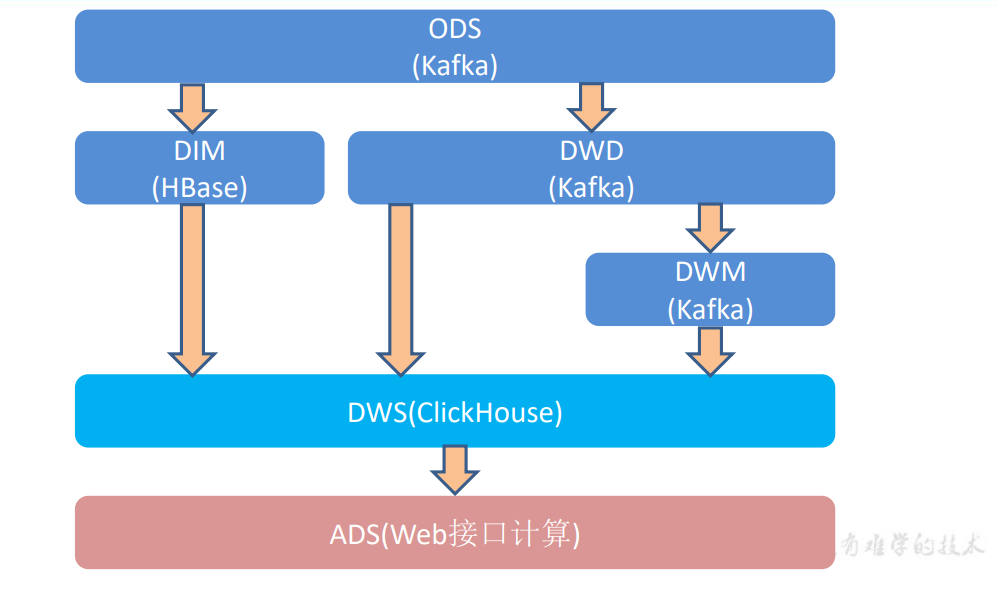
| 分层 | 全称 | 译名 | 说明 | 生成计算工具 | 存储媒介 | 压缩 | 列式存储 | 分区 |
|---|---|---|---|---|---|---|---|---|
| ODS | Operation Data Store | 原始层 | 原始数据 | FlinkCDC | Kafka | ✅ | ❌ | ✅ |
| DIM | Dimension | 维度层 | 合并维度表 | Flink | HBase | ✅ | ✅ | ✅ |
| DWD | Data Warehouse Detail | 明细层 | 数据处理、维度建模 | Flink | Kafka | ✅ | ✅ | ✅ |
| DWM | Data Warehouse Middle | 中间层 | 聚合 | Flink | Kafka | ✅ | ✅ | ✅ |
| DWS | Data Warehouse Service | 服务层 | 去主键聚合,得到原子指标 | Flink | Clickhouse | ✅ | ✅ | ✅ |
