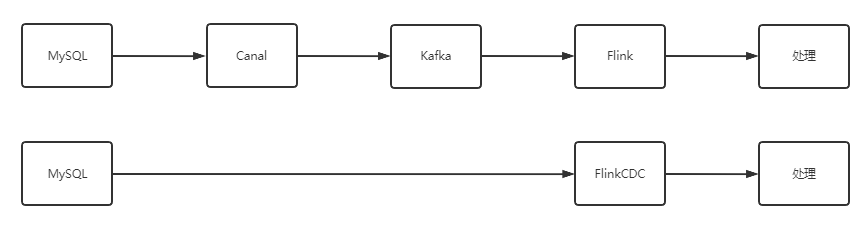
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
CDC 主要分为基于查询和基于 Binlog 两种方式,我们主要了解一下这两种之间的区别:
| 基于查询的 CDC | 基于 Binlog 的 CDC | |
|---|---|---|
| 开源产品 | Sqoop、Kafka JDBC Source | Canal、Maxwell、Debezium |
| 执行模式 | Batch | Streaming |
| 是否可以捕获所有数据变化 | 否 | 是 |
| 延迟性 | 高延迟 | 低延迟 |
| 是否增加数据库压力 | 是 | 否 |
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL 等数据库直接读取【全量数据】和【增量变更数据】的 source 组件。而不需要使用类似 Kafka 之类的中间件中转数据
目前也已开源,开源地址:https://github.com/ververica/flink-cdc-connectors
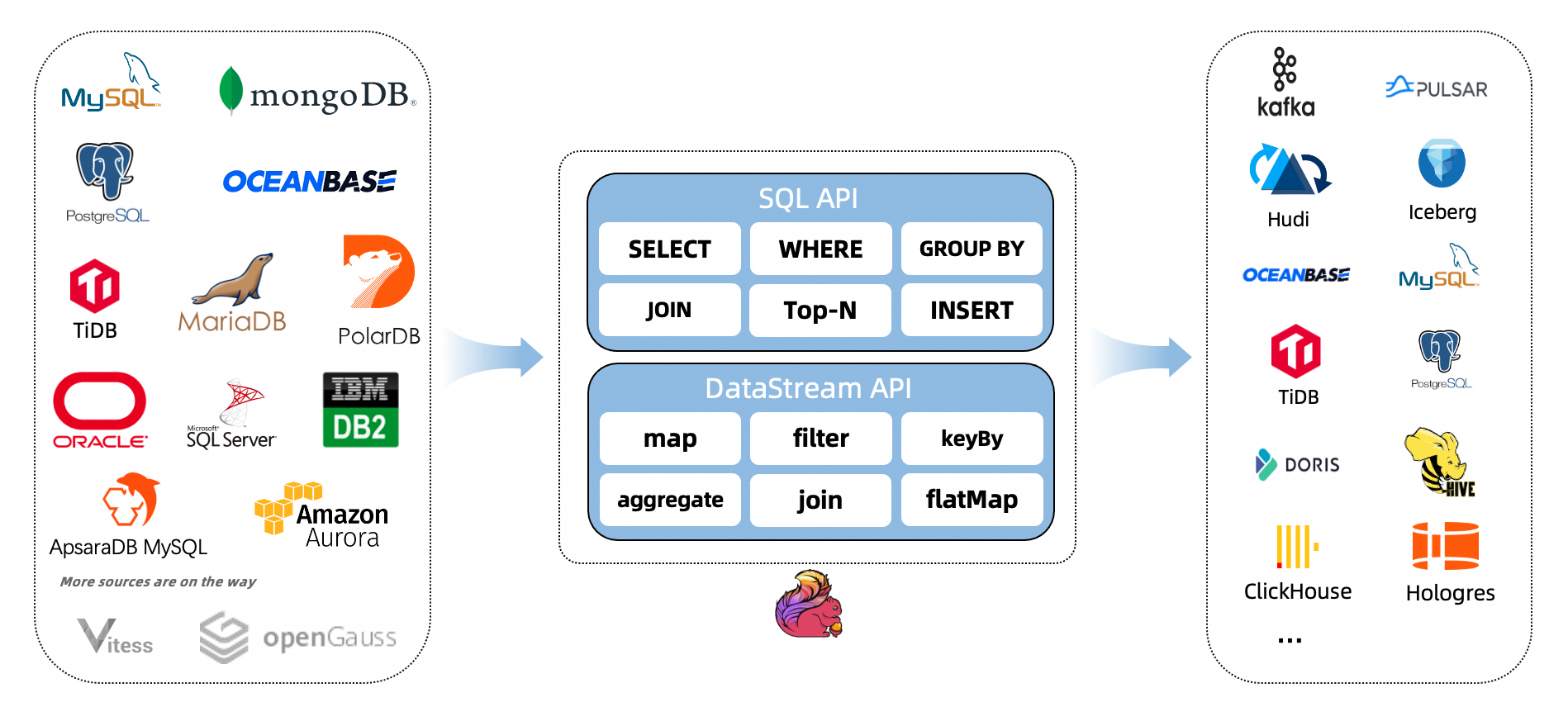
| Connector | Database | Driver |
|---|---|---|
| mongodb-cdc | MongoDB: 3.6, 4.x, 5.0 | MongoDB Driver: 4.3.1 |
