编者按:本内容源自葡萄城客户——政采云前端技术团队。政采云公司以全球领先的云计算、大数据、人工智能等数字技术为基础,搭建了全国首个政府采购云服务平台——政采云平台,目前该平台已成为行业内服务范围最广、用户数量最多、交易最活跃的跨区域、跨层级、跨领域的一体化采购云服务平台。
数据可视化包含三个分支:科学可视化、信息可视化、可视分析。
1、科学可视化主要关注的是三维现象的可视化,如建筑学、气象学、医学或生物学方面的各种系统。重点在于对体、面以及光源等等的逼真渲染,或许甚至还包括某种动态成分。
2、信息可视化是一种将数据与设计结合起来的图片,有利于个人或组织简短有效地向受众传播信息的数据表现形式。
3、可视分析学被定义为由可视交互界面为基础的分析推理科学,将图形学、数据挖掘、人机交互等技术融合在一起,形成人脑智能和机器智能优势互补和相互提升。
可视化分析中可视化报表是重中之重,把大量的数据快速的展示出来,并且灵活的进行数据操作,其中操作包括数据的筛选、关联、联动、钻取,文案的查询,替换、样式设置,条件格式的注入实现多色阶、图标集、数据条、重复值,以及公式的插入,跨表联动等。SpreadJS 在解决可视化分析报表中最为突出,下面我们只针对可视化分析中 SpreadJS 所扮演色做探讨。
互联网电商服务业行业,平时会处理大量商业信息和用户信息,客服和数据分析师,是报表主要用户人员。
客服平时每天都会处理大量的工单填报、客诉登记、第三方平台原始数据的导入、统计汇总、审核审批、电签、分发等工作。平时大部分工作信息的载体都是 Excel,每天服务器需要处理海量的文档,由于 Excel 文档本身数据难以提取入库,模板更新时也不方便第一时间分发到操作员处,难以整合到 Web 页面里等问题。
数据分析师需要拿到数据进行汇总,算出各个商品品牌的销售额,最大值、最小值、平均值等,标识出有价值的数据。抓取有效数据,制作成报表给 boss。
针对以上的场景,报表可视化可以总结出以下几个难点:
1. 并发
公司客服人数众多,几千人同时在线重度操作,业务流转周期短、数据量大,所以对服务端并发性能消耗是很大的。可以在后台用 Apache POI 来提取和修改 Excel 数据、并执行其中的公式计算等。这样会遇到两个性能瓶颈:
1)需要频繁地上传、下载文档,服务器带宽承受了很大的压力;
2)所有 Excel 解析、提取的操作都在服务器端,频繁的 IO 操作让服务器不堪重负。
以上两个性能点,在目前的架构下很难突破,这也是重构项目时最具挑战性的需求点之一。当然硬堆服务器配置也是一个解决方案,但无法解决其它的一些问题,并且也会带来运维的压力。
2. 对 Excel 操作和兼容性要求较高
新系统如果不能让大家快速上手使用,以这个项目用户的体量,培训成本将无法承受。而且要能够直接导入已有的 Excel 报表模板,否则再次开发或设计所有 Excel 报表也是难以接受的。
3. 报表格式灵活多变
针对不同的业务场景,报表的模版也是千变万化。因此不需要研发的介入,操作员的设计和填报都可以在页面上完成显得尤为重要。
4. 支持公式计算
由于涉及到商品、订单、成本核算、财务统计等模块,对计算公式的种类和性能要求较高。
5. 工作流中的数据文档
以前系统的工作流,涉及到 Excel 报表时,要么数据会先在服务端和 Excel 模板进行拼装,要么系统根据路径找到文件服务器的 Excel 文件,然后流转到对应环节。一些新的业务模块,甚至还只能用邮件进行文件传输。
这个过程会产生大量的文件,对文件服务器的带来了很大压力,后台也不得不定期做批量的数据拆分和维护。这次升级系统需要解决这个问题。
首先,选型的第一步就是搞清楚市面上具体有哪些产品供我们选择,对于目前市面上能集成到系统中,支持这种在线表格文档编辑的产品有不少,大体我把他们分了两类。
1. 云文档类型产品
这种产品有很多,类似 WPS、石墨文档、office online。它们本身具备较高的完成度,已经帮用户实现了包括在线协同内的几乎所有功能,甚至也支持一定程度的二次开发而且可以私有化部署。但问题在于通常这类产品封闭性比较强,二次定制开发还是相对比较困难,且不够轻量。授权方式也多以按时间、按并发量、用户数量等方式授权,价格昂贵,不是很适合我们的需要。
2. 控件类型产品
像 LuckySheet、Handsontable、SpreadJS 这种就是标准的控件了,它们都是纯前端表格控件,都支持 Excel 的功能特性和 json 数据绑定。
