摘要:本文提出了一种针对文字识别的多模态半监督方法,具体来说,作者首先使用teacher-student网络进行半监督学习,然后在视觉、语义以及视觉和语义的融合特征上,都进行了一致性约束。
本文分享自华为云社区《一种针对文字识别的多模态半监督方法》,作者: Hint 。

直到最近,公开的真实场景文本图像的数量仍然不足以训练场景文本识别器。因此,当前大多数的训练方法都依赖于合成数据并以全监督的方式运行。然而,最近公开的真实场景文本图像的数量显着增加,包括大量未标记的数据。利用这些资源需要半监督方法;然而,这些方法不能直接适配文字识别这类视觉语言的多模态结构。因此,本文提出了半监督多模态文本识别器(SemiMTR),它在训练阶段中,利用每个模态的未标记数据。此外,本文的方法并不需要额外的训练阶段,保持了当前的三阶段多模态训练策略。
首先,在视觉模型方面,本文提出了一个将自监督预训练和强监督训练结合的单阶段训练模型。然后,语言模型是在一个大型文本语料库上进行自监督预训练。得到两个模态的预训练模型之后,对文字识别进行半监督训练。本文采用的是teacher-student的结构,具体来说,对一张文本图像分别进行弱数据扩增和强数据扩增,然后对两个网络不同模态的输出进行一致性约束。大量实验证实本文的方法优于当前的训练方案,并在多个场景文本识别基准上取得了最先进的结果。
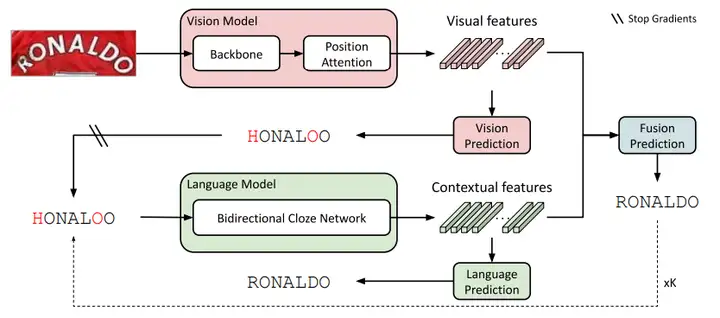
首先,本文的文字识别框架采用的是ABINet。大致流程如下:首先,视觉模型首先提取图像的特征序列并将其解码成字符序列;接着,将字符序列输入给语言模型,得到文本的语义特征;最后,使用一个融合模块,将视觉和语义特征进行融合,得到最终的识别结果。为了进一步提高识别性能,可以采用迭代的方式,多次对识别结果进行微调。
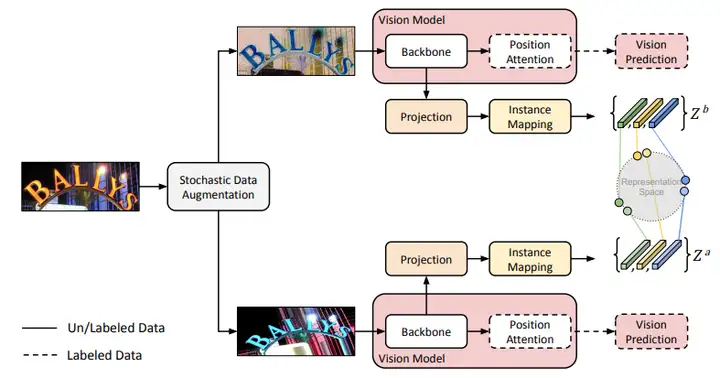
本文将自监督预训练与强监督预训练融合到了一个统一的框架下。自监督预训练采用的是基于对比学习的方法,在自监督的同时,也会对这些数据进行有标注的强监督预训练。
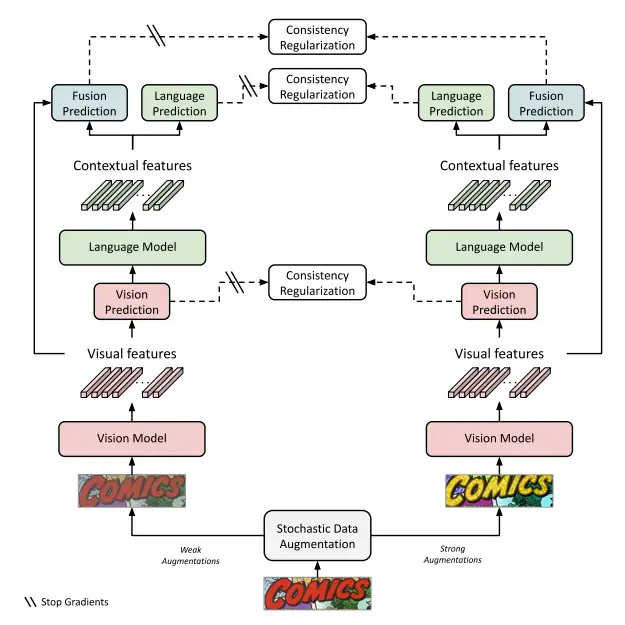