| mysql-cdc | MySQL: 5.6, 5.7, 8.0.x RDS MySQL: 5.6, 5.7, 8.0.x PolarDB MySQL: 5.6, 5.7, 8.0.x Aurora MySQL: 5.6, 5.7, 8.0.x MariaDB: 10.x PolarDB X: 2.0.1 |
JDBC Driver: 8.0.27 |
| oceanbase-cdc | OceanBase CE: 3.1.x OceanBase EE (MySQL mode): 2.x, 3.x |
JDBC Driver: 5.1.4x |
| oracle-cdc | Oracle: 11, 12, 19 | Oracle Driver: 19.3.0.0 |
| postgres-cdc | PostgreSQL: 9.6, 10, 11, 12 | JDBC Driver: 42.2.12 |
| sqlserver-cdc | Sqlserver: 2012, 2014, 2016, 2017, 2019 | JDBC Driver: 7.2.2.jre8 |
| tidb-cdc | TiDB: 5.1.x, 5.2.x, 5.3.x, 5.4.x, 6.0.0 | JDBC Driver: 8.0.27 |
| db2-cdc | Db2: 11.5 | DB2 Driver: 11.5.0.0 |
DataStream:
注意开启 binlog_format=ROW
my.ini
log-bin=mysql-bin
#binlog_format="STATEMENT"
binlog_format="ROW"
#binlog_format="MIXED"
#service-id=1
复制
POM
