作者:京东科技 康志兴
从强调内外隔离的六边形架构,逐渐发展衍生出的层层递进、注重领域模型的洋葱架构,再到和DDD完美契合的整洁架构。架构风格的不断演进,其实就是为了适应软件需求越来越复杂的特点。
可以看到,越现代的架构风格越倾向于清晰的职责定位,且让领域模型成为架构的核心。
基于这些架构风格,在软件架构设计过程中又有非常多的架构分层模型。
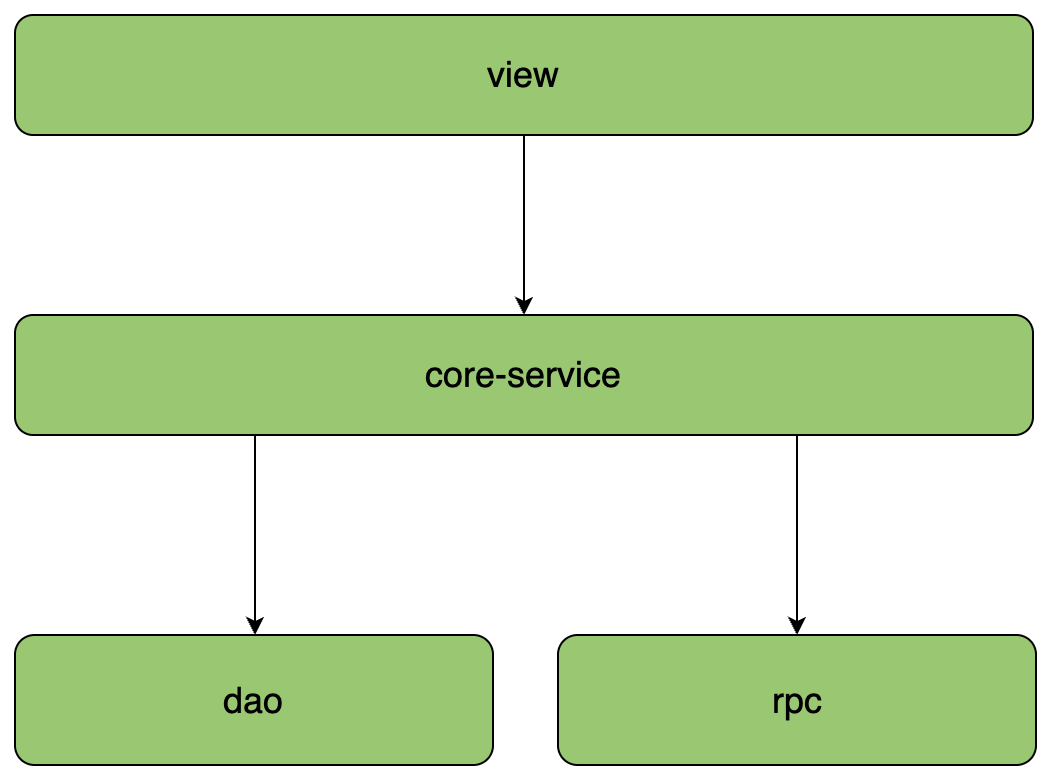
传统服务通常使用三层架构:
• 门面层:作为服务暴露的入口,处理所有的外部请求。部分情况下,门面层甚至不需要单独定义对象而是直接使用服务层的实体定义。
• 服务层:作为核心业务层,包含所有业务逻辑。并对基础层能力进行简单组合提供一定的能力复用。通常服务层会进行实体定义来防止下层对象体直接暴露给外部服务,导致底层任何变化都有可能直接传递到外部,非常不稳定。
• 基础层:用来存放dao和外部rpc服务的封装,二者可以拆分为不同的module,也可合二为一,以不同package进行隔离。
三层架构特点就是简单,适用于一些无复杂业务场景的小型应用,或者“数据不可变”作为基础原则的DOP(面向数据编程)服务。
但是当业务场景稍微复杂一些、调用层级较多时,可复用性、可维护性就都非常差了,很多代码都耦合在一起,牵一发动全身。
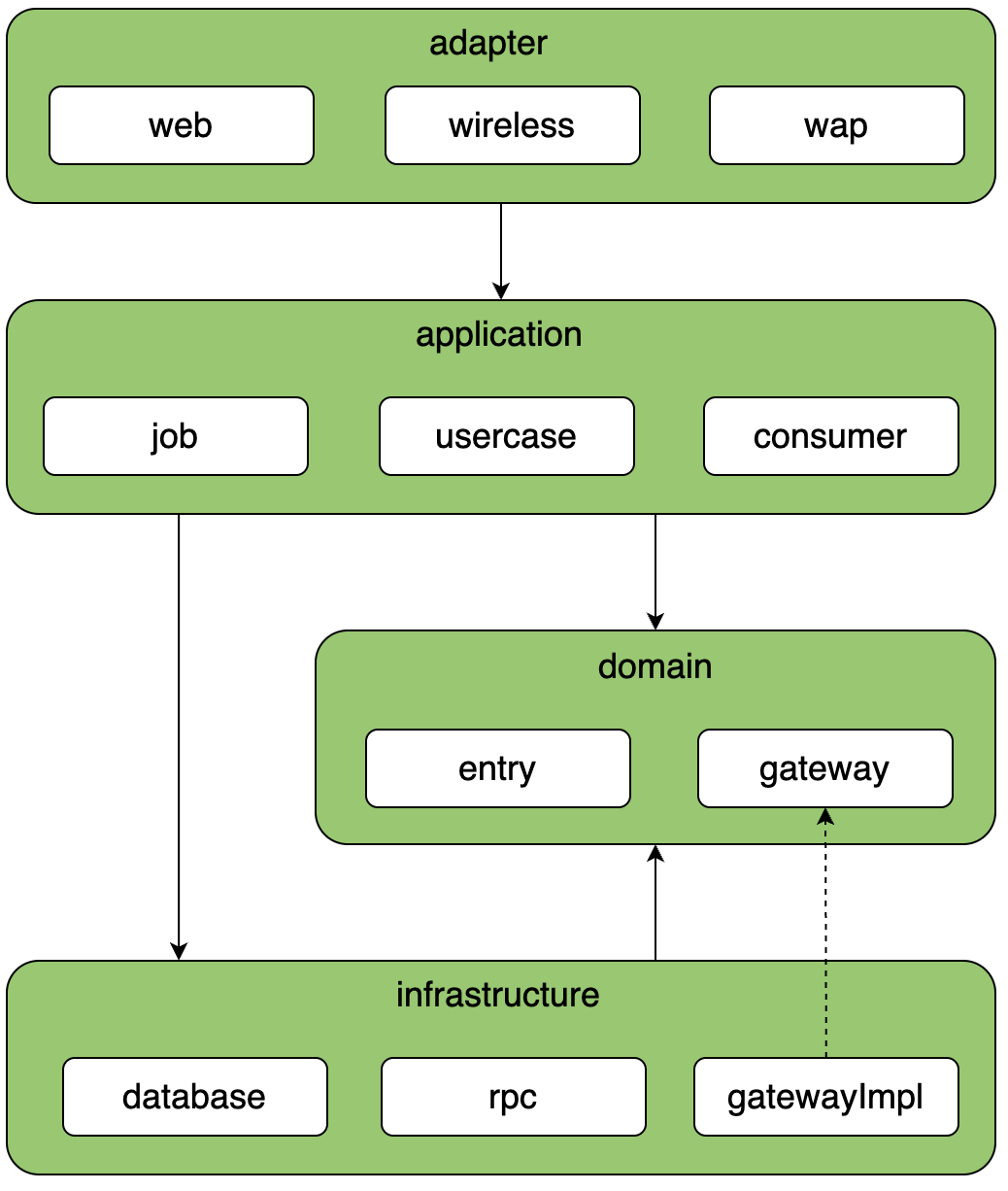