| DWT | Data Warehouse Topic | 主题层 | 存放主题对象的累积行为 | ✅ | ✅ | ✅ | ||
| ADS | Application Data Store | 应用层 | 具体业务指标 | Clickhouse | 可视化展示、用户画像、推荐系统、机器学习 | ❌ | ❌ | ❌ |
库名:业务大类
表名:分层名_业务细类
临时表:temp_表名
备份表:bak_表名
视图:view_表名(场景:不共享的维度表、即席查询)
| 分层 | 命名规范 | 说明 | 例 |
|---|---|---|---|
| ODS | ods+源类型+源表名+full/i | full:全量同步 i:增量同步 |
ods_postgresql_sku_full ods_mysql_order_detail_i ods_frontend_log |
| DIM | dim+维度+full/zip | full:全量表 zip:拉链表 日期维度表没有后缀 |
dim_sku_full dim_user_zip dim_date |
| DWD | dwd+事实+full/i | full:全量事实 i:增量事实 |
|
| DWS | dws+原子指标 | 时间粒度有1d、1h… 1d:按1天 1h:按1小时 |
dws_page_visitor_1d |
| DWT | dwt_消费者画像 | ||
| ADS | ads+衍生指标/派生指标 |
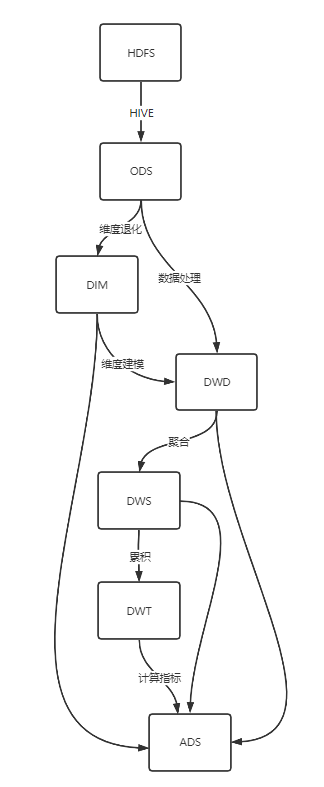
离线数仓:事实表,维度表,都放Hive
实时数仓:原始数据放 Kafka,维度数据 放 HBase,Phoenix
离线计算:就是在计算开始前已知所有输入数据,输入数据不会产生变化,一般计算量级较大,计算时间也较长。例如今天早上一点,把昨天累积的日志,计算出所需结果。最经典的就是 Hadoop 的 MapReduce 方式;
一般是根据前一日的数据生成报表,虽然统计指标、报表繁多,但是对时效性不敏感。从技术操作的角度,这部分属于批处理的操作。即根据确定范围的数据一次性计算。
实时计算:输入数据是可以以序列化的方式一个个输入并进行处理的,也就是说在开始的时候并不需要知道所有的输入数据。与离线计算相比,运行时间短,计算量级相对较小。强调计算过程的时间要短,即所查当下给出结果。