LuckySheet 是国内的MIT开源软件,可以拿来商用。但在我调研时它才刚上线 1、2 个月,并且不像 React 这种有某个大厂来背书,所以不可能拿来用到我们的正式项目里。截止目前已经过去了 1 年,陆续推出了 QQ 群、论坛等交流平台,但仍显薄弱。
Handsontable 是国外的一个商业表格控件,据说二次开发坑较多,但对我们来说最大的问题是它没有中文支持团队。
SpreadJS 是葡萄城公司的商业Excel表格控件,有趣的是我发现在 V2EX 的 LuckySheet 下方评论区中,LuckySheet 的作者也说 SpreadJS 是行业标杆。它支持导入包括公式、图表、样式、条件格式在内的绝大部分 Excel 特性(不支持宏)。并且最惊喜的是,它的操作界面是一个完整的 Excel 界面,完全纯 JS 开发的,用 json 进行模板和数据交互。同时 SpreadJS 也有对应的售后支持团队,技术问题可以工作日期间随时电话、论坛交流,相关的资料包括视频、文档、示例、API 手册也都非常丰富,甚至还可以请他们的技术顾问来公司培训。对于像我们这种工期短、开发任务比较繁重的项目组,确实能节约大量的精力,降低了风险。
图片来源:SpreadJS在线Excel编辑器
那么什么是控件?为什么要用控件?
引用维基百科
在计算机编程当中,控件(或部件,widget或control)是一种图形用户界面元素,其显示的信息排列可由用户改变,例如视窗或文本框。控件定义的特点是为给定数据的直接操作(direct manipulation)提供单独的互动点。控件是一种基本的可视构件块,包含在应用程序中,控制着该程序处理的所有数据以及关于这些数据的交互操作。
按照我自己理解,控件就是只提供了基本功能,支持二次开发的功能模块。控件相对依赖更轻,可塑性更好,并且也有对应的开发文档和 API,是面向开发者的基础功能包,便于按需求来定制功能。
由于 SpreadJS 是数据和模板分离的设计,填报人员只需要在页面上完成填报。提交时可以只提交填报好的数据 json 即可,服务器再也不用集中解析所有Excel 文件了。带宽消耗也直接节约了一半。
在内部试用时,财务和客服的小姐姐们反馈,使用体验跟 Excel 几乎完全一样,不需要再特意培训。而且我们自己的大量 Excel 报表可以直接导入进去(二次开发后也可以实现批量和远程导入),包括图表、公式、表格样式等等一系列元素都可以直接导入线上操作。
设计人员可以直接在线设计,或者把 Excel 设计好的报表,拿到 Web 端,做好数据绑定,提交保存成 json 格式即可(Spread JS 的 ssjson 格式包括 Excel 文档的所有信息)
支持了 450 多种( Excel 一共 480 多种)公式,还可以自己开发扩展自定义公式,对财务也够用了。同时还支持所有 Excel 的引用操作,比如跨 sheet 引用、绝对引用、函数命名信息之类。
基本脱离了对文件的依赖,所有流程状态和依赖的数据都可以在数据库中记录,文件服务器只需要保存少量的模板文档即可(其实模板数量不大时可以直接放到数据库里,不过我们有现成的文件服务器)。这里节约了我们 90% 文件服务器的空间开销,运维的小伙伴半夜都要笑醒。
重点来了,其实最让我这个前端开发者感兴趣的就是 SpreadJS 的一些底层设计、以及对内存、性能平衡性的优化。对此我做了很多调研和学习,好在这方面资料不难找,常常可以在葡萄城官方论坛的公开课版块( https://gcdn.grapecity.com.cn/forum.php?mod=forumdisplay&fid=225&filter=typeid&typeid=274&fileGuid=QKgTJRrrCD96PXwh)
性能肯定是每个深度表格控件用户最担心的问题。我们的数据量常常达到好几千条,而且 Excel 不方便分页(涉及前端的公式计算汇总),所以选型期间很担心。后来发现想多了,SpreadJS 可以轻松加载 50 万条数据加载耗时 200 ms左右(官网性能演示示例只能加载 5 万,我们自己扒下来测的 50 万)。后来深入了解才知道,解决这个问题,他们的思路是这样的:
用 Canvas 渲染表格部分,并且只渲染用户看到的部分内容,这就实现了加载 1000 行和加载 100000 行数据速度都很快,性能相差不大的现象。