DDD架构可以看做是整洁架构的一种实现,分层职责如下:
• 适配层:用来做外部不同端请求的适配器,隔离不同端的协议差异,包装不同端不同样式的响应体。
• 应用层:用例、任务入口、消息队列监听均在这一层,可以理解为业务流程的入口,通过聚合根的构造执行相应的命令操作。
• 领域服务层:包含核心的领域服务定义,并定义了gateway来做一层依赖倒置,使基础设施层仅做实现。
• 基础设施层包含一切基础能力:数据库、ES、远程调用封装等等。
• 核心稳定:领域模型在依赖链上是顶层角色,不依赖任何其他模块,所以极其稳定。其他任何业务域、存储、边缘能力的变化都不会对领域模型造成影响。
• 敏捷:适合不同团队一起开发和维护而不会产生冲突。
• 可拆分:当有届上下文随着演进逐渐膨胀时,很容易拆分成微服务。
• 可扩展:添加新的功能非常简单,从而使得开发人员能够更快的部署和调整。
• 可演进:良好的可测试性带来非常低的重构成本,不会随着不断迭代导致项目成为难以修改的“大泥球”。
• 专业性要求较高:需要对业务、架构原则理解深刻的人员进行设计和维护,不恰当的领域模型将使后续迭代极为痛苦。
• 开发成本高:复杂的架构设计,更多的架构分层,自然带来代码行数的指数级增长。尤其是项目前期的开发任务变得异常繁重。
• 不再适合简单的业务场景:实现一个简单的CRUD显得过于复杂。
