网服务器团队- Wang Shimin
网络质量监测中心是一个用于数据中心网络延迟测量和分析的大型系统。通过部署在服务器上的Agent发起5次ICMP Ping以获取端到端之间的网络延迟和丢包率并推送到存储与分析模块进行聚合和分析与存储。控制器负责分发PingList并通过数据中心内部消息通道将PingList下发至每台服务器上的Agent,而PingList就是每个Agent需要发起Ping的目标服务器列表。
数据中心的建设是一个从无到有从小到大的过程,在数据中心建设初期,由于量级很小,我们想要了解网络状况是比较轻松的,在两台服务器上获取其网络延迟简直轻而易举,输入Ping命令和IP地址便可以随时获取网络延迟。然而,当业务滚雪球式的增长,数据中心随之扩容或新建,服务器数量达千级、万级、十万级甚至更多时,想要随时获取机房各链路的网络延迟以定位网络故障原因就变得十分具有挑战性。我们开始思考如何建立一个用于大规模数据中心网络延迟测量和分析的系统,以便于更高效、快捷的维护数据中心。
经典的数据中心网络架构有三层,分为核心层(网络的高速交换主干)、汇聚层(提供基于策略的连接)、接入层 (将工作站接入网络),在庞大的数据中心网络中,难免在某些时刻某些业务出现问题。那么如何确定问题是否是网络问题?如何定位一个网络故障?如何提前预测网络故障,确保数据中心基础网络的可用性(SLA)不受影响?由于分布式系统庞大、可扩展、依赖多的性质,许多故障显示为“网络”问题,例如,某些组件故障,端到端对接时由于某一端CPU负载突然增加导致响应延迟,或者网络拥塞导致的排队延迟,又或者数据包丢失也会增加用户感知的网络延迟。其中一部分问题其实并不是所谓的“网络”问题,然而要判断这些问题是否是由网络故障引起的,或者定位网络故障的原因,是一个费时费力的过程。 为了应对这些挑战和简化网络运维繁复的工作,我们的网络质量监测中心就应运而生。
网络质量监测中心是一个用于数据中心网络延迟测量和分析的大型系统。通过部署在服务器上的Agent发起5次ICMP Ping以获取端到端之间的网络延迟和丢包率并推送到存储与分析模块进行聚合和分析与存储。控制器负责分发PingList(需要相互执行Ping的IP列表)并通过数据中心内部消息通道将PingList下发至每台服务器上的Agent,而PingList就是每个Agent需要发起Ping的目标服务器列表。