而 Double buffering 是为了解决连续渲染的连续性体验问题,也可以进一步提升渲染速度。这个名词估计听过的人少,但应该人人都体验过,Double buffering 在图形学里,一般称作双缓冲,实际上的绘图指令是在一个缓冲区完成,这里的绘图非常的快,在绘图指令完成之后,再通过交换指令把完成的图形立即显示在屏幕上,这就避免了出现绘图的不完整,同时效率很高。在游戏里其实很常见,当我们主控的人物在地图上奔跑时,游戏引擎会按照人物移动方向实时加载和渲染地图,这就避免了一次性加载超大地图时那漫长的等待。

图片来源:葡萄城公开课【SpreadJS性能优化】
SpreadJS 性能优化 - 葡萄城公开课 - 葡萄城产品技术社区 (grapecity.com.cn)
SpreadJS 对表格数据的存储优化采用了稀疏数组的数据结构。稀疏数组常用来优化二维数组(比如棋盘、地图等场景)的内存占用,但它有个天生的缺陷,就是访问性能慢。

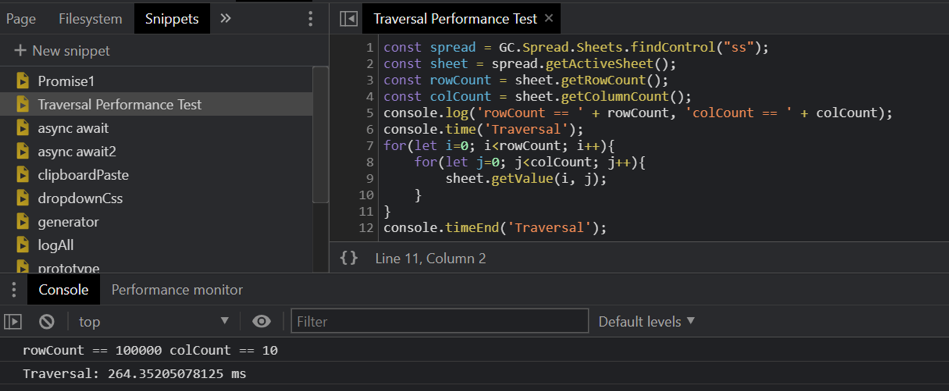
所以当时针对这个疑问,我给它做了压力测试,百万级别的遍历耗时 200 多ms。性能可以满足我们的需求。
据官方介绍来看,公式引擎其实是包含了两大实现的部分,一个是计算逻辑系统、一个是引用系统。
Excel中公式的计算都是依赖于某些原始数据的,比如 C1 引用 B1、B1 又引用 A1等等, SpreadJS 把这部分功能封装的已经非常原生化了,根本不需要开发者操心(除非有引用回溯等特殊需求)。
Excel 中 有直接引用、跨 Sheet 表单引用、相对/绝对引用、命名信息的引用、 table 行列公式的引用、跨工作簿引用等等(没列举完,感兴趣的同学可以自行搜索学习)。SpreadJS 的 runtime 是在网页端,因此跨 Workbook 引用就别想了,至少目前肯定没支持。
SUM、IF、MATCH、VLOOKUP 这种能输入到单元格里的计算公式,用起来就像是一个个的小“逻辑包”,目前 SpreadJS 有 460+ 种原生的公式函数,而 Excel 只有 490+ 种,并且 SpreadJS 能自定制公式,使用体验与原生公式一样。
对于底层实现,实际上经过多个版本的迭代,这些公式早已不是一个个独立的“逻辑孤岛”了。公式的实现在底层有大量的抽象和复用,据说新版本在性能提升的同时,代码量比老版本有明显精简,这对前端工程打包也是比较友好的。
对于嵌套公式计算的实现,SpreadJS 在底层建立起了 AST 树来解析用户设置公式的计算逻辑,从官方示例的代码来看,公式底层建立了一套 Expression,并且有对应的 public 接口可供调用,如图:

图片来源:【SpreadJS公式结构树形展示】
https://gcdn.grapecity.com.cn/showtopic-79188-1-1.html?fileGuid=QKgTJRrrCD96PXwh
首先,作为一个前端技术,咱们可以先从公式计算的技术要求上来分析性能可能出现的瓶颈以及造成的影响。我们在开发时用到了大量的用户事件、脏数据、联动等功能,所有这些功能确保正确运行的一个重要前提,就是必须能确保随时可以拿到正确的计算结果,那么最直接的实现思路就是让公式以高优先级、同步的方式来执行完计算。
大家都知道,多线程可以帮助分担计算压力,但是先抛开设计和实现难度不说,即便支持了 Web Worker,JavaScript 严格来说也只能算是一个单线程语言,因为它的 Web Worker 子线程完全受主线程控制,并且主线程无法被阻塞挂起。所以即使引入了 Web Worker,也无法确保上边提到的同步执行。
经过以上分析,可以看出公式计算性能的局限性,取决于 JavaScript 的计算能力。我找了一张相关的图片,可以直观反映 Node.js 的计算能力(Node.js 是 V8 引擎,公认最快的 JS 引擎)

图片引用自《深入浅出Node.js》

据我们测试,以上计算性能接近原生JS的计算性能,SpreadJS 在这方面的优化已经十分接近物理极限了。目前在我们的应用场景中,这个计算性能已经足够使用,但不排除以后会出现海量的数据和公式的计算需求,而在这方面官方也给出了相关解决方案,参考这里。
据说,官方还在进一步开发缓存技术,来实现公式计算的分块缓存:即使引用链上有值发生变化,也不需要计算整个引用链的公式。听起来很强大,思路也靠谱,但愿早点推出。