• 改变决策困难:尝试使用整洁架构需要和团队的管理层和其他成员达成一致,这往往需要非常强大的说服力。如果在架构演进过程中想切换回其他架构模式也十分困难,几乎是整个项目级别的重构工作。
基于六边形架构规范的接口适配原则和防腐理念,同时借鉴了CQRS模式的优点,我们定义了一个简单的微服务分层架构。
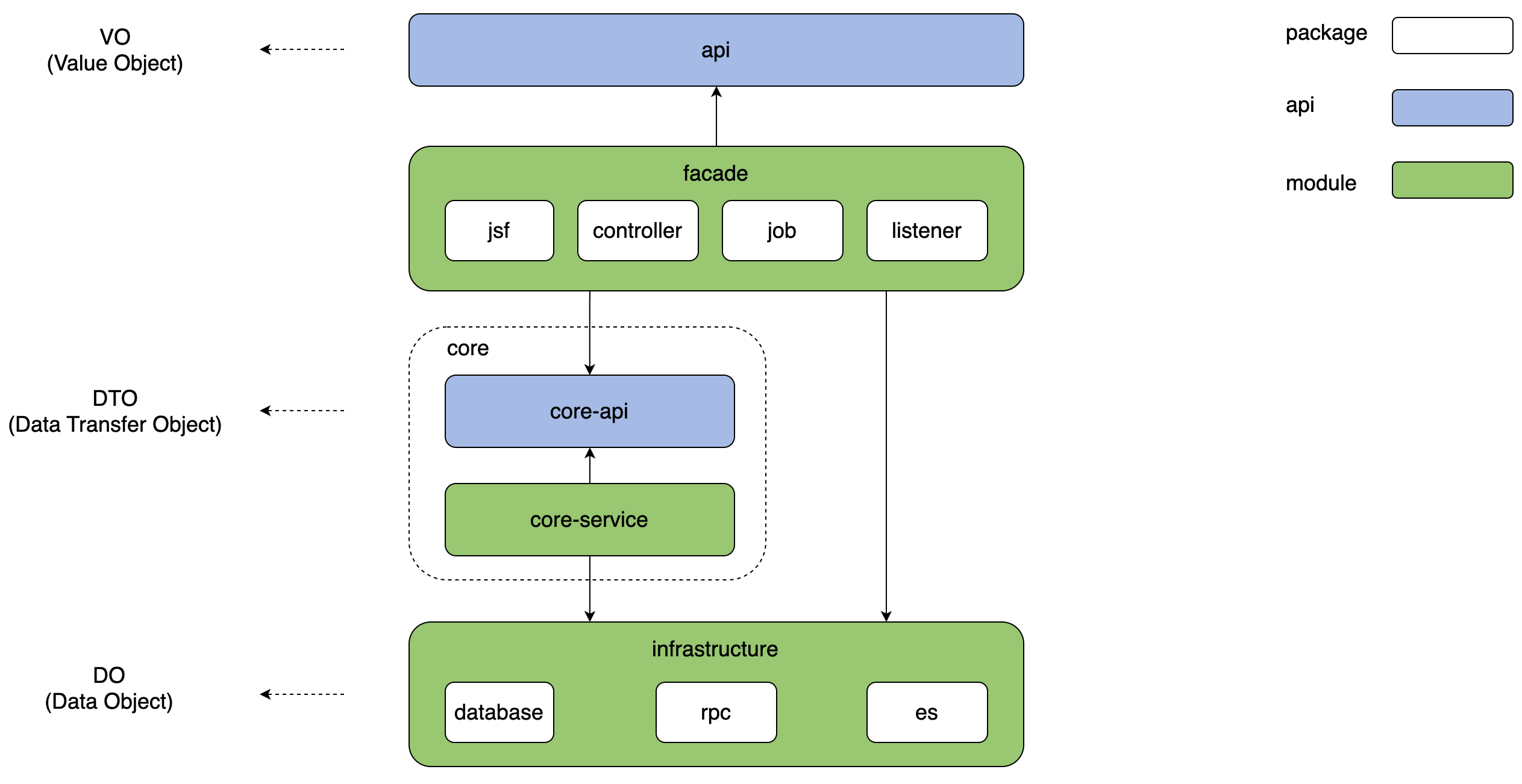
分层定义如下:
• 门面层:作为程序的入口,通过包隔离来存放JSF服务、Rest服务、定时任务和MQ消费,其中对外提供服务的接口定义存放在单独的api包中。该层的请求定义命名以Request结尾,响应体命名以Response结尾。
• 领域服务层:每一个领域服务存放在单独的module中,并通过单独的api包对外暴露能力。该层的命令请求定义命名以Command结尾,查询请求定义命名以Query结尾,响应体命名以Dto结尾。
• 基础设施层:存放数据库、ES、远程调用服务的封装。该层的持久化数据定义命名以Po结尾。远程命令服务入参命名以RpcCommand结尾,远程查询服务入参命名以RpcQuery结尾,响应体命名以RpcDto结尾。
命令服务必须访问领域服务层,允许简单查询直接调用基础设施层。
参数校验、请求出入参日志、审计日志记录、TraceID预埋、异常处理等非核心业务能力均由公共组件完成,减少项目内部的边缘能力代码。
由于在门面层进行统一的异常处理,非必要时无需在项目中进行大面积的try-catch,让代码更清爽。