Agent是整个项目的数据采集器,负责接收来自控制器下发的PingList,PingList中有该Agent需要发出Ping目标的IP地址,最后将探测数据上报存储与分析模块。Agent要覆盖所有机房的绝大多数物理机,才能保证探测数据汇总后的有效性和真实性,所以,在Agent对PingList中的目标IP进行Ping操作时,Agent所占用的CPU资源不能超过5%,是Agent设计时要保证的核心要点。Agent由机房内部消息通道统一分发部署、更新、启动和停止。
控制器是整个网络质量监测中心的任务调度器,决定了服务器应该如何相互探测,负责PingList生成算法与下发通知,以及网络拓扑的定时更新。
存储与分析模块负责收集Agent上报的ICMP Ping数据并存储,同时负责数据的聚合与分析以及告警输出,根据不同条件对数据进行各种维度的可视化。
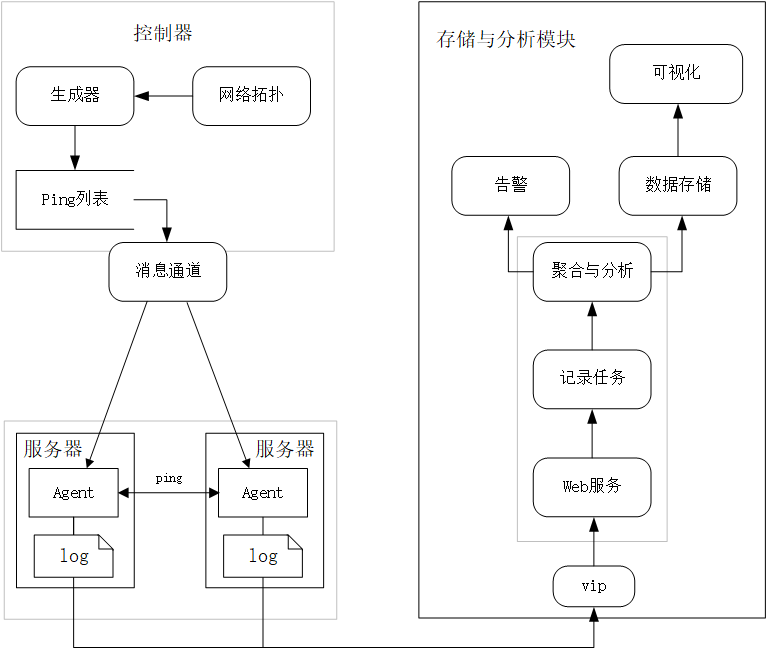
图1 网络质量监测中心架构
由于Agent运行在所有的服务器上,而我们关注的维度其实是ToR(Top of Rack),所以服务器维度完整图既不是必要的也不是可行的,因为单台服务器需要探测n-1台服务器(n是参与探测的服务器数量),这样会产生非常庞大且冗余度非常高的探测数据。在数据中心中,服务器可以达到数百上千个。此外,服务器维度完整图不是必需的,因为数十台服务器通过相同的ToR交换机连接到其他ToR至服务器。因此控制器为了避免过量开销,调整了原n²-n的Ping策略。
在ToR内部,随机选取两台服务器互相Ping。
在ToR之间,则每个ToR选取两台服务器Ping其它ToR的服务器,保证每个ToR下至少有一台机器发出或接收Ping。
在数据中心之间,则选择不同的数据中心的几个不同的核心ToR下的服务器来相互发起Ping。
控制器由Timer,Watcher,Producer,Consumer和Topology Keeper构成。
Timer是个定时器,负责在指定时间对Watcher发出更新网络拓扑的指令或更新PingList的指令;
Watcher接收到Timer的更新PingList指令后,立即查找各数据中心的网络拓扑元数据,分数据中心对Producer发出生成新PingList指令;
Producer接收到Watcher的网络拓扑数据后,根据网络拓扑中各层级的ToR给予不同的权重,根据此权重以随机抽取的方式选取其下辖的服务器,最终组成PingList并交由Consumer下发;
