摘要:openGemini的设计和优化都是根据时序数据特点而来,在面对海量运维监控数据处理需求时,openGemini显然更加有针对性。
IT运维诞生于最早的信息化时代。在信息化时代,企业的信息化系统,主要为了满足企业内部管理的需求。通常是集中、可控和固化的烟囱式架构。传统IT运维,以人力运维为主,在单点式和烟囱式的架构中,的确起到了非常重要的作用。
我们知道,传统运维模式关注的是单台IT设备的故障率或单套应用系统的可用性,系统与系统之间,设备与设备之间,是彼此孤立的,因此产生的数据量也相对有限。
但进入到云计算时代之后,IT的边界被完全打开,更多的联接、更多的设备、更多的服务,使得系统规模开始变得越来越大,随着监控粒度越来越细,监控数据呈现出爆炸式增长的态势,每天将产生上百TB的数据,如何对如此海量的数据进行处理成为华为云SRE面临的一大难题
华为云SRE基础设施监控系统是一个先进的平台,用于监控和管理华为云在全球各个region的基础设施。该系统需要实时监测各种资源,包括网络、存储、计算、安全和各个云服务。
业务诞生之初,适逢“大数据”时代,Hadoop作为批量离线计算系统已经得到了业界的普遍认可,并经过了工业上的验证,所以HBase具备“站在巨人肩膀之上”的优势,其发展势头非常迅猛。HBase还是一种NoSQL数据库,支持水平扩展和大规模数据的存储能力,故选型HBase。当然内部也基于HBase做过很多优化,比如缩短row key,减少Key-Value数,按照时间维度分表,将单行多列变为单行单列。
随着华为云业务扩展,特别是近些年,华为云在全球布局的速度也突飞猛进,所要监控的设备也越来越多,颗粒度越来越细,查询场景也逐渐丰富,HBase明显已经无法满足当前业务需要,问题主要体现在以下几点:
为了解决这些痛点,我们将目光投向时下流行的时序数据库(Time-Series Database)。首先在DBEngines排名前20的开源时序数据库中甄别,排除商业品类、开源协议不友好的,初步拟选了InfluxDB、Druid、Prometheus、OpenTSDB几款,经过技术对比,InfluxDB只有单机版,功能和性能受限大,故排除。OpenTSDB底层存储仍然是HBase,存储成本问题仍然存在,故排除。Prometheus不适合在大规模数据场景下使用。Druid是一个实时分析型的数据库,用于大规模实时数据导入、快速查询分析的场景,基本满足需求,但在时空聚合查询场景时延相对较大。徘徊之际,了解到华为云开源的openGemini,经过测试对比,openGemini在数据压缩效率、读写性能方面优势明显,经过和openGemini社区团队交流后,最后选择了openGemini存储全网华为云SRE基础设施监控数据。
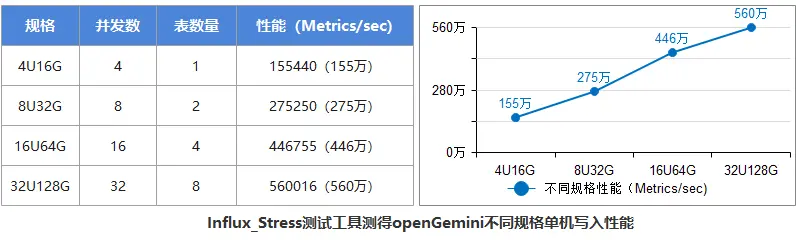
上述测试结果显示了openGemini 从4U扩展到32U的性能表现,可以看出:
查询性能是我们重点考虑的方面,测试工具Jmeter,测试场景从业务中挑选了使用频率较高的三种类型查询语句,在此基础上变化查询并发数、查询时间范围、聚合算子等进行测试。
测试语句举例:

测试规格与集群部署

测试结果(20并发6h 表示查询并发为20,时间范围为6小时)
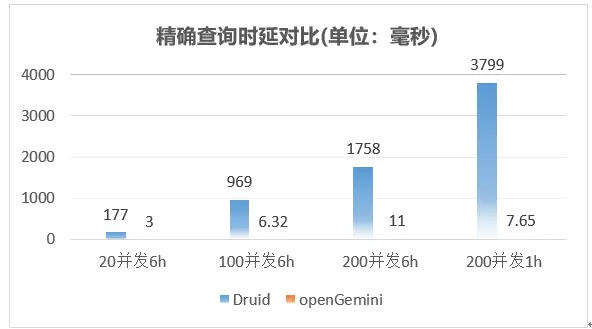
精确查询整体性能表现如下:
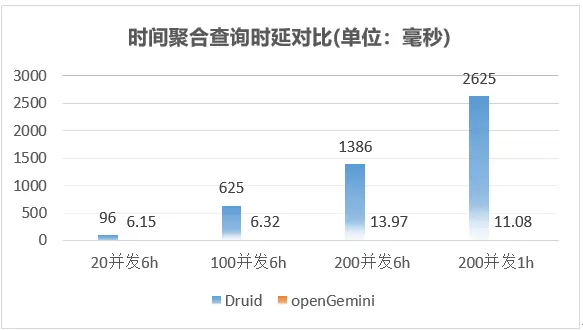
时间聚合查询整体性能表现如下
时空聚合查询整体性能表现如下
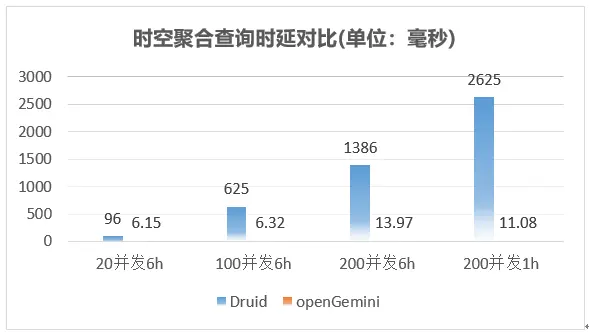
整体上,openGemini在上述三种查询场景下,相比Druid性能大幅领先。openGemini写入性能满足目前同样流量大小的HBase集群,而且使用的规模要小不少。此外,openGemini不依赖任何第三方组件或应用,同时还有非常丰富的监控指标,更好的观察系统的运行状况,快速定位和解决问题。
采用openGemini后,并没有立即拆除已有系统。主要考虑两方面:
我们给openGemini和HBase配置了不同的DNS,切换DNS就可以非常方便地查询不同数据库的数据,对现网可靠性也不会产生影响。
截止目前,已实现全网流量切入openGemini,系统平稳运行超过半年。
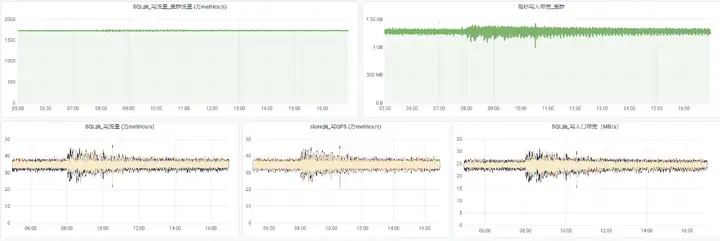
和之前的HBase对比:
openGemini的设计和优化都是根据时序数据特点而来,在面对海量运维监控数据处理需求时,openGemini显然更加有针对性,而以上的事实证明,在运维监控场景中,openGemini的应用能够提升运维效率,降低运维成本,真正帮助企业实现降本增效。