实际开发过程中,门面层、领域服务层和基础设施层均有各自的实体定义,跨层调用的对象体转换使用MapStruct组件来减少手写映射代码的工作量。
数据层使用Fluent-Mybatis,最大好处是减少后期迭代中,数据对象增减字段时修改Mapper的成本。
1. 开发效率
简单的业务开发过程中,相比较书写核心业务逻辑,更多的工作量几乎都是来自处理跨层调用时对象转换和Mapper定义,通过MapStruct和Fluent-Mybatis等组件的使用(也许再加上GitHub Copilot😁),编写一个实体的增删改查接口基本在5分钟内搞定,省下来的时间可以多走读两遍代码或者多写几个分支的测试用例,也算是降本增效了。
2. 服务隔离
通过module隔离不同的领域服务,降低不同领域服务之间的耦合程度。
3. 外部服务防腐
远程调用统一封装在基础设施层中,降低外部变化对系统内部的影响。
由于对基础设施层的依赖没有通过api包进行隔离,所以基础设施层的对象会直接暴露在领域服务层和门面层。对此可以通过使用ArchUnit组件进行架构防腐。
如果需要定义完善的领域实体充血模型,建议参考DDD架构定义gateway层来进行基础设施层的依赖倒置。
软件工程的方方面面都遵循一个最基本的道理:没有银弹,架构分层模型更是如此,每一种都有各自优缺点,所以请根据不同的业务场景,并遵循简单、可演进这两个重要的架构原则选择合适的架构分层模型即可。
架构不只是工作,更是一门艺术。