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
</dependencies>
复制CustomerDeserialization.java
package com.vipsoft;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
/**
* 封装的数据格式
* {
* "database":"",
* "tableName":"",
* "before":{"id":"","tm_name":""....},
* "after":{"id":"","tm_name":""....},
* "type":"c u d",
* //"ts":156456135615
* }
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//1.创建JSON对象用于存储最终数据
JSONObject result = new JSONObject();
//2.获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
Struct value = (Struct) sourceRecord.value();
//3.获取"before"数据
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List<Field> beforeFields = beforeSchema.fields();
for (Field field : beforeFields) {
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
//4.获取"after"数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List<Field> afterFields = afterSchema.fields();
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
//5.获取操作类型 CREATE UPDATE DELETE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("create".equals(type)) {
type = "insert";
}
//6.将字段写入JSON对象
result.put("database", database);
result.put("tableName", tableName);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("type", type);
//7.输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
复制FlinkCDC.java
package com.vipsoft;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.通过FlinkCDC构建SourceFunction并读取数据
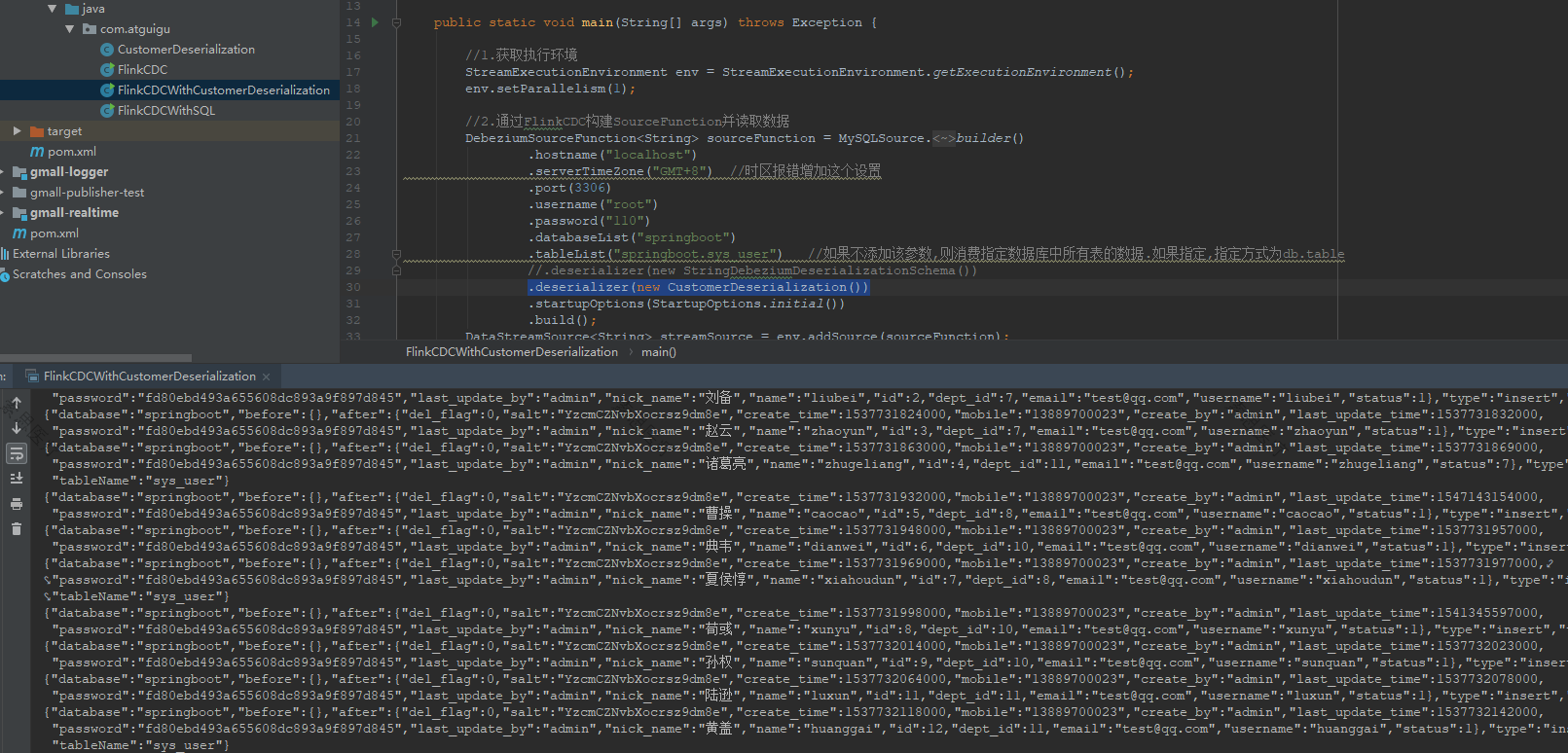
