阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说)、深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云。更多精彩内容请单击此处。

摘要: GaussDB(DWS)支持根据业务系统的不同使用需求,对膨胀的数据进行冷热分级管理,将数据按照时间分为热数据、冷数据,这不仅可以提高数据分析性能还能降低业务成本。
本文分享自华为云社区《【云小课】EI第50课 GaussDB(DWS)数据存储尽在掌控,冷热数据切换自如》,作者:阅识风云

海量大数据场景下,随着业务和数据量的不断增长,数据存储与消耗的资源也日益增长。根据业务系统中用户对不同时期数据的不同使用需求,对膨胀的数据进行“冷热”分级管理,不仅可以提高数据分析性能还能降低业务成本。针对数据使用的一些场景,可以将数据按照时间分为:热数据、冷数据。
冷热数据主要从数据访问频率、更新频率进行划分。
冷热切换的策略支持LMT(last modify time)和HPN(hot partition number),LMT指按分区的最后更新时间切换,HPN指保留热分区的个数切换。
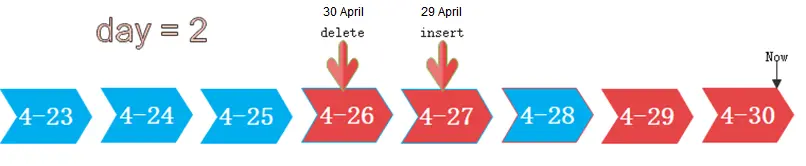
如下图中,设置day为2,即在冷热切换时,根据分区数据的最晚修改时间,保留2日内所修改的分区为热分区,其余数据为冷分区数据。假设当前时间为4月30日,4月30日对[4-26]分区进行了delete操作,4月29日对[4-27]分区进行了insert操作,故在冷热切换时,保留[4-26][4-27][4-29][4-30]四个分区为热分区。
如下图中,设置HPN为3,即在冷热切换时,保留最新的3个有数据的分区为热分区数据,其余分区均切为冷分区。

创建列存冷热数据管理表,指定热数据有效期LMT为100天。
CREATE TABLE lifecycle_table(i int, val text) WITH (ORIENTATION = COLUMN, storage_policy = 'LMT:100') PARTITION BY RANGE (i) ( PARTITION P1 VALUES LESS THAN(5), PARTITION P2 VALUES LESS THAN(10), PARTITION P3 VALUES LESS THAN(15), PARTITION P8 VALUES LESS THAN(MAXVALUE) ) ENABLE ROW MOVEMENT;复制
切换冷数据至OBS表空间。
可自定义自动切换时间:根据业务情况调整自动触发时间,修改为每天早晨6点30分:
select * from pg_obs_cold_refresh_time('lifecycle_table', '06:30:00'); pg_obs_cold_refresh_time -------------------------- SUCCESS (1 row)复制
执行如下操作手动切换单表:
alter table lifecycle_table refresh storage; ALTER TABLE复制
执行如下操作批量切换所有冷热表:
select pg_catalog.pg_refresh_storage(); pg_refresh_storage -------------------- (1,0) (1 row)复制
查看冷热表数据分布情况。
查看单表数据分布情况:
select * from pg_catalog.pg_lifecycle_table_data_distribute('lifecycle_table'); schemaname | tablename | nodename | hotpartition | coldpartition | switchablepartition | hotdatasize | colddatasize | switchabledatasize ------------+-----------------+--------------+--------------+---------------+---------------------+-------------+--------------+-------------------- public | lifecycle_table | dn_6001_6002 | p1,p2,p3,p8 | | | 96 KB | 0 bytes | 0 bytes public | lifecycle_table | dn_6003_6004 | p1,p2,p3,p8 | | | 96 KB | 0 bytes | 0 bytes public | lifecycle_table | dn_6005_6006 | p1,p2,p3,p8 | | | 96 KB | 0 bytes | 0 bytes (3 rows)复制
查看所有冷热表数据分布情况:
select * from pg_catalog.pg_lifecycle_node_data_distribute(); schemaname | tablename | nodename | hotpartition | coldpartition | switchablepartition | hotdatasize | colddatasize | switchabledatasize ------------+-----------------+--------------+--------------+---------------+---------------------+-------------+--------------+-------------------- public | lifecycle_table | dn_6001_6002 | p1,p2,p3,p8 | | | 98304 | 0 | 0 public | lifecycle_table | dn_6003_6004 | p1,p2,p3,p8 | | | 98304 | 0 | 0 public | lifecycle_table | dn_6005_6006 | p1,p2,p3,p8 | | | 98304 | 0 | 0 (3 rows)复制
了解更多华为云数据仓库GaussDB(DWS),请点击这里。
MapReduce服务为用户提供海量数据的管理及分析功能,快速从结构化和非结构化的海量数据中挖掘您所需要的价值数据。集群中的FusionInsight Manager将提供企业级的集群的统一管理平台。