摘要:本文提出了一种针对文字识别的半监督方法。区别于常见的半监督方法,本文的针对文字识别这类序列识别问题做出了特定的设计。
本文分享自华为云社区《[CVPR 2022] 不使用人工标注提升文字识别器性能》,作者:Hint。
本文提出了一种针对文字识别的半监督方法。区别于常见的半监督方法,本文的针对文字识别这类序列识别问题做出了特定的设计。具体来说,本文首先采用了teacher-student的网络结构,然后采用字符级别的一致性约束对teacher和student网络的预测进行对齐。此外,考虑到文字识别是step-by-step,每一个字符的预测都和之前时刻的预测结果相关。为了避免student网络在当前时刻的预测结果受到之前时刻错误预测的影响,本文将当前时刻之前,teacher的预测结果作为student当前时刻之前的预测结果,这样可以得到比较鲁棒的一致性约束,从而提升性能。

近年来,场景文本识别(STR)因其广泛应用而备受关注。大多数识别模型需要大量的有标注数据进行强监督训练。虽然合成数据可以缓解识别模型对数据量的需求,但是合成数据和真实场景的域间差距极大地限制了识别模型在真实场景下的性能。在本文中,作者希望通过同时利用有标注的合成数据以及无标注的真实数据来提升STR模型的性能,完全不需要任何人工标注。本文提出了一种鲁棒的基于一致性约束的半监督方法,可以有效解决合成数据与真实数据域不一致导致的不稳定问题。字符级的一致性约束旨在减轻序列识别过程中错误识别导致的不对齐问题。在标准文字识别数据集上,大量实验证明了所提出方法的有效性。该方法能够稳步提升现有的STR模型,并得到最先进的结果。此外,本文也是第一个将一致性约束应用到文字识别领域的工作。
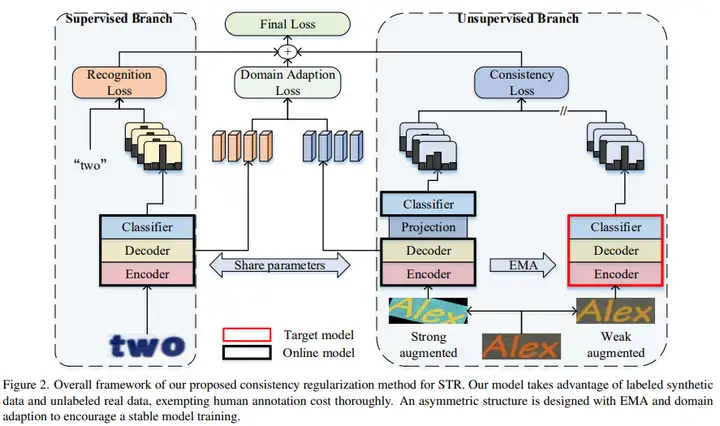
本框架包括两个分支,一个是输出有标签合成数据的强监督分支,一个是输入无标签真实数据的半监督分支。强监督分支和一般的识别模型一样。关于半监督分支,采用teacher-student进行一致性约束。具体来说,将强监督得到的预训练模型作为teacher和student网络的初始化模型,然后对同一张输入图像进行弱数据扩增和强数据扩增,并分别输入到teacher和student网络中;将teacher网络的预测结果作为伪标签对student的输出进行监督。
