摘要:本文通过多种操作构建混合模型,增强视觉Transformer捕捉空间相关性的能力和其进行通道多样性表征的能力,弥补了Transformer在小数据集上从头训练的精度与传统的卷积神经网络之间的差距。
本文分享自华为云社区《[NeurIPS 2022] 消除视觉Transformer与卷积神经网络在小数据集上的差距》,作者:Hint。
本文简要介绍NeurIPS 2022录用的论文“Bridging the Gap Between Vision Transformers and
Convolutional Neural Networks on Small Datasets”的主要工作。该论文旨在通过增强视觉Transformer中的归纳偏置来提升其在小数据集上从随机初始化开始训练的识别性能。本文通过多种操作构建混合模型,增强视觉Transformer捕捉空间相关性的能力和其进行通道多样性表征的能力,弥补了Transformer在小数据集上从头训练的精度与传统的卷积神经网络之间的差距。目前该论文的代码处于待开源,在附录部分已有每个模块详细的伪代码展示。

卷积神经网络 (Convolutional Neural Networks, CNN) 作为骨干网络 (Backbone) 已经在计算机视觉领域占据主导地位相当长的一段时间。而近三年来视觉Transformer (Vision Transformers, ViT) 逐渐成为另一种典型的Backbone模型,在计算机视觉各个任务上取得了令人满意的效果。原版的ViT [1]需要现在JFT-300M这样大规模的数据集上预训练,然后在ImageNet-1K上进行微调才能取得较好的效果。以往对于ViT的改进方法,例如DeiT [2],T2T-ViT [3], CvT [4], Swin Transformer [5]等方法已经可以在ImageNet-1K上从头训练取得较好的效果,但在更小的数据集例如CIFAR-100上,从头训练的精度与CNN仍有较大差距。
本文归纳了以往研究[6, 7, 8]的观点,指出“训练数据的不足使得ViT无法在网络的浅层关注到局部区域”,进而对深层语义信息的提取与加工造成影响。此外“训练数据的不足还会使得ViT学习到的物体表征不够充分”,因而难以进行精确识别。针对上述两个问题,本文指出训练数据的缺乏使得ViT自身难以获得“空间相关性”与“通道多样性表征”两种归纳偏置,进而提出了多个模块来将归纳偏置引入ViT,极大地提升了其在小数据集上的识别性能。
(1)算法主框架:如图1所示,本文采用的是非金字塔型的Transformer结构,并使用class token进行分类。每个编码器层包含一个头交互的多头注意力 (Head-Interacted Multi-Head Self-Attention, HI-MHSA) 以及一个动态聚合前馈神经网络 (Dynamic Aggregation Feed Forward, DAFF). 在patch embedding部分采用了连续重叠的块嵌入模块 (Sequential Overlapped Patch Embedding, SOPE)。网络将最后一层输出的class token送入到线性分类头进行最后的识别。
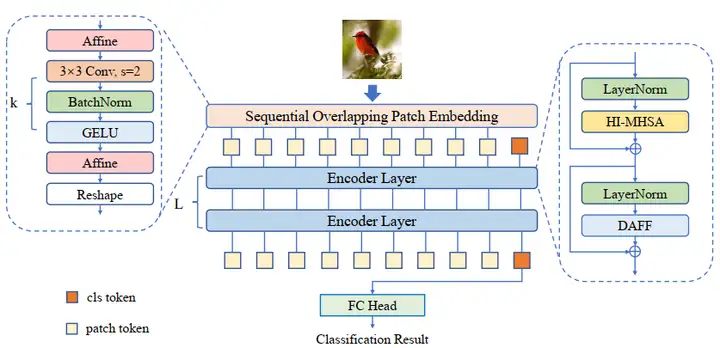
图1: 整体架构
(2)连续重叠的块嵌入模块SOPE:同目前其他主流的ViT一样,本文同样采用了卷积操作进行patch embedding。同时本文还引入了额外的仿射变换操作,增加在小数据集上训练时的稳定性。