主要侧重于对当日数据的实时监控,通常业务逻辑相对离线需求简单一下,统计指标也少一些,但是更注重数据的时效性,以及用户的交互性。从技术操作的角度,这部分属于流处理的操作。根据数据源源不断地到达进行实时的运算。
即席查询: 需求的临时性,小李,把两星期的数据拉给我看下(只在这个时刻需要)
Presto: 当场计算(基于内存速度快)
Kylin:预计算(提前算好),多维分析(Hive With Cube)
Sqoop 导入数据方式:
增量: where 1=1、
全量: where 创建时间=当天、
新增及变化:where 创建时间=当天 or 操作时间=当天、
特殊(只导入一次)
Flume:
tailDirSource
优点:断点续传,监控多目录多文件
缺点:当文件更名之后,重新读取该文件造成数据重复
注意:1. 要使用不更名的打印日志框架(logback)--一般logback 也会设置成更名的,每天一个日志文件,文件名带上日期,如果写死文件名,更名后可能会丢数据
2.修改源码,让TailDirSource判断文件时,只看 iNode 值
KafkaChannel
优点:将数据导入Kafka,省了一层Sink
Kafka:生产者、消费者
用法:1. Source-KafkaChannel-Sink
2. Source-KafkaChannel
3. KafkaChannel-Sink
逻辑线: 数据流、监控、优化、配置。
Kafka
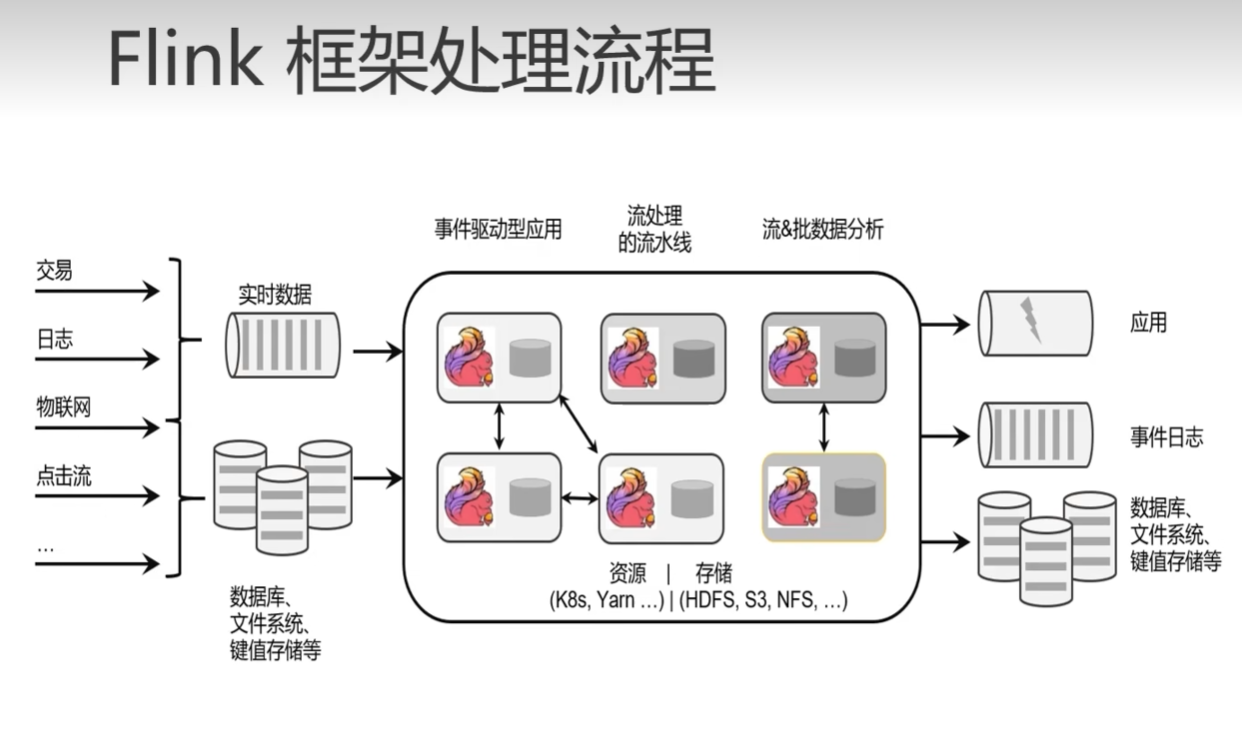
分层的好处
数据存储策略
离线架构:追求系统的稳定性、考虑到公司未来的发展,数据量一定会变得很大、早期的时间实时业务使用 SparkStreaming(微批次)
实时架构:Kafka集群高可用,数据量小,所有机器存在同一个机房,传输没有问题,
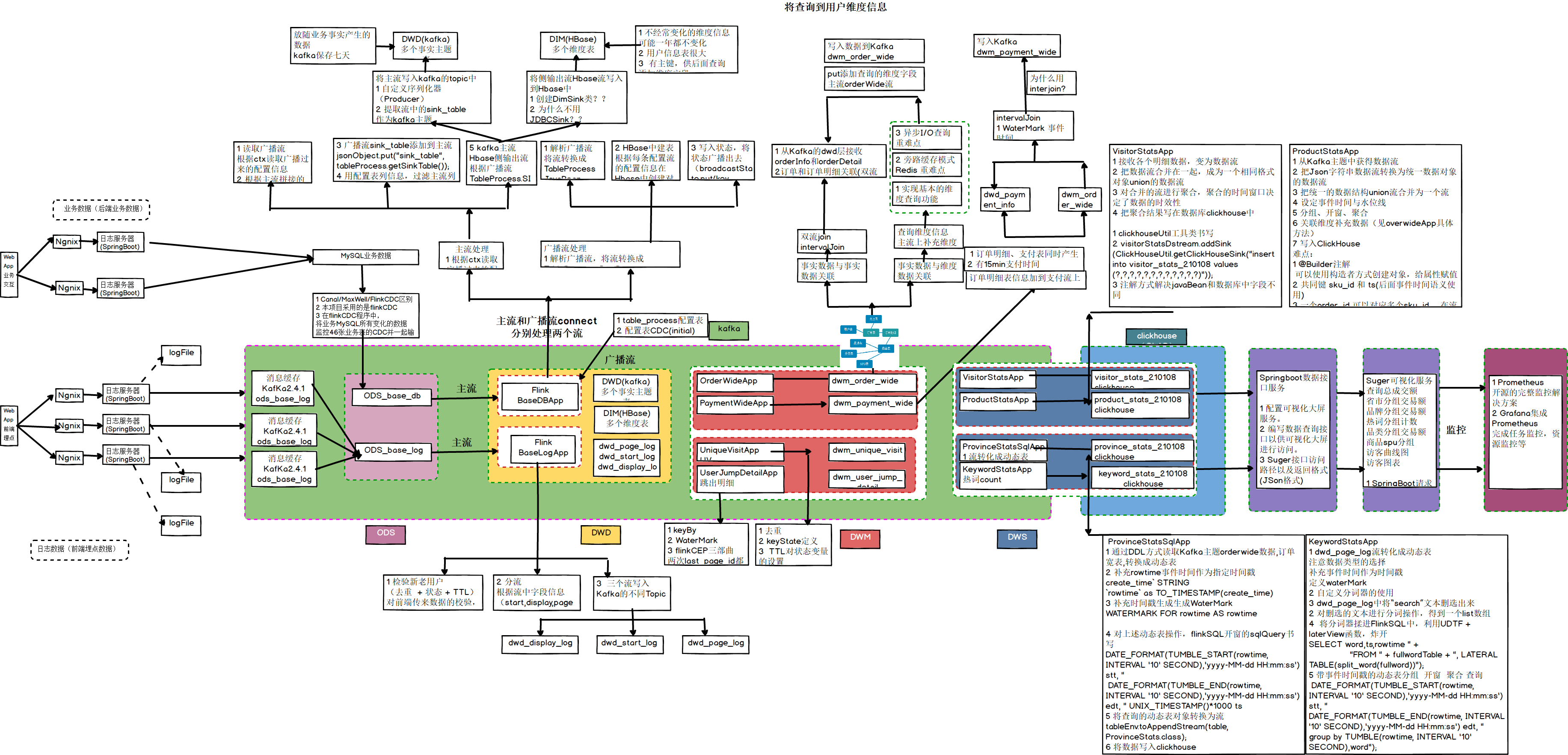
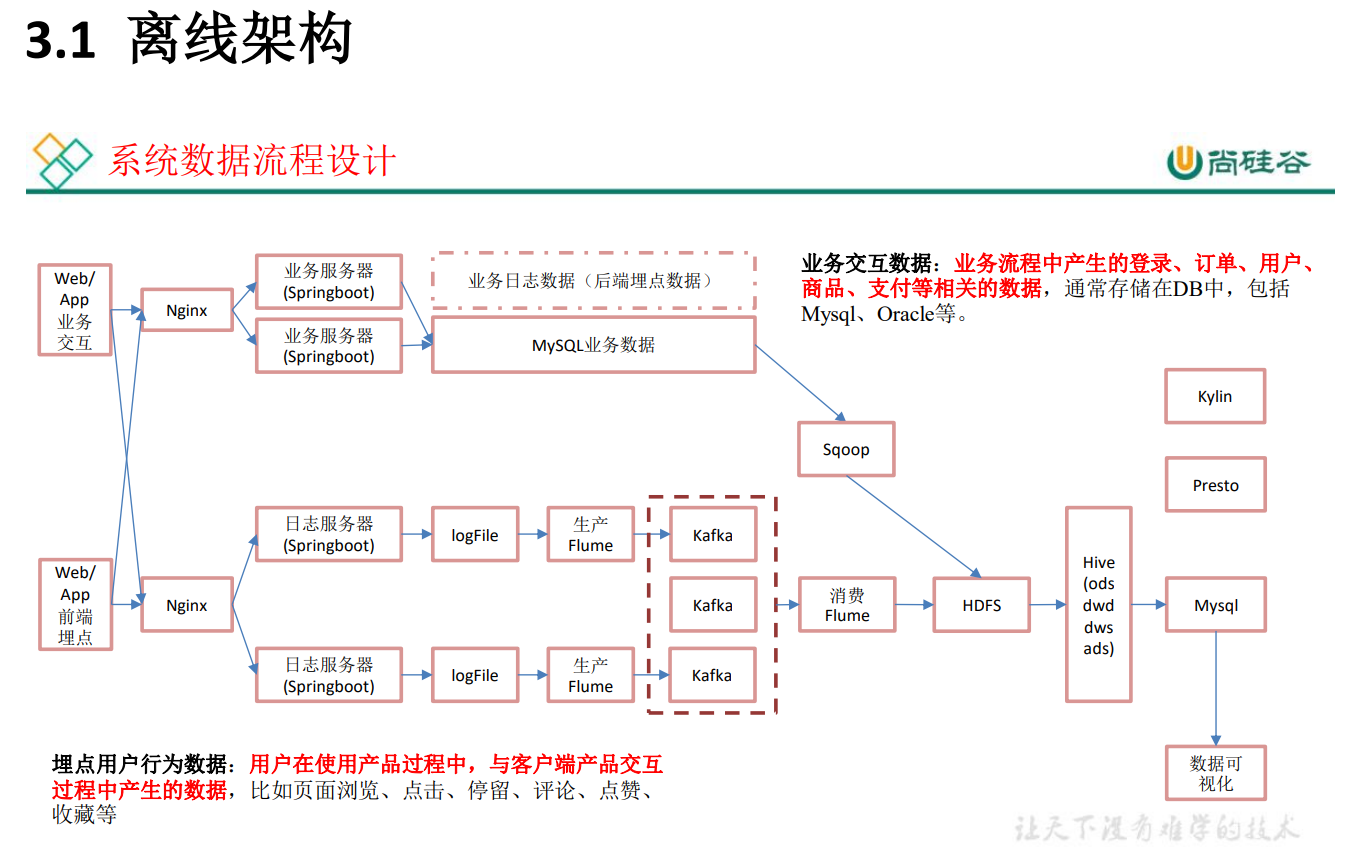
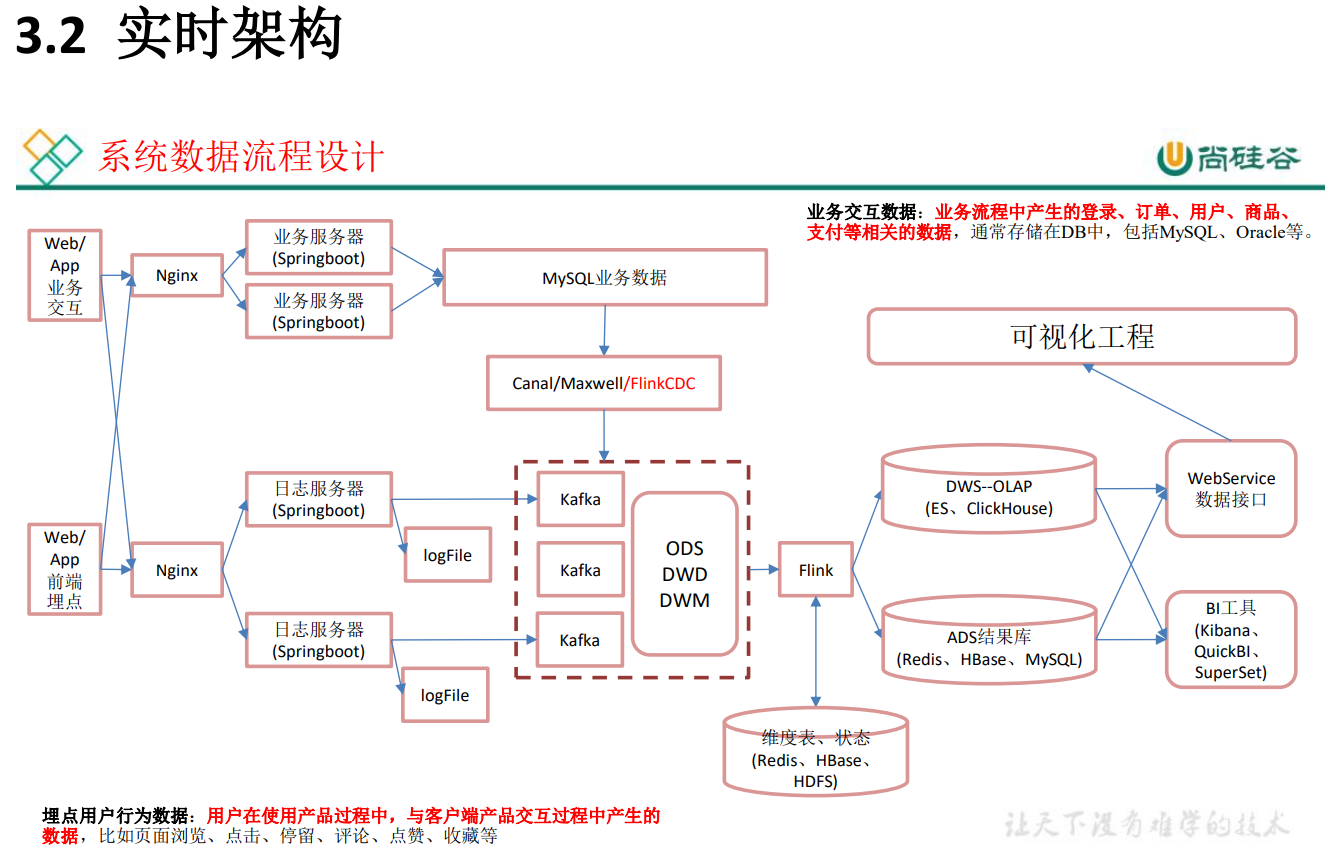
大数据-数据仓库-实时数仓架构分析
大数据-业务数据采集-FlinkCDC
大数据 - DWD&DIM 行为数据
大数据 - DWD&DIM 业务数据
大数据 DWM层 业务实现