Consumer负责接收Producer生成的PingList并对接数据中心内部消息通道,经由消息通道将PingList下发至服务器上的Agent;
Topology Keeper通过SNMP(Simple Network Management Protocol)自主探寻网络拓扑,为网络拓扑展示提供数据源。
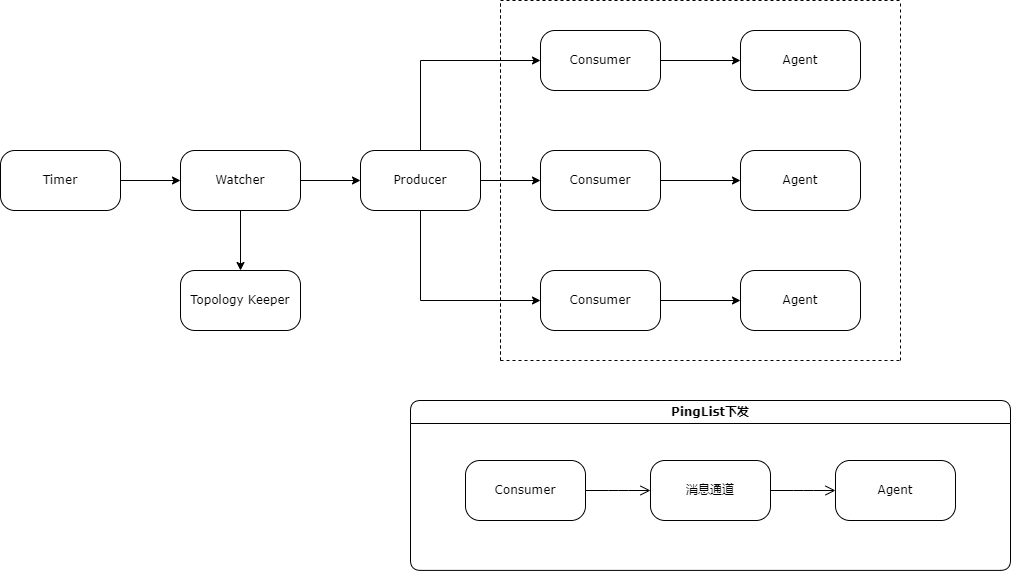
图2 网络质量监测中心控制器
存储与分析模块将Agent上报的所有Ping数据保存,随后根据10分钟粒度、一小时粒度的时间范围对数据进行汇聚与分析,根据分析结果,对异常链路进行持续跟踪。
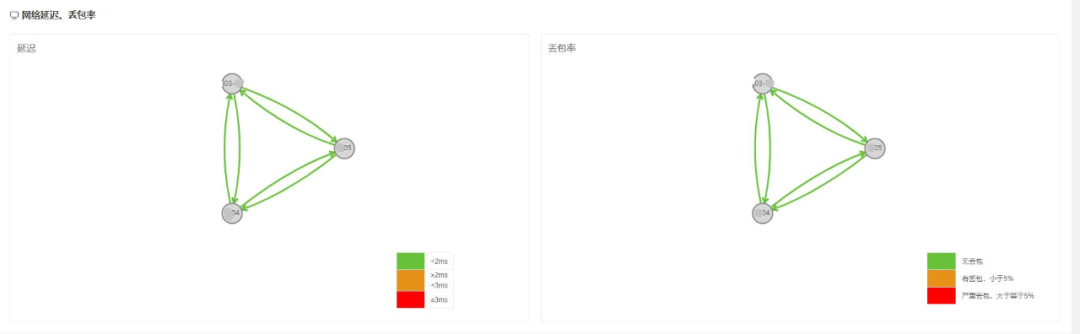
图3 数据中心维度延迟与丢包率总览
图3显示了多个数据中心之间的实时网络延迟以及丢包率的总览,数据延迟为4分钟。由于数据中心之间的相互探测是由核心交换机下辖服务器发起的,在某些时刻如果数据中心之间的网络延迟陡增,则可以迅速的定位探测端与被探测端的链路,极大的缩小问题定位的范围。

图4 实时网络延迟矩阵图
图4反应了同机房不同Pod(规划的一个网络区域)间的实时延迟分布信息,我们很快就能发现,其中一组ToR出现延迟问题,那么很有可能双向链路都会反应高延迟情况,同样也可能在丢包率的矩阵中反应出来。图中的每一个点都包含了一组ToR的数据,若以ToR为单位画点阵图,则会导致数据量过于庞大而无法使用。而实际使用中,完整的ToR粒度的矩阵图也不是必须的,所以如何选择汇聚维度成为一个问题。
在我们的设计中,只有服务器会执行Ping操作,即服务器是数据源,ToR则可以看成一个虚拟节点。一个数据中心拥有数个Pod,如果矩阵图以Pod维度聚合那么显然我们得不到想要的效果,一个Pod下辖制若干ToR,我们的矩阵图中每个点都含有最新的延迟与掉包数据,若以ToR为单位,则矩阵图所承载的数据量过于庞大而导致整个矩阵的边长远超页面的边界,影响可视化的预期效果,所以矩阵图既不能以Pod维度聚合,也不能以ToR作为单位,最后我们采取了折中方案,在Pod与ToR之间加了一层组级关系,以这层关系为维度进行矩阵图的绘制,初步达到了项目设计目标。
如此一来,绘制矩阵图便可达到预期效果,当发生网络故障时,查看矩阵图可以辅助快速定位出现问题的服务是否是由网络延迟导致的。
图5是同机房当前延迟top趋势图,时间粒度是2分钟,反应了当前机房中延迟最大的链路在过去的一段时间里的网络延迟情况。