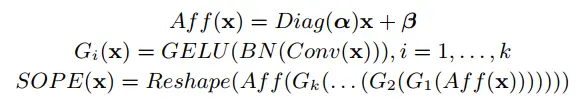
(3)动态聚合前馈神经网络DAFF:本文的在原版的前馈神经网络基础上进行改进,在两个线性层之间加入了深度卷积来进行领域信息的捕捉,弥补了ViT在空间上归纳偏置的不足。同时本文在卷积旁路采用了shortcut连接,维持了原有的全局信息。由于class token无法参与卷积计算,同时又希望对class token进行信息增强,因此作者引入了类似于通道注意力的操作,将卷积后的patch token进行全局平均池化与非线性映射,再逐通道对class token进行加权。
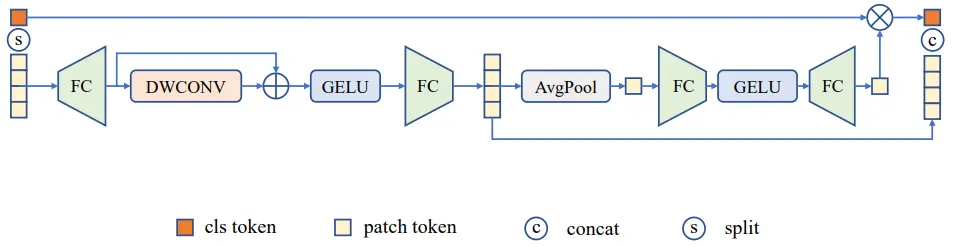
图2:DAFF结构
(4)头交互的多头注意力HI-MHSA:在ViT中,计算注意力时会将向量分成多个头,并在每个头中单独进行注意力的计算。由于数据量的不足,ViT所学习到的物体表征无法进行精确识别,每个头中所包含的物体表征相对较弱,因此本文额外引入了head token,旨在将各个头中较弱的物体表征融合形成足够强的表征。在数据送入多头注意力计算前,会先进行head token的提取。输入数据会根据设定的注意力头的数量,将数据划分成同等数量的分段,然后将每个分段重新映射成和原来一样的通道数。head token将会和其他所有token一起进行注意力的计算。此时每一个注意力头都会获得来自于其他注意力头的信息,将各个较弱的表征融合成了足以进行精确识别的物体表征。流程如图3所示。
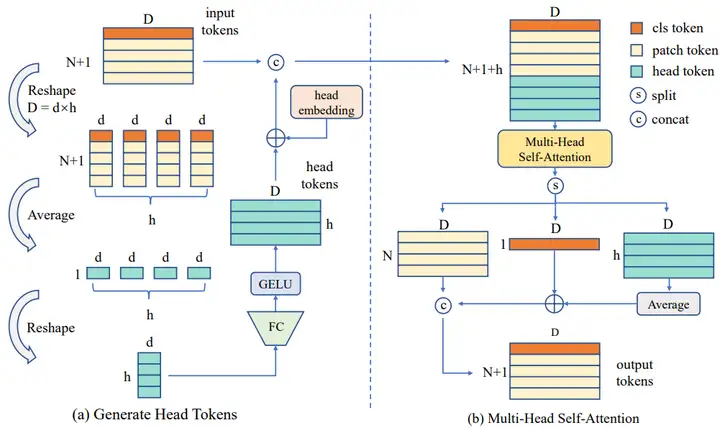
图3:HI-MHSA结构
本文在多个小数据集上进行“从头训练 (train from scratch)”,包含CIFAR-100以及多个DomainNet的数据集,同时还在ImageNet-1K上进行实验,证明本文方法在较大的数据集上同样有效。
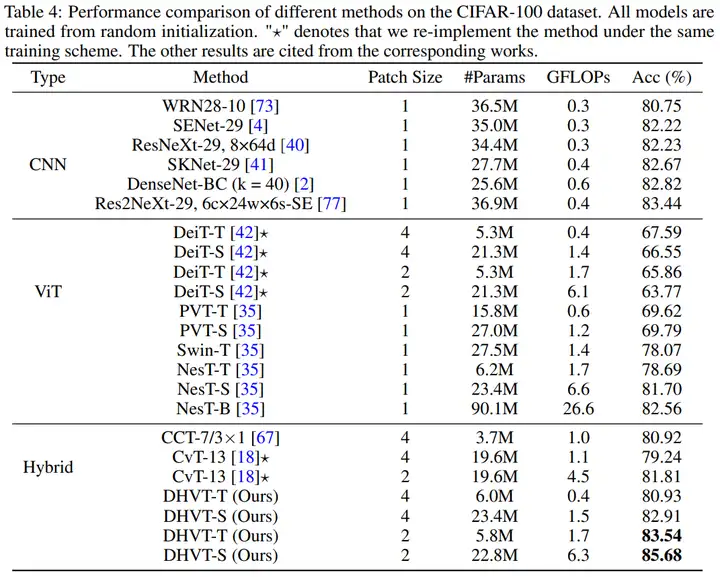
(1)在CIFAR-100上与SOTA的对比如下表。可以看到本文方法不仅可以超越以往所有ViT和Hybrid系列方法,同时还能以较少的参数量超越CNN的精度。
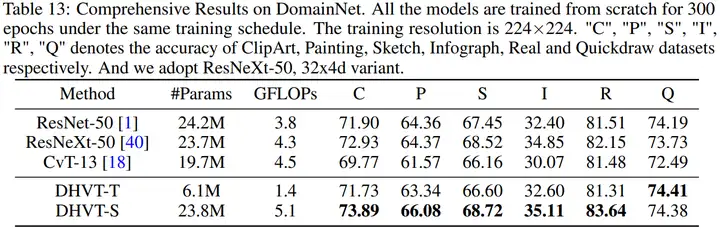
(2)DomainNet数据集的统计信息,以及各个方法在DomainNet数据集上的效果如下,同样展现了本文方法在精度上的优越性。

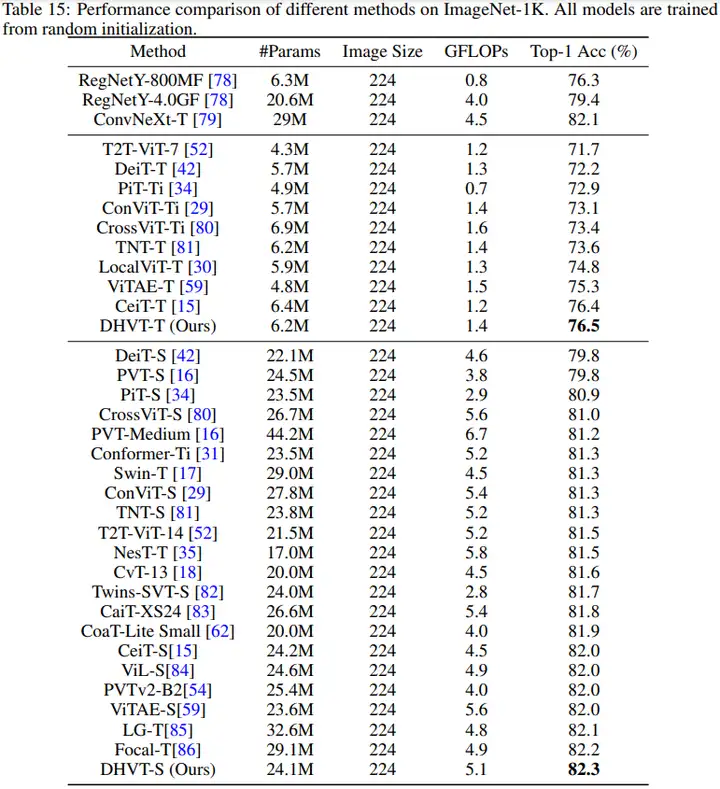
(3)本文方法与SOTA方法在ImageNet-1K上的对比结果如下。可以看到本文方法超越了以往所有的非金字塔型ViT模型,同时还能超越同期的较多金字塔型ViT模型。
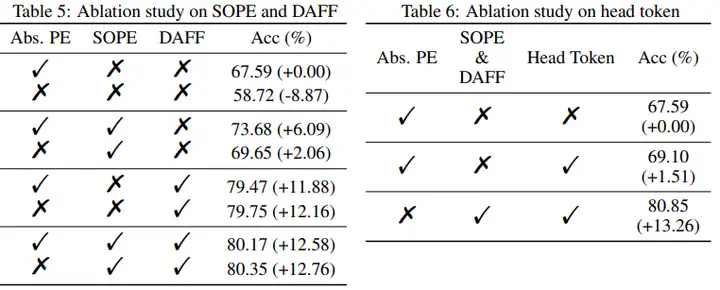
(4)消融实验部分同样展示了本文各个模块的有效性。
本文展示了注意力可视化结果。下图4展示了各个head token的注意力分布不同,表明了各个数据分段和注意力头对应不同的物体表征。

图4:head token的注意力可视化
本文还展示了在ImageNet-1K上训练出来的注意力分布,如图5所示。由于head token放在了其他token的后面,因此注意力图最右边的几列表示所有token对head token的注意力激活。
