上一篇介绍了DataFrame的显示参数,主要是对DataFrame中值进行调整。
本篇介绍DataFrame的显示样式的调整,显示样式主要是对表格本身的调整,
比如颜色,通过颜色可以突出显示重要的值,观察数据时可以更加高效的获取主要信息。
下面介绍一些针对单个数据和批量数据的样式调整方式,让DataFrame的数据信息更加的一目了然。
每个DataFrame都有个style属性,通过这个属性可以来调整显示的样式。
下面的示例,一次调整多个类型的列的显示。
import pandas as pd
df = pd.DataFrame(
{
"日期": ["2022-10-01", "2022-11-11",
"2022-12-12", "2023-01-01", "2023-02-02"],
"单价": [1099.5, 8790.0, 12.55, 10999.0, 999.5],
"数量": [1, 3, 1200, 4, 5],
}
)
df["日期"] = pd.to_datetime(df["日期"])
col_format = {
"日期": "{:%Y/%m/%d}",
"单价": "¥{:,.2f}",
"数量": "{:,} 件"
}
df.style.format(col_format)
复制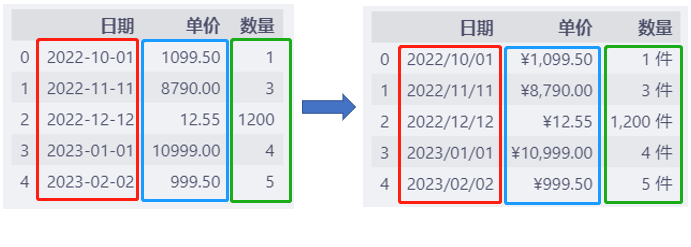
调整之后:
/来分割调整之后,表格中的内容放入报告中会更加美观。
除了调整数值的显示样式,更强大的功能是,我们可以调整单元格的颜色。
比如,下面的数据,我们先计算出总价,
然后用红色背景标记出总价最小的订单,用绿色背景标记出总价最大的订单。
df = pd.DataFrame(
{
"订单号": ["0001", "0002",
"0003", "0004", "0005"],
"单价": [1099.5, 8790.0,
12.55, 10999.0, 999.5],
"数量": [1, 3, 1200, 4, 5],
}
)
df["总价"] = df["单价"] * df["数量"]
col_format = {
"单价": "¥{:,.2f}",
"总价": "¥{:,.2f}",
}
df.style.format(col_format).highlight_min(
"总价", color="red"
).highlight_max(
"总价", color="lightgreen"
)
复制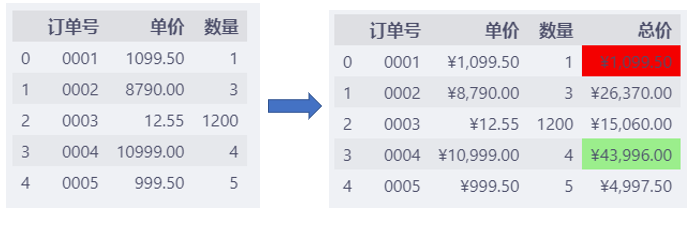
添加背景色之后,只能看出哪个订单总价最高,哪个订单总价最低。
对于其他的订单,没有直观的印象,所以,下面我们更进一步用渐变色来标记总价列。
总价越高,背景色越深,这样就对所有订单的总价有了直观的印象。
df = pd.DataFrame(
{
"订单号": ["0001", "0002", "0003", "0004", "0005"],
"单价": [1099.5, 8790.0, 12.55, 10999.0, 999.5],
"数量": [1, 3, 1200, 4, 5],
}
)
df["总价"] = df["单价"] * df["数量"]
col_format = {
"单价": "¥{:,.2f}",
"总价": "¥{:,.2f}",
}
df.style.format(
col_format
).background_gradient(
subset="总价", cmap="Greens"
)
复制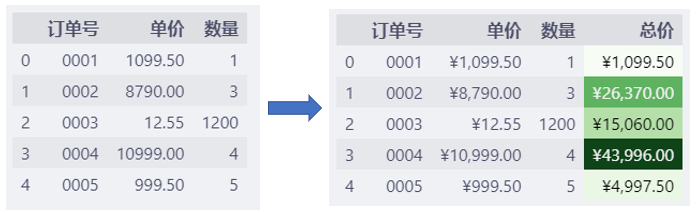
再进一步,用条形图+渐变色的方式显示总价信息。
这样,不仅可以看出总价的高低,还能大致看出究竟高了多少。
df = pd.DataFrame(
{
"订单号": ["0001", "0002", "0003", "0004", "0005"],
"单价": [1099.5, 8790.0, 12.55, 10999.0, 999.5],
"数量": [1, 3, 1200, 4, 5],
}
)
df["总价"] = df["单价"] * df["数量"]
col_format = {
"单价": "¥{:,.2f}",
"总价": "¥{:,.2f}",
}
df.style.format(
col_format
).bar(
subset="总价", cmap="Wistia"
)
复制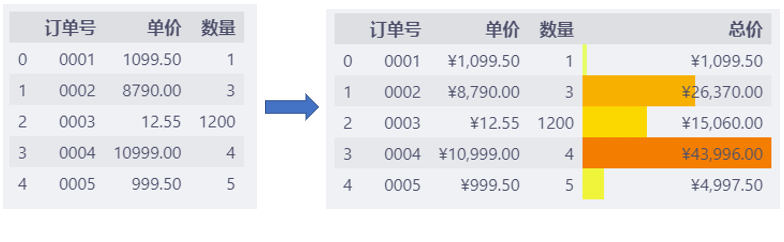
通过pandas本身的样式参数,可以美化分析的结果,直接用于最后的报告或者PPT中。
pandas小技巧系统至此暂时告一段落,接下来,准备开始另一个关键的数据分析库:numpy。