摘要:用户创建hash分布表,使用pbe方式执行使用分布列作为查询条件的语句时报错
本文分享自华为云社区《GaussDB(DWS)现网案例之collation报错》,作者: 你是猴子请来的救兵吗 。
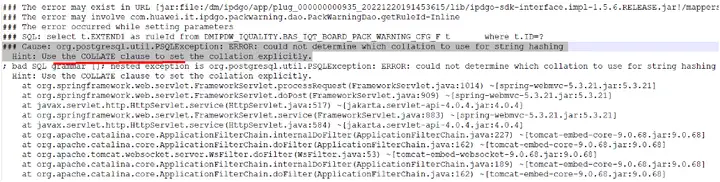
用户创建hash分布表,使用pbe方式执行使用分布列作为查询条件的语句时报错,ERROR: could not determine which collation to use for string hashing
内核版本:GaussDB 8.1.3
业务框架:jalor + mybatis
问题描述:用户创建hash分布表,使用pbe方式执行使用分布列作为查询条件的语句时报错,ERROR: could not determine which collation to use for string hashing
源表为hash分布表,当使用分布列作为查询条件时,可以通过节点分区剪枝提升性能;
分布列类型为nvarchar2(100),构造pbe剪枝语句时,需要对传入变量进行类型转换和精度转换,未正确更新collation,导致执行报错
drop table t1; create table t1(c1 nvarchar2(5),c2 varchar)with (orientation=column)distribute by hash(c1);--分布列类型为nvarchar2(n) insert into t1(c1) values(generate_series(1,10));复制
场景1:client + p/e
prepare c1(nvarchar2) as select c2 from t1 where c1 = $1; execute c1(5);复制
场景2:jdbc + p/b/e
PreparedStatement pstmt = con.prepareStatement("select c2 from t1 where c1 = ?;"); pstmt.setString(1, "5"); ResultSet rs = pstmt.executeQuery();复制
场景3:jalor + *Dao.*.xml
<delete id="query"> select c2 from t1 where c1 = #{c1} </delete>复制
任选一种既可,推荐第一种,改动小影响小
1,将分布列类型nvarchar2(n)修改为nvarchar2或varchar(n)
2,使用拼接sql的办法执行语句,而不是pbe
3,语句中指定collate子句,如select c2 from t1 where c1 collate "default" = ?;
4,升级版本
问题条件:
1,内核版本8.1.3 ≤ version ≤ 8.1.3.300
2,分布列包含nvarchar2(n)类型字段
3,使用pbe的方式执行语句
4,语句过滤条件包含所有分布列
规避方法:
打破以上任一条件即可规避