可以看到所有的token在网络的浅层时主要关注临近的token,提取局部信息。到了中间层,例如7-10层时,模型进行全局信息的交互,同时利用head token将各个head的表征融合在一起。到了最深层的11和12层,模型再次回归到全局信息的筛选,得到最终的分类信息表征。该图展示了一种可能的ViT信息提取方式,可能会对未来ViT模型的信息提取模式带来启发。

图5:DHVT-S在ImageNet-1K上的注意力可视化
本文通过弥补ViT模型所缺失的两种归纳偏置,极大地提升了其在小数据集上的分类精度,达到了与传统CNN持平甚至更好的效果。同时本文所引入的注意力交互机制可能会对未来研究产生启发。但本文的方法同样存在缺陷,例如优良的精度是以巨大的计算代价带来的,期待未来的后续工作能够探索到在计算负担和精度直接进行良好折中的方法。
论文地址:https://arxiv.org/pdf/2210.05958.pdf
代码链接:https://github.com/ArieSeirack/DHVT (待补全开源)
[1] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[2] Touvron H, Cord M, Douze M, et al. Training data-efficient image transformers & distillation through attention[C]//International Conference on Machine Learning. PMLR, 2021: 10347-10357.
[3] Yuan L, Chen Y, Wang T, et al. Tokens-to-token vit: Training vision transformers from scratch on imagenet[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 558-567.
[4] Wu H, Xiao B, Codella N, et al. Cvt: Introducing convolutions to vision transformers[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 22-31.
[5] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[6] Raghu M, Unterthiner T, Kornblith S, et al. Do vision transformers see like convolutional neural networks?[J]. Advances in Neural Information Processing Systems, 2021, 34: 12116-12128.
[7] Park N, Kim S. How Do Vision Transformers Work?[J]. arXiv preprint arXiv:2202.06709, 2022.
[8] d’Ascoli S, Touvron H, Leavitt M L, et al. Convit: Improving vision transformers with soft convolutional inductive biases[C]//International Conference on Machine Learning. PMLR, 2021: 2286-2296.