摘要:有序存储是指将数据按照某些字段排序后再存储。在此基础上,我们可以实现某些高性能算法,利用数据有序的特征来降低计算复杂度,从而大幅提高计算性能。
本文分享自华为云社区《有序存储对于高性能的意义》,作者: 陈橘又青 。
有序存储是指将数据按照某些字段排序后再存储。在此基础上,我们可以实现某些高性能算法,利用数据有序的特征来降低计算复杂度,从而大幅提高计算性能。
在查找计算中,我们常常要按某字段的等值条件找到目标记录。比如在订单表中找某个订单号,或者在交易表中找某个客户的交易记录等等。这种情况往往都出现在在线查询的场景中,要求秒级的响应速度,而且常常有较高的并发访问量。通常的应对手段是:预先为查找字段建立索引,查找时先利用索引找到目标记录在原表中的位置,再从原表中取出数据。
假如将原表数据按照查找字段有序存放,在计算时就可以实施二分法,不需要利用索引也可以获得很高的性能,实现免索引查找。假设数据总量为N,使用二分法进行查找的时间复杂度为logN(以2为底),当数据量越大,性能提升也就越明显。
esProc SPL 支持数据物理有序存储,可以实现这种免索引查找。SPL 语法也非常简捷,例如表 T 中的数据按照主键 id 有序存放,那么查找 id 为 10100 的记录代码只需要一句:
=file(“T.btx”).iselect@b(10100,id).fetch()
实际上,当符合等值条件的目标记录有较多条时,如果原表不采用有序存储方案,即使建立了索引也很难达到极致性能。这是因为,索引表通常是对查找字段有序的,在索引中查找会很快。但是,由于原表本身没有按照查找字段有序存储,要找的字段值可能会出现在原表的任何地方,所以在索引表得到的多个原表位置并不连续。而硬盘有最小读取单位,通常这个单位远大于一条记录占用的空间。在硬盘上读取不连续数据时,会取出很多无关内容,查找就会变慢。特别是高并发的情况下,每个查找都慢一点,总体性能就会很差了。
如果将原表按照查找字段有序存放,那么可以保证同一个查找值的记录集中在一起连续存储。查找时从硬盘上读取的数据块几乎全部都是目标值,性能自然会大幅提升。这种情况下的 SPL 代码也很简单,iselect 函数增加一个选项 @r 即可。
虽然预先排序比较慢,但是一次性的工作。如果某个表要经常作某字段的等值查找,这时候就可以对表先做一次排序,之后的多次查找即可获得更优良的性能。
数据量很大的分组计算也很常见,比如银行账户统计、电商漏斗分析、用户行为分析等等。这类计算的总数据量很大、分组数很多,但每组数据量却相对比较小。计算一般都是在每组内进行,不涉及其他组的数据。而且也并不都是求和、求平均这样的简单计算,很有可能是特别复杂的算法,需要写多步骤代码才能实现。所以,最好能将每个组的数据分别加载到内存中进行计算。
如果预先将数据按照分组字段排序后存储,在分组计算时,就可以按照顺序每次读入一组数据进行计算。这样,对硬盘的读取是连续的,性能可以得到保证。假设 T 表中的数据按照分组字段 gid 和时间 etime 有序,SPL 计算每组最早 3 条记录的类型计数代码大致是下面这样:
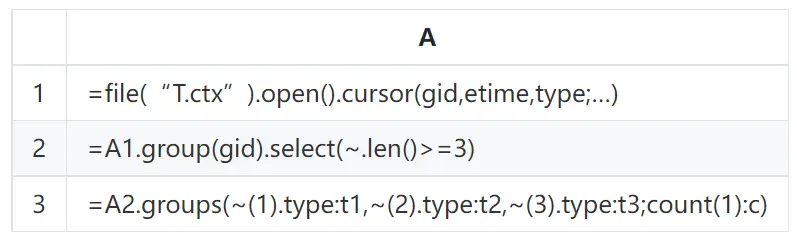