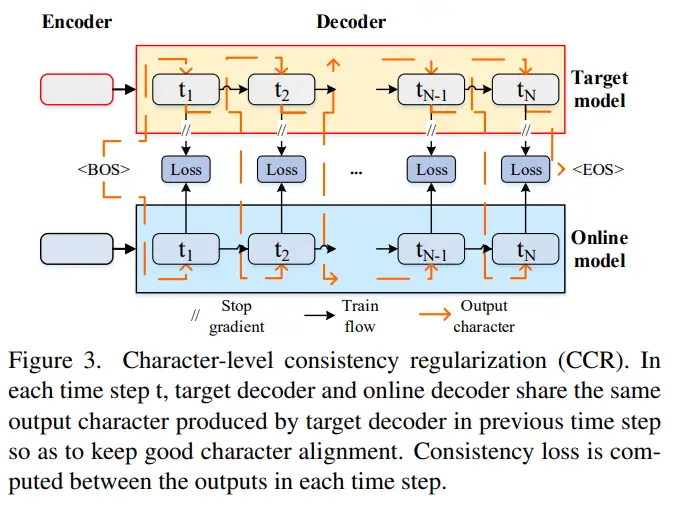
由于文字识别是一个序列识别问题,当前时刻的预测结果和之前时刻的预测结果相关。为了尽可能减少target和online模型在同一时刻预测结果的不对齐问题,online分支之前时刻的预测结果会和target分支之前时刻的预测结果保持一致,然后再进行当前时刻的字符预测。字符级别的一致性loss如下公式所示,Dist()可以是交叉熵,KL-Div或者MSE,本文采用的是KL-Div。
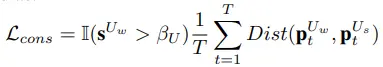
此外,为了减轻合成数据与真实数据之间的域间差别,本文还使用了字符级别的域对齐模块。该模块首先分别将合成数据和真实数据每个时刻的视觉特征收集起来构成一个集合H
,然后计算他们各自的协方差矩阵cov()。
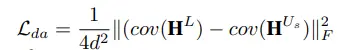
最终,整个框架的loss由强监督识别loss,一致性约束loss和域适应loss构成:
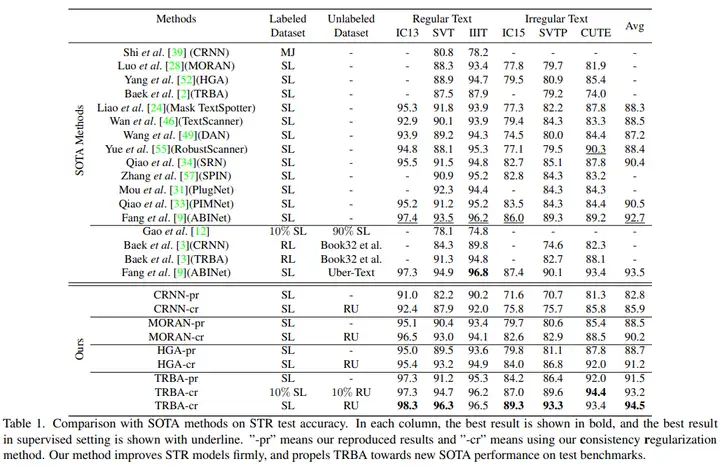
在引入无标签数据之后,当前识别模型的性能能够得到稳定的提升。
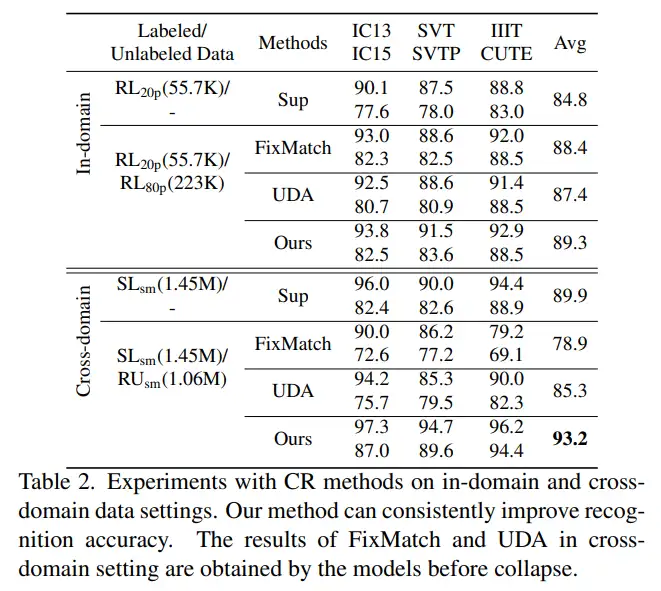
相比于其他利用无标签数据的方法而言,本文提出的基于一致性约束的方法能够优于其他几种方法。
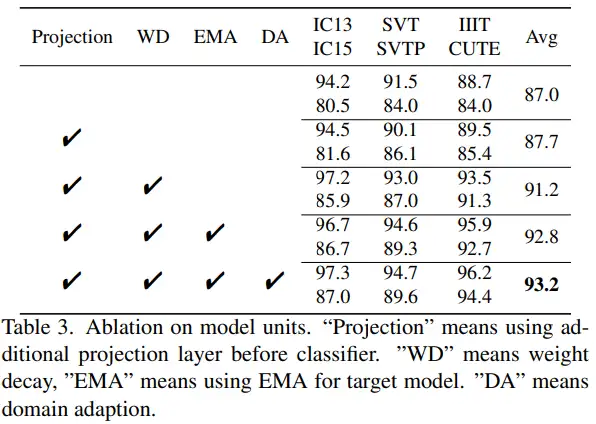
该实验主要证明了online model中的projection layer,使用EMA更新的target model和domain adaptation模块的有效性。
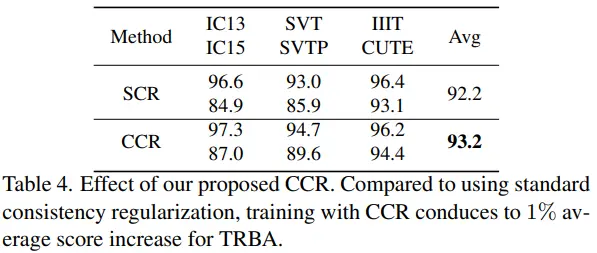
该实验证明了在online model中使用和target model相同的之前时刻预测结果的有效性。
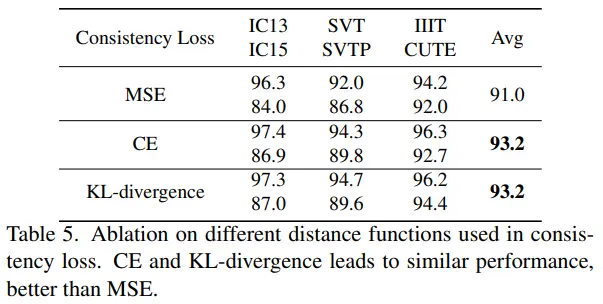
该实验主要讨论了一致性loss的类型对最终性能的影响,可以看到交叉熵和KL-Div性能差不多,且优于MSE。
华为《Taurus MM: bringing multi-master to the cloud》论文被国际数据库顶会VLDB 2023录用,这篇论文里讲述了符合云原生数据库特点的超燃技术。