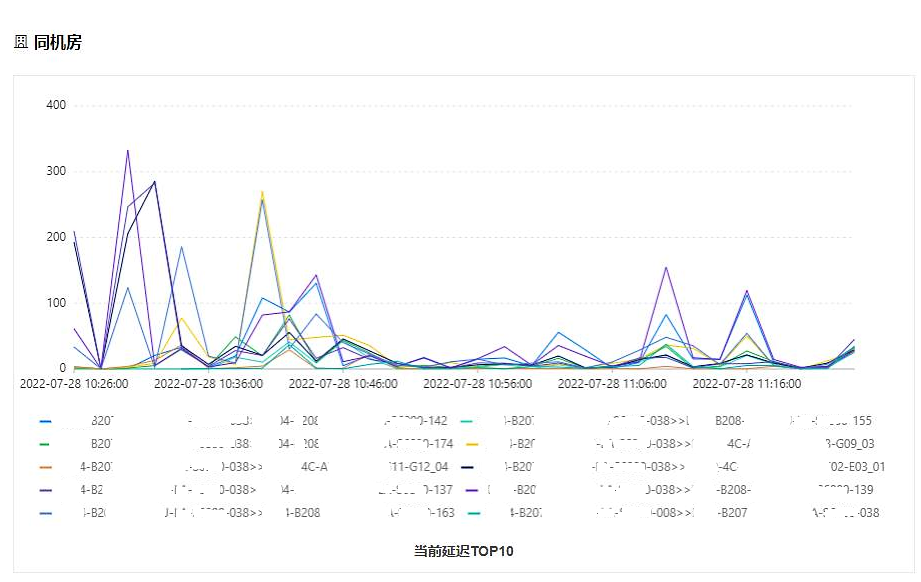
图5 数据中心内当前延迟top10趋势图
从项目上线开始,Agent的灰度持续进行,最初制定的目标是灰度覆盖每个机房的所有物理机,但在实际执行过程中,总会遇到各种各样的问题,比如负载均衡集群的流程承载节点所在的服务器由于常年处于满负载状态,Agent执行的Ping延迟总是非常高,探测到的数据并无实际意义。又如大数据和部分隔离区的服务器并不适合Agent的部署与执行。此时已经限制了网络质量监测中心数据的覆盖范围,如何优化选择服务器算法让探测的Ping数据更具有代表性和真实性是目前面临的第一个挑战。
Agent将延迟数据通过标准Web API上报给存储与分析模块,因为Agent持续在线的性质,这种方式首先面临的是持续高并发以及数据消费速度瓶颈,随着数据中心规模持续扩大,瓶颈会愈发明显。
控制器和存储与分析模块工作在应用层,这就意味着若网络质量监测中心的组件依赖出现问题,那么其所有工作都将瘫痪。
网络质量监测中心尽管目前能收集到ICMP Ping数据,但无法准确定位网络故障链路,在数据可视化方面还需要增加可视化方向与维度以充分使用这些数据。
网络质量监测中心优化的空间还很大,后续将在技术架构以及功能场景方面着重下功夫。
在功能支撑方面,可以丰富探测场景和优化数据源,目前仅支持ICMP Ping场景,后续的优化中,需要强化Agent以支撑UDP,TCP等不同场景。完善Agent主动上报和健康检查机制,及时更新PingList,保证数据源的实时性与可靠性。生成PingList的算法目前以随机抽取为主,缺乏针对性,后续将对服务器和网络设备元数据进行维护以区分高优先级和低优先级ToR,为高优先级和低优先级分类生成PingList。完善监控指标及其阈值配置,差异化设置告警规则,多模式多功能多维度的图表处理等。
在技术架构方面,由于接收数据的分析服务端并发压力很大,为应对未来数据多样性带来的更高的并发量,需要优化服务部署方式,调整Agent上报数据的处理机制,以数据中心为单位建立消息管道接收Agent的上报数据增加稳定性。为了应对数据快速增长,将对当前技术架构进行整体升级,提升服务性能和吞吐量。
网络链路质量监测求索之路漫漫,希望通过不断的打磨与学习完善我们的项目,力求网络质量监测中心在网络故障自主发现、故障预警以及故障定位的征途上不断的成长壮大,最终能够持续提高网络质量。