Excel 的样式系统非常复杂,边框、字体、对齐、数据格式、条件格式等等每一个功能点都有非常灵活庞大的实现,刚开始了解 SpreadJS 时,我也被它的 Style 类惊呆了,除了我能想象到的边框、背景、字体、对齐等这些能“看得到”的,竟然也有单元格类型、数据格式、表格按钮、下拉、水印这类东西。不由得感叹 Style 太重了,如果定制大量的单元格样式,内存和性能肯定都不好。不过实际应用中倒也没发现瓶颈,原来这里采用了分层结构来设计,如图:

图片来源:葡萄城公开课【SpreadJS性能优化】

图 6.1-1 绑定数据和公式
首先获取全局 spread 对象,spread 是整个表格的主体,spread 又分成多个 sheet。SpreadJS 初始化结束都会返回一个 spread 对象。
<gc-spread-sheets @workbookInitialized='spreadInitHandle(\$event)' />
methods:{
spreadInitHandle: function (spread) {
this.spread = sprea
},
}
tableDataBind() {
// 数据源,可以从后台请求拿到
var dataSource = {
// 注意这里加了一层bindPath,用于映射表格的绑定路径
bindPath_table: [{
c1: 100,
c2: 90,
c3: 30,
c4: 40
}, {
c1: 88,
c2: 66,
c3: 55,
c4: 100
}, {
c1: 30,
c2: 89,
c3: 100,
c4: 40
}, {
c1: 40,
c2: 66,
c3: 88,
c4: 40
}]
};
// 表格绑定和单元格绑定数据源,需要用SpreadJS的CellBindingSource包装一下
var spreadNS = GC.Spread.Sheets;
var dataSource1 = new spreadNS.Bindings.CellBindingSource(dataSource);
var table2 = this.activeSheet.tables.add("tableName", 0, 0, 1, 5, spreadNS.Tables.TableThemes.light6);
table2.showFooter(true);
table2.autoGenerateColumns(false);
var c1 = new spreadNS.Tables.TableColumn(1);
c1.name("语文");
c1.dataField("c1");
var c2 = new spreadNS.Tables.TableColumn(2);
c2.name("数学");
c2.dataField("c2");
var c3 = new spreadNS.Tables.TableColumn(3);
c3.name("英语");
c3.dataField("c3");
var c4 = new spreadNS.Tables.TableColumn(4);
c4.name("化学");
c4.dataField("c4");
var c5 = new spreadNS.Tables.TableColumn(5);
c5.name("合计");
table2.bindColumns([c1, c2, c3, c4, c5]);
table2.bindingPath("bindPath_table");
// 设置公式
table2.setColumnDataFormula(4, "=[@语文]+[@数学]+[@英语]+[@化学]");
table2.setColumnFormula(4, "=SUBTOTAL(109,[合计])");
// 设置允许单元格的内容超出单元格,与绑定无关
this.activeSheet.options.allowCellOverflow = true;
// 绑定dataSource
this.activeSheet.setDataSource(dataSource1);
this.spread.resumePaint();
}

图 6.1-2函数名和函数码映射表
#### 渲染条件格式
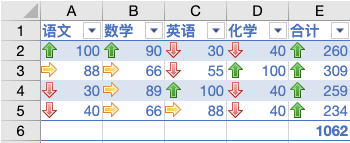
渲染条件格式:数据渲染完成只能保证数据能正常显示出来,但是这还不能满足数据分析师的需求,还要明显展示有效数据譬如:最大值,最小值标红,进度条展示一个变化状态,图标展示上升还是下降,双色阶,三色阶,等,具体怎么实现?