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("localhost")
.serverTimeZone("GMT+8") //时区报错增加这个设置
.port(3306)
.username("root")
.password("110")
.databaseList("springboot")
.tableList("springboot.sys_user") //如果不添加该参数,则消费指定数据库中所有表的数据.如果指定,指定方式为db.table
//.deserializer(new StringDebeziumDeserializationSchema())
.deserializer(new CustomerDeserialization()) //使用自定义反序列化器
.startupOptions(StartupOptions.initial())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//3.打印数据
streamSource.print();
//4.启动任务
env.execute("FlinkCDC");
}
}
复制
package com.vipsoft;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkCDCWithSQL {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.DDL方式建表
tableEnv.executeSql("CREATE TABLE mysql_binlog ( " +
" id STRING NOT NULL, " +
" username STRING, " +
" nick_name STRING " +
") WITH ( " +
" 'connector' = 'mysql-cdc', " +
" 'hostname' = 'localhost', " +
" 'port' = '3306', " +
" 'username' = 'root', " +
" 'password' = '110', " +
" 'database-name' = 'springboot', " +
" 'table-name' = 'sys_user' " +
")");
//3.查询数据
Table table = tableEnv.sqlQuery("select * from mysql_binlog");
//4.将动态表转换为流
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnv.toRetractStream(table, Row.class);
retractStream.print();
//5.启动任务
env.execute("FlinkCDCWithSQL");
}
}
复制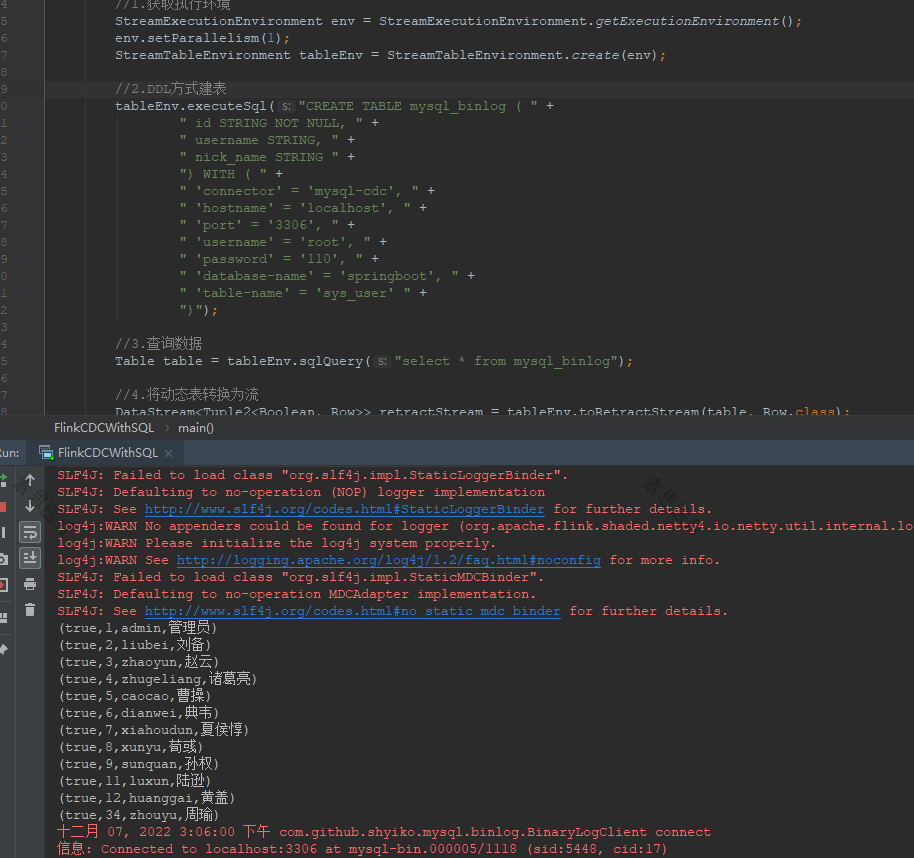
通过对比,FlinkCDC 最舒服
| FlinkCDC | Maxwell | Canal | |
|---|---|---|---|
| 断点续传 | CK | MySQL | 本地磁盘 |
| SQL -> 数据 | 无 | 无 | 一对一(炸开处理) |
| 初始化功能 | 有(多库多表) | 有(单表) | 无(单独查询历史数据) |
