k8s 线上集群中 Node 节点状态变成 NotReady 状态,导致整个 Node 节点中容器停止服务。
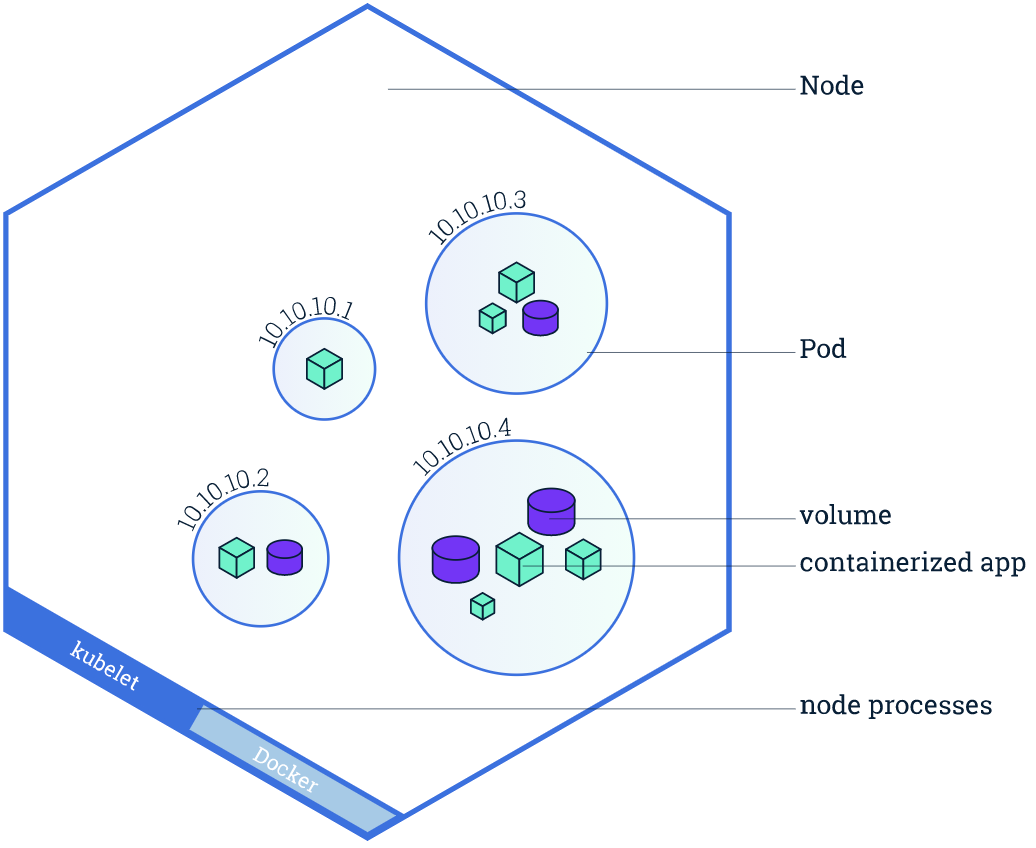
一个 Node 节点中是可以运行多个 Pod 容器,每个 Pod 容器可以运行多个实例 App 容器。Node 节点不可用,就会直接导致 Node 节点中所有的容器不可用,Node 节点是否健康,直接影响该节点下所有的实例容器的健康状态,直至影响整个 K8S 集群
# 查看节点的资源情况
[root@k8smaster ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8smaster 269m 13% 1699Mi 22%
k8snode1 1306m 65% 9705Mi 82%
k8snode2 288m 14% 8100Mi 68%
# 查看节点状态
[root@k8smaster ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster Ready master 33d v1.18.19
k8snode1 NotReady <none> 33d v1.18.19
k8snode2 Ready <none> 33d v1.18.19
# 查看节点日志
[root@k8smaster ~]# kubectl describe nodes k8snode1
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1 (50%) 7100m (355%)
memory 7378Mi (95%) 14556Mi (188%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning SystemOOM 30m kubelet System OOM encountered, victim process: java, pid: 29417
Warning SystemOOM 30m kubelet System OOM encountered, victim process: java, pid: 29418
Warning SystemOOM 30m kubelet System OOM encountered, victim process: java, pid: 29430
Warning SystemOOM 30m kubelet System OOM encountered, victim process: erl_child_setup, pid: 26391
Warning SystemOOM 30m kubelet System OOM encountered, victim process: beam.smp, pid: 26134
Warning SystemOOM 30m kubelet System OOM encountered, victim process: 1_scheduler, pid: 26392
Warning SystemOOM 29m kubelet System OOM encountered, victim process: java, pid: 28855
Warning SystemOOM 29m kubelet System OOM encountered, victim process: java, pid: 28637
Warning SystemOOM 28m kubelet System OOM encountered, victim process: java, pid: 29348
Normal NodeHasSufficientMemory 24m (x5 over 3h11m) kubelet Node k8snode1 status is now: NodeHasSufficientMemory
Normal NodeHasSufficientPID 24m (x5 over 3h11m) kubelet Node k8snode1 status is now: NodeHasSufficientPID
Normal NodeHasNoDiskPressure 24m (x5 over 3h11m) kubelet Node k8snode1 status is now: NodeHasNoDiskPressure
Warning SystemOOM 9m57s (x26 over 28m) kubelet (combined from similar events): System OOM encountered, victim process: java, pid: 30289
Normal NodeReady 5m38s (x9 over 30m) kubelet Node k8snode1 status is now: NodeReady
