摘要:我们在打扑克,一摞的扑克牌就相当于dataset,拿牌的手相当于神经网络。而dataloader相当于抽牌的过程,它可以控制我们抽几张牌,用几只手抽牌。
官网地址:
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=None, persistent_workers=False, pin_memory_device='')
复制由此可见,DataLoder必须需要输入的参数只有\(dataset\)。
dataset(Dataset): 数据集的储存的路径位置等信息
batch_size(int): 每次取数据的数量,比如batchi_size=2,那么每次取2条数据
shuffle(bool): True: 打乱数据(可以理解为打牌中洗牌的过程); False: 不打乱。默认为False
num_workers(int): 加载数据的进程,多进程会更快。默认为0,即用主进程进行加载。但在windows系统下,num_workers如果非0,可能会出现 BrokenPipeError[Error 32] 错误
drop_last(bool): 比如我们从100条数据中每次取3条,到最后会余下1条,如果drop_last=True,那么这条数据会被舍弃(即只要前面99条数据);如果为False,则保留这条数据
首先import dataset,dataset会返回一个数据的img和target
然后import dataloder,并设置\(batch\_size\),比如\(batch\_size=4\),那么dataloder会获取这些数据:dataset[0]=img0, target0; dataset[1]=img1, target1; dataset[2]=img2, target2; dataset[3]=img3, target3. 并分别将其中的4个img和4个target进行打包,并返回打包好的imgs和targets
比如下面这串代码:
import torchvision
from torch.utils.data import DataLoader
#测试集,并将PIL数据转化为tensor类型
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#batch_size=4:每次从test_data中取4个数据集并打包
test_loader=DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
复制这里的test_loader会取出test_data[0]、test_data[1]、test_data[2]、test_data[3]的img和target,并分别打包。返回两个参数:打包好的imgs,打包好的taregts
代码示例如下:
import torchvision
from torch.utils.data import DataLoader
#测试集,并将PIL数据转化为tensor类型
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#batch_size=4:每次从test_data中取4个数据集并打包
