category类型在pandas基础系列中有一篇介绍数据类型的文章中已经介绍过。category类型并不是python中的类型,是pandas特有的类型。
category类型的优势那篇文章已经介绍过,当时只是介绍了如何将某个列的数据转换成category类型,
以及转换之后给程序性能上带来的好处。
本篇将补充介绍深入使用category类型时,经常会遇到的两个问题。
一个是category类型中各个值的顺序调整;另一个是按照数值的范围转换为category类型。
当我们把一个列的数据转换为category类型时,category类型中各个值的默认顺序是按照字母顺序排列的。
比如:
import pandas as pd
df = pd.DataFrame({
"学号": [1, 2, 3, 4, 5, 6],
"年级": ["初二", "初一", "初二",
"初一", "初三", "初三"],
})
df["年级"] = df["年级"].astype('category')
df.sort_values("年级")
复制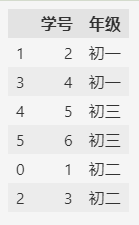
我们发现,默认顺序 **初三 **排在 **初二 **之前,与实际情况不符。
所以,需要调整category类型的顺序。
import pandas as pd
df = pd.DataFrame({
"学号": [1, 2, 3, 4, 5, 6],
"年级": ["初二", "初一", "初二",
"初一", "初三", "初三"],
})
g_type = pd.CategoricalDtype(
categories=["初一", "初二", "初三"],
ordered=True
)
df["年级"] = df["年级"].astype(g_type)
df.sort_values("年级")
复制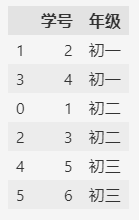
通过CategoricalDtype函数定义category类型,可以在定义时设置各个值的顺序。
有时候我们需要将一批的连续的数据按照不同的范围转换为category类型。
比如下面随机生成的100个介于1到80岁的年龄数据:
df = pd.DataFrame(
np.random.randint(1, 80, (100, 1))
)
df.columns = ["年龄"]
df
复制
希望按照不同的年龄范围划分年龄段,而不是每个年龄都转换为category类型。
这时可以用cut函数来实现:
df["年龄段"] = pd.cut(df["年龄"],
bins=[0, 18, 25, 60, 80],
labels=["儿童", "青年",
"成人", "老人"]
)
df
复制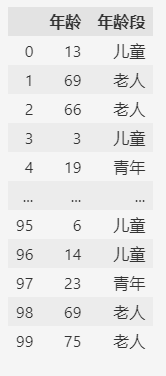
按照年龄段来划分不同的category,
category对应的范围category的值,labels列表中值的顺序就是category的顺序除了cut函数,还有个qcut函数,也可以按照数据范围来生成category类型。
它们的区别主要在于:
bins。bins的数目可以是等距的,也可以是自定义的。bins,每个bin中含有的数据个数相同或尽可能接近。bins的数量由程序自动确定。因此,cut函数适合等距离离散化,而qcut函数适合非等距离离散化。
例如,我们有1000个数据点,想要把它们分为10组,cut函数通常会将数据平均分为长度相同的10个组,
而qcut函数则会将这些数据分为包含大约100个数据点的10个组。