# 查看 pod 分在哪些节点上,发现 都在node1 上,【这是问题所在】
[root@k8smaster ~]# kubectl get pod,svc -n thothehp-test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/basic-67ffd66f55-zjrx5 1/1 Running 13 45h 10.244.1.89 k8snode1 <none> <none>
pod/c-api-69c786b7d7-m5brp 1/1 Running 11 3h53m 10.244.1.78 k8snode1 <none> <none>
pod/d-api-6f8948ccd7-7p6pb 1/1 Running 12 139m 10.244.1.82 k8snode1 <none> <none>
pod/gateway-5c84bc8775-pk86m 1/1 Running 7 25h 10.244.1.84 k8snode1 <none> <none>
pod/im-5fc6c47d75-dl9g4 1/1 Running 8 83m 10.244.1.86 k8snode1 <none> <none>
pod/medical-5f55855785-qr7r5 1/1 Running 12 83m 10.244.1.90 k8snode1 <none> <none>
pod/pay-5d98658dbc-ww4sg 1/1 Running 11 83m 10.244.1.88 k8snode1 <none> <none>
pod/elasticsearch-0 1/1 Running 0 80m 10.244.2.66 k8snode2 <none> <none>
pod/emqtt-54b6f4497c-s44jz 1/1 Running 5 83m 10.244.1.83 k8snode1 <none> <none>
pod/nacos-0 1/1 Running 0 80m 10.244.2.67 k8snode2 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/nacos-headless ClusterIP None <none> 8848/TCP,7848/TCP 45h app=nacos
service/service-basic ClusterIP None <none> 80/TCP 45h app=ehp-basic
service/service-c-api ClusterIP None <none> 80/TCP 3h53m app=ehp-cms-api
service/service-d-api ClusterIP None <none> 80/TCP 139m app=ehp-ds-api
service/service-gateway NodePort 10.101.194.234 <none> 80:30180/TCP 25h app=ehp-gateway
service/service-im ClusterIP None <none> 80/TCP 129m app=ehp-im
service/service-medical ClusterIP None <none> 80/TCP 111m app=ehp-medical
service/service-pay ClusterIP 10.111.162.80 <none> 80/TCP 93m app=ehp-pay
service/service-elasticsearch ClusterIP 10.111.74.111 <none> 9200/TCP,9300/TCP 2d3h app=elasticsearch
service/service-emqtt NodePort 10.106.201.96 <none> 61613:31616/TCP,8083:30804/TCP 2d5h app=emqtt
service/service-nacos NodePort 10.106.166.59 <none> 8848:30848/TCP,7848:31176/TCP 45h app=nacos
[root@k8smaster ~]#
复制加大内存,重启,内存加大后,会自动分配一些到 Node2 上面,也可以能过 label 指定某个 POD 选择哪个 Node 节点
# 需要重启docker
[root@k8snode1 ~]# systemctl restart docker
# 需要重启kubelet
[root@k8snode1 ~]# sudo systemctl restart kubelet
复制# 查看节点的资源情况
[root@k8smaster ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8smaster 269m 13% 1699Mi 22%
k8snode1 1306m 65% 9705Mi 82%
k8snode2 288m 14% 8100Mi 68%
复制