- 图标集:效果如图
- 实现代码
```vue
iconset() {
var activeSheet = this.activeSheet;
var iconSetRule = new GC.Spread.Sheets.ConditionalFormatting.IconSetRule();
// 演示demo先写死区域
iconSetRule.ranges([new GC.Spread.Sheets.Range(0,0, 5, 5)]);
// IconSetType图标志的类型:箭头,圆圈和execl 打通的,excel有哪些这这边就支持哪些
iconSetRule.iconSetType(GC.Spread.Sheets.ConditionalFormatting.IconSetType.threeArrowsColored);
var iconCriteria = iconSetRule.iconCriteria();
iconCriteria[0] = new GC.Spread.Sheets.ConditionalFormatting.IconCriterion(
true,
GC.Spread.Sheets.ConditionalFormatting.IconValueType.number,
60
);(<60)
iconCriteria[1] = new GC.Spread.Sheets.ConditionalFormatting.IconCriterion(
true,
GC.Spread.Sheets.ConditionalFormatting.IconValueType.number,
90
);(60<= <90)
iconCriteria[2] = new GC.Spread.Sheets.ConditionalFormatting.IconCriterion(
true,
GC.Spread.Sheets.ConditionalFormatting.IconValueType.number,
90
);(>=90)
iconSetRule.reverseIconOrder(false);
iconSetRule.showIconOnly(false);
activeSheet.conditionalFormats.addRule(iconSetRule);
}
实现代码
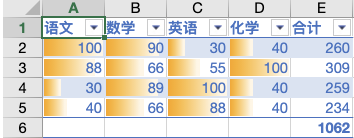
dataBar(){
var activeSheet = this.activeSheet;
activeSheet.conditionalFormats.addDataBarRule(
GC.Spread.Sheets.ConditionalFormatting.ScaleValueType.number,0,//最小数
GC.Spread.Sheets.ConditionalFormatting.ScaleValueType.number, 100,//最大值
"orange",//颜色
[new GC.Spread.Sheets.Range(0,0, 5, 4)]
);
},
重复值:效果如图
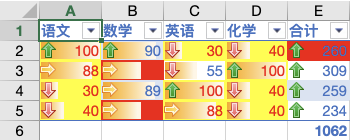
实现代码
duplicateValue() {
var activeSheet = this.activeSheet;
var style = new GC.Spread.Sheets.Style();
style.backColor = "yellow";
style.foreColor = "red";
var ranges = [new GC.Spread.Sheets.Range(0,0, 5, 4)];
activeSheet.conditionalFormats.addDuplicateRule(style, ranges);
}
-

包含文本 6 的单元格:效果如图
实现代码
includeText() {
var activeSheet = this.activeSheet;
var style = new GC.Spread.Sheets.Style();
style.backColor = "red";
var ranges = [new GC.Spread.Sheets.Range(0,0, 5, 5)];
activeSheet.conditionalFormats.addSpecificTextRule(
GC.Spread.Sheets.ConditionalFormatting.TextComparisonOperators.contains, "6", style, ranges
);
}
综合以上实现结果如图
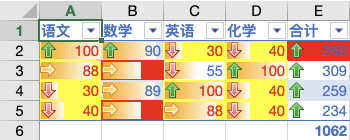
本文主要介绍了自己在数据可视化方向的一些探索,针对一些准备做市场大盘以及邮件订阅报表,线上协同协作,可视化分析等方向的同学有一定的帮助。
因篇幅较长,所涉及概念性的东西比较多,难免会出现错误,希望大家多多指正,谢谢大家!
============================
小编有话说:感谢政采云前端技术团队对葡萄城产品的认可并提供上述内容。如您也有关于葡萄城产品的使用心得,欢迎向我们投稿,在博客园私信联系我们即可。