具体的场景和计算方法参见:SQL 提速:组内最早的 N 个事件统计。
SPL有序分组算法还非常适合特别复杂的计算,比如电商漏斗分析,可以大幅降低算法的复杂度,很容易就能做到代码简捷、性能卓越。详细介绍参见:电商漏斗如何跑得快。
经常出现性能问题的场景还有大数据表关联。对于大表关联,数据库通常使用哈希分堆算法,复杂度是乘法级的。而且,数据库做大数据的外存运算时,哈希分堆会产生缓存文件的读写动作,而硬盘的读写会大幅降低计算性能。
很多情况下大表都是按照主键或者主键的一部分做关联。如果预先将大表按照主键有序存放,就可以采用有序归并算法实现关联。有序归并算法复杂度是加法级,性能会比乘法级的哈希分堆算法好的多。而且,有序归并算法只需要对两个表依次遍历,不必借助外存缓存,可以大幅降低 IO 量,有巨大的性能优势。
假如 a、b 表预先按照主键有序存放,那么 SPL 有序归并算法实现连接运算的代码大致如下:

有序归并算法更详细的介绍参见这里:SPL 有序归并关联。
如果一个表的非主键字段和另一个表的主键字段关联,那么前者可以简称为事实表,后者为维表。假设事实表和维表都很大,做关联计算的时候是比较难以提高性能的。
对于这种情况,数据库一般仍采用哈希分堆的方法。即分别计算两个表中关联键的哈希值,将哈希值在一定范围的数据分到一堆,形成外存的缓存数据,保证每一堆都足够小可以装入内存,然后再逐个针对每一对堆(两个表)执行内存连接算法。这种方法会将两个大表都拆分缓存,也可以称为双边分堆方法。在哈希函数运气不好时,还可能发生某一堆过大而要再做第二轮哈希的情况。
如果将维表按照主键有序存储,就可以实施单边分堆机制来实现大维表关联。这种办法的好处是可以将维表平均分段,不会出现运气不好要二次哈希分堆的情况,缓存数据量要比双边分堆少的多,性能也会更优越。SPL 的代码大致是这样的:
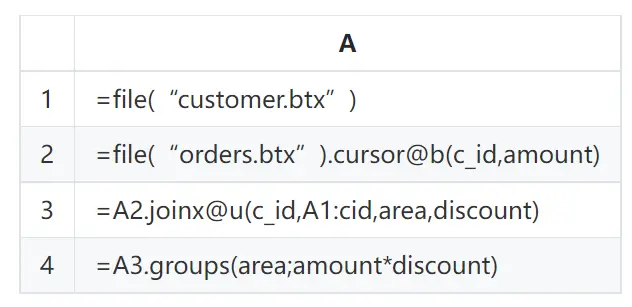
单边分堆的详细原理介绍参见这里:【性能优化】6.8 [外键关联] 单边分堆。
很多情况下,仅将数据按照一种方式有序存放是不够的。比如前面所说的查找计算,数据按照查找字段有序,那么性能会很好。但是,再按照其他非有序字段来作条件过滤时,性能就不理想了。理论上每个字段都有可能用于过滤,如果把数据按每个字段都排序,那相当于要被复制若干倍,这样的存储成本就有些高了。
一个较少冗余的办法是存储两份数据集。按字段 F1,…,Fn 排序后存储一份,再按 Fn,…,F1 排序存储一份,数据量会翻倍,还可以容忍。对于任何字段 F,总能有一个数据集使 F 在其排序维度列表中的前半部分。在查找时,即使查找字段不是排序的第一个字段,过滤后数据一般不能连成一片区域,但也是由一些相对较大的连续区域构成的。在排序字段列表中越靠前的字段,过滤后数据的物理有序程度就越高。
将同样的数据按照不同的排序方式冗余多份时,SPL 的 cgroups 函数会根据过滤条件字段来选择最合适的那份数据进行计算。详细的用法参见:多维分析后台实践 4:预汇总和冗余排序。
实际应用中,我们还可以将数据按照其他方式有序存储,也可以利用 SPL 写代码人为的选择合适的有序数据进行计算。