| 封装格式 | 自定义 | JSON | JSON(c/s自定义) |
| 高可用 | 运行集群高可用 | 无 | 集群(ZK) |
插入两条数据
INSER INTO z_user_info VALUES(30,'zhang3','13800000000'),(31,'li4','13999999999')
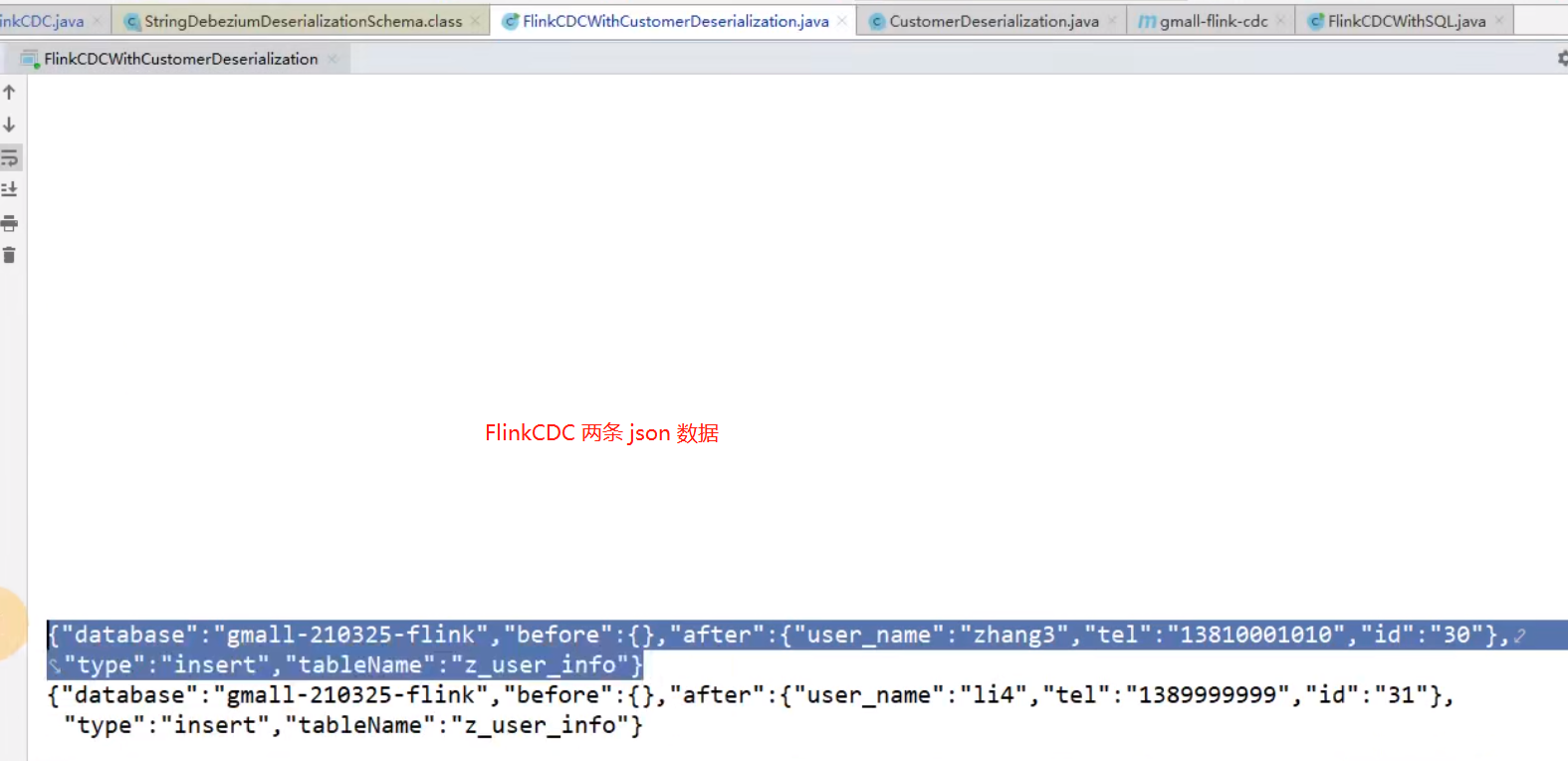
复制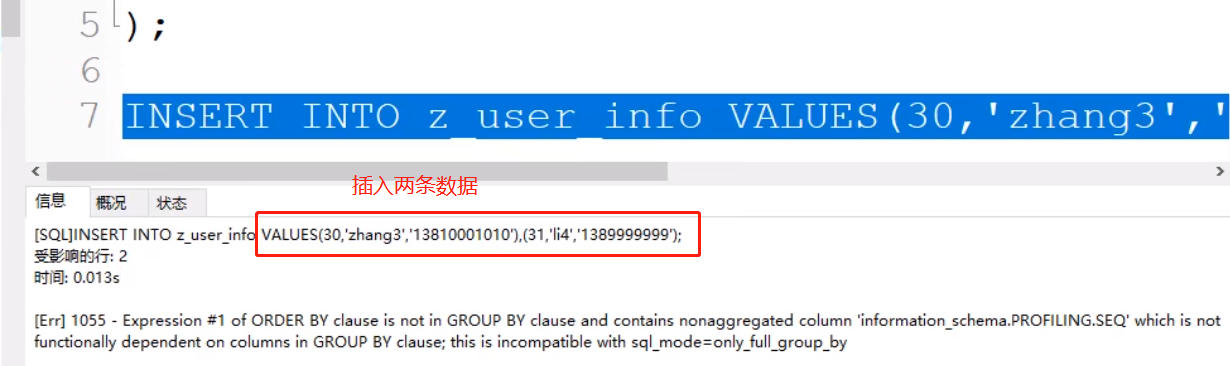
FlinkCDC 每条变化都会产生一条 json
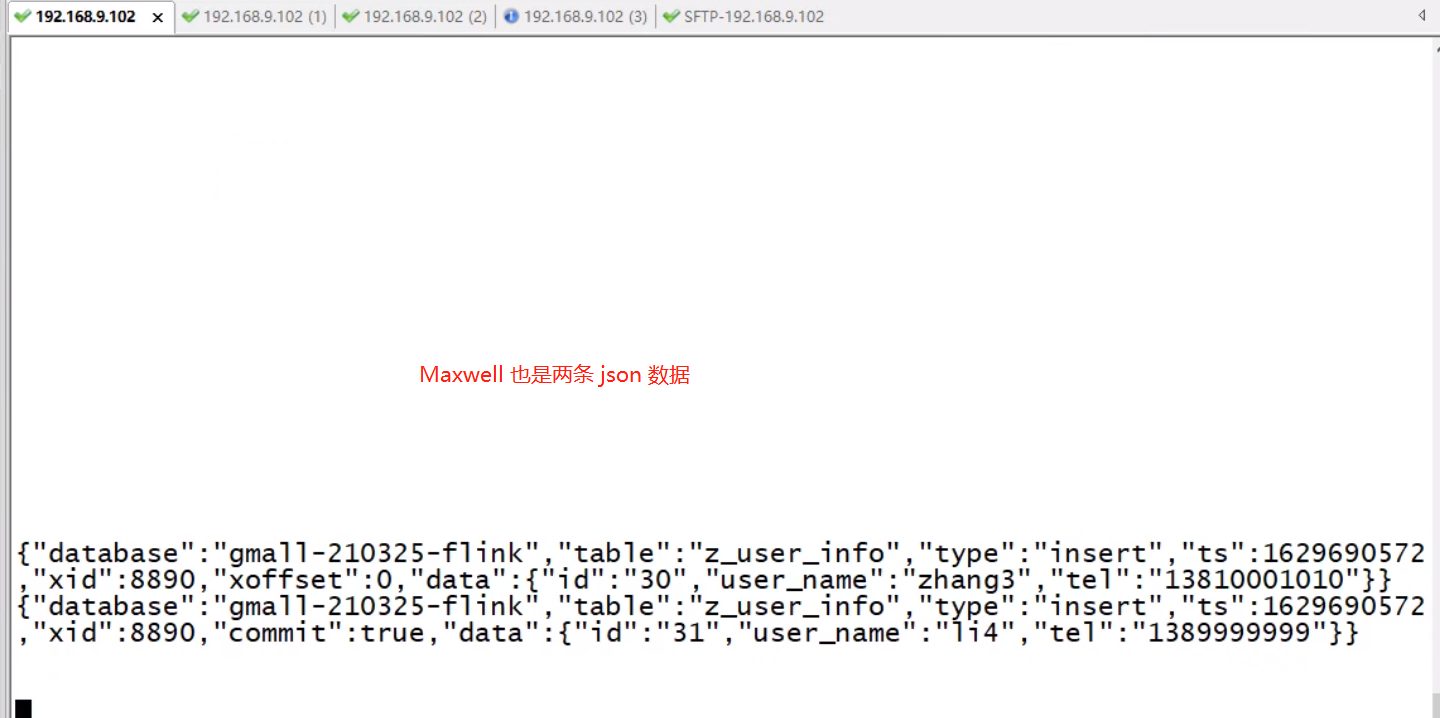
Maxwell 每条变化都会产生一条 json
Canal 一次性执行的SQL,会产生一条JSON(两条数据组合在一起)【不方便,需要炸开解析】

UPDATE z_user_info SET user_name='wang5' WHERE id IN(30,31)
复制FlinkCDC 包括了修改前的 before 数据

Maxwell 不包括修改前的数据
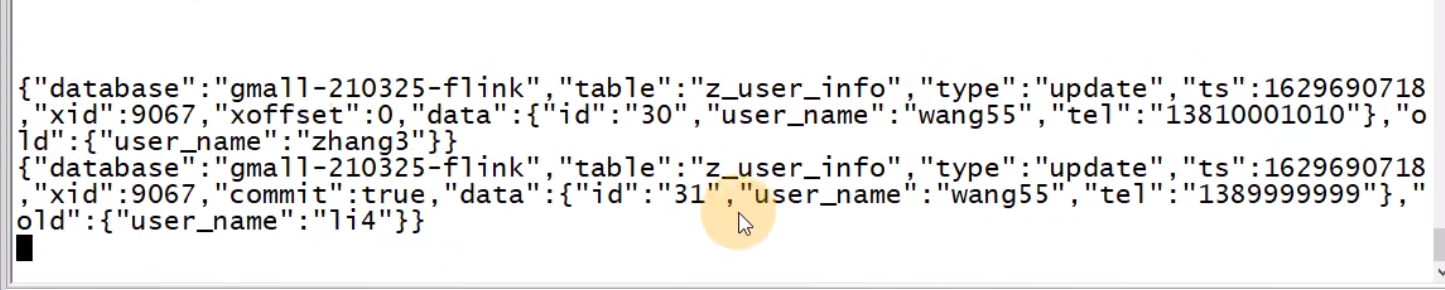
Canal 仍然是一条json

DELETE FROM z_user_info WHERE id IN(30,31)
复制FlinkCDC 两条删除的 json 数据

Maxwell

Canal

大数据-数据仓库-实时数仓架构分析
大数据-业务数据采集-FlinkCDC
大数据 - DWD&DIM 行为数据
大数据 - DWD&DIM 业务数据
大数据 DWM层 业务实现