test_loader=DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
#测试数据集中第一章图片及target
img, target=test_data[0]
print(img.shape)
print(target)
#取出test_loader中的图片
for data in test_loader:
imgs,targets = data
print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
复制在11行处debug一下可以发现,test_loader中有个叫sampler的采样器,采取的是随机采样的方式,也就是说这batch_size=4时,每次抓取的4张图片都是随机抓取的。
用tensorboard就可以可视化了,具体操作改一下上面代码最后的for循环就好了
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("dataloder")
step=0 #tensorboard步长参数
for data in test_loader:
imgs,targets = data
# print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
# print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
writer.add_images("test_data",imgs,step) #注意这里是add_images,不是add_image。因为这里是加入了64张图
step=step+1
writer.close()
复制首先将shuffle设置为False:
test_loader=DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
复制然后对(2)的代码进行修改,运行代码:
for epoch in range(2): #假设打两次牌,我们来观察两次牌中间的洗牌情况
step = 0 # tensorboard步长参数
for data in test_loader:
imgs,targets = data
# print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
# print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
writer.add_images("Epoch: {}".format(epoch),imgs,step) #注意这里是add_images,不是add_image。因为这里是加入了64张图
step=step+1
writer.close()
复制结果显示,未洗牌时运行的结果是一样的:
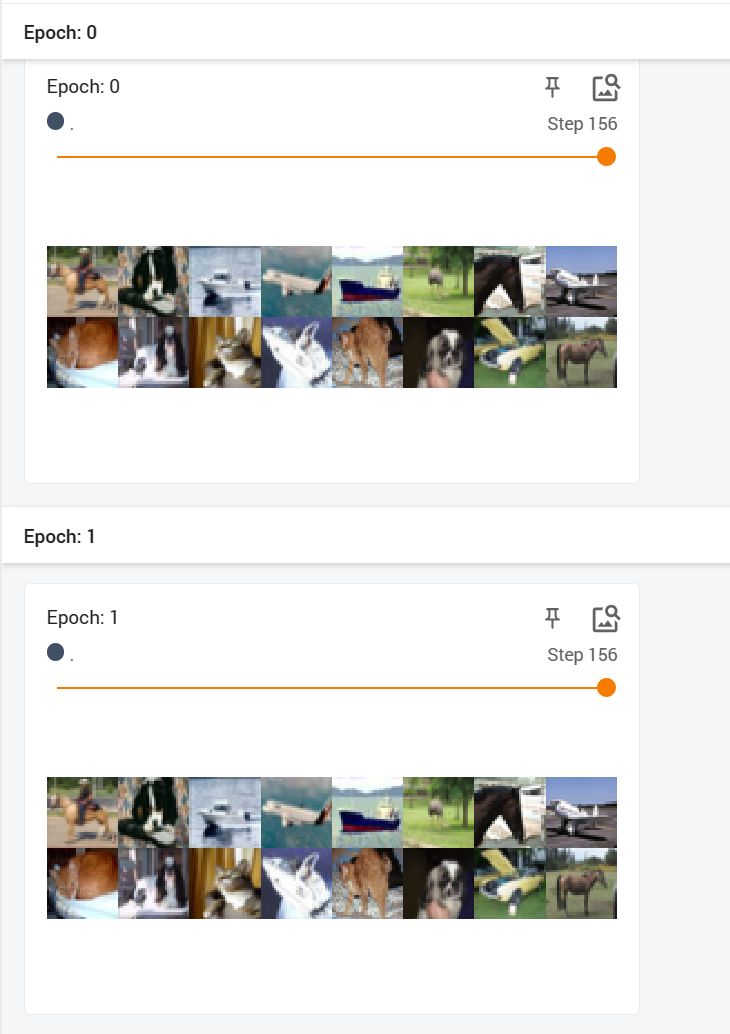
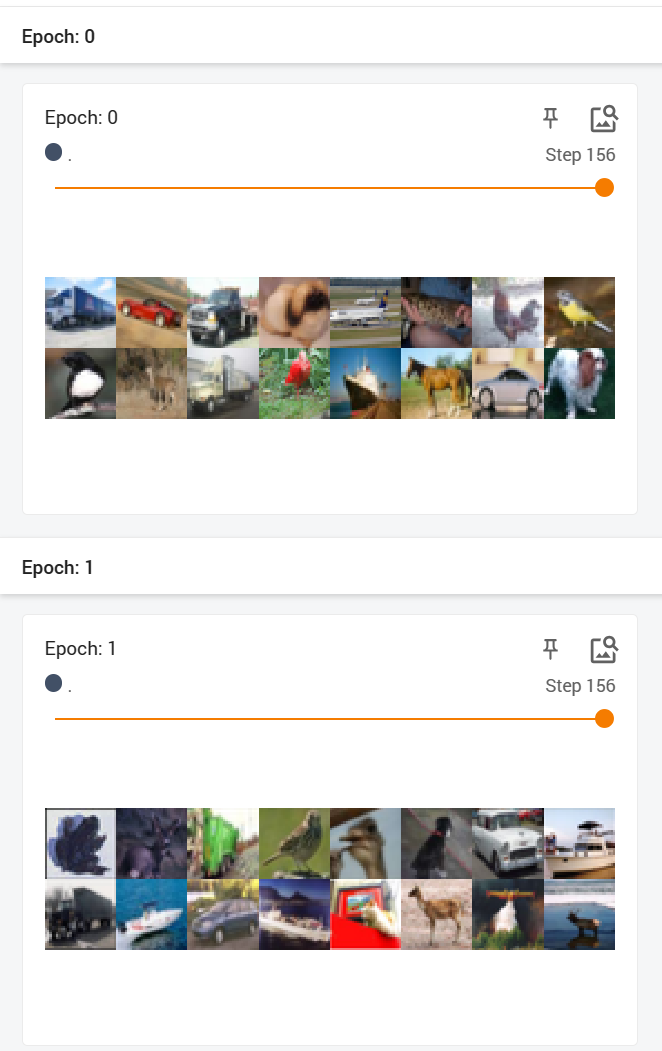
我们在打扑克,一摞的扑克牌就相当于dataset,拿牌的手相当于神经网络。而dataloader相当于抽牌的过程,它可以控制我们抽几张牌,用几只手抽牌。