首先,本文采用的是一个常见的teacher-student网络,进行半监督训练。具体来说,将前面得到的预训练模型作为teacher和student网络的初始化模型,然后对同一张输入图像进行弱数据扩增和强数据扩增,并分别输入到teacher和student网络中;将teacher网络的预测结果作为伪标签对student的输出进行监督。区别于一般的半监督学习,本文的方法对识别模型的各个模态都进行不同程度的一致性约束,比如视觉模型,语言模型和融合模型的输出。
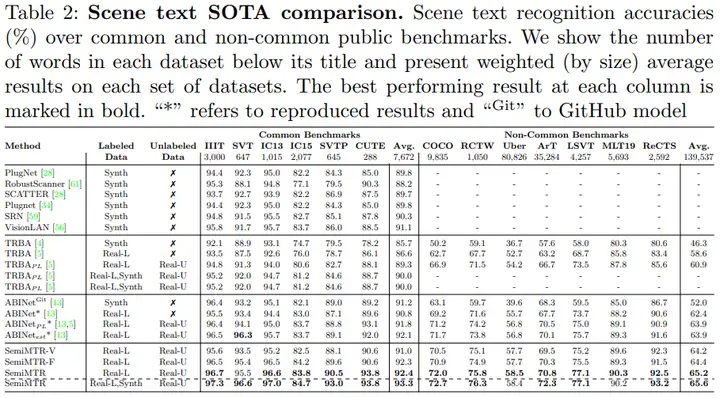
可以看到,本文的结果在多个数据集上取得了一致性的提升。

可以看到,在视觉预训练阶段,统一自监督预训练和强监督预训练比分阶段的训练效果要好。
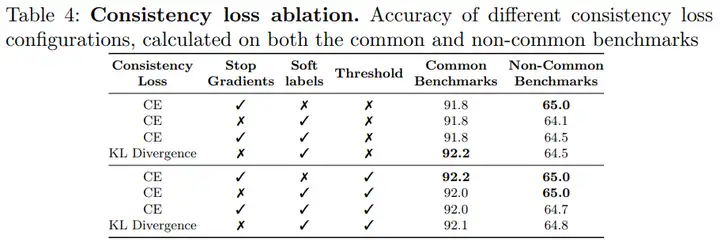
可以看到,使用交叉熵loss作为一致性约束loss效果最好。
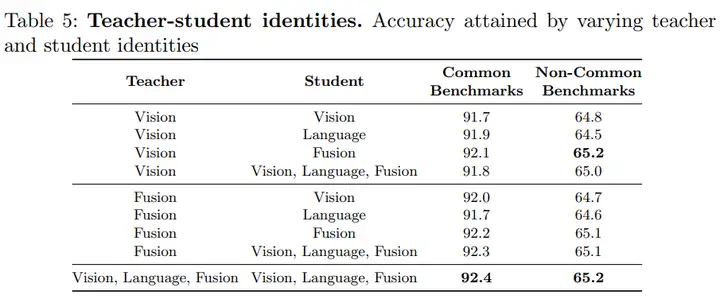
由于本文采用的识别模型,具有视觉、语言和融合的模态,所以在进行一致性约束的时候,teacher网络和student网络可以采用不同的特征分别进行对齐。从上表可以看到,当teacher和student网络中的vision,language和fusion模块分别进行对齐的时候,效果最好。
论文链接:[2205.03873] Multimodal Semi-Supervised Learning for Text Recognition (arxiv.org)
这篇文章属于系统分析类的文章,通过详细的实验分析了离地攻击(Living-Off-The-Land)的威胁性和流行度,包括APT攻击中的利用及示例代码论证。
本文提出了一种实现了检测高级持久性威胁(Advanced Persistent Threat,APT)新的方法,即HOLMES系统。
网上找到的Master公式推导过程都太过于复杂了,为此我特地找到一种小白也能看懂的推导过程。看完这篇文章后,你会对递归的时间复杂度深谙于心,打死都不会忘记。