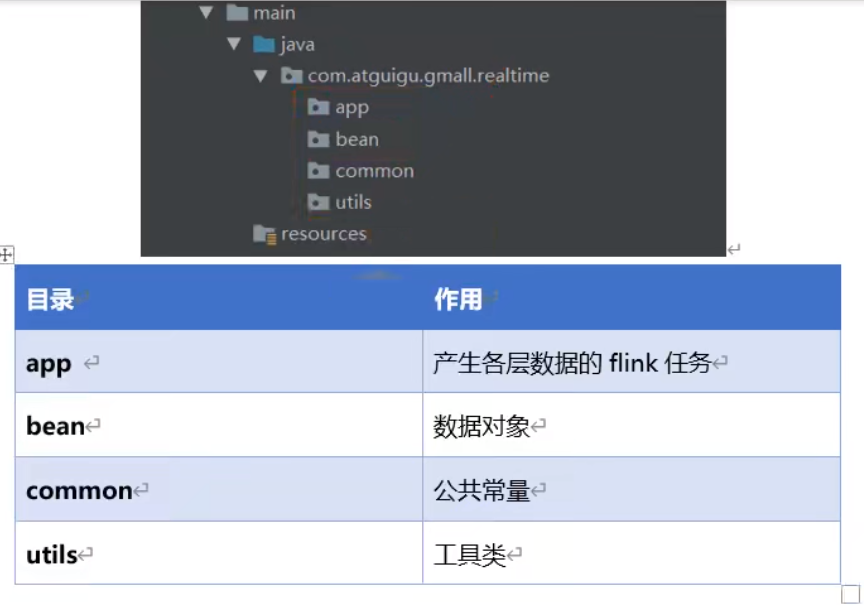
| 目录 | 作用 |
|---|---|
| app | 产生各层数据的 flink 任务 |
| bean | 数据对象 |
| common | 公共常量 |
| utils | 工具类 |
app.ods.FlinkCDC.java
package com.atguigu.app.ods;
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.atguigu.app.function.CustomerDeserialization;
import com.atguigu.utils.MyKafkaUtil;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 设置CK&状态后端
//env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/gmall-flink-210325/ck"));
//env.enableCheckpointing(5000L);
//env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//env.getCheckpointConfig().setCheckpointTimeout(10000L);
//env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
//env.getCheckpointConfig().setMinPauseBetweenCheckpoints(3000);
//env.setRestartStrategy(RestartStrategies.fixedDelayRestart());
//2.通过FlinkCDC构建SourceFunction并读取数据
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("hadoop102")
.port(3306)
.username("root")
.password("000000")
.databaseList("gmall-210325-flink")
.deserializer(new CustomerDeserialization())
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//3.打印数据并将数据写入Kafka
streamSource.print();
String sinkTopic = "ods_base_db";
streamSource.addSink(MyKafkaUtil.getKafkaProducer(sinkTopic));
//4.启动任务
env.execute("FlinkCDC");
}
}
复制CustomerDeserialization
package com.atguigu.app.function;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.List;
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
/**
* 封装的数据格式
* {
* "database":"",
* "tableName":"",
* "before":{"id":"","tm_name":""....},
* "after":{"id":"","tm_name":""....},
* "type":"c u d",
* //"ts":156456135615
* }
*/
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//1.创建JSON对象用于存储最终数据
JSONObject result = new JSONObject();
//2.获取库名&表名
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
Struct value = (Struct) sourceRecord.value();
//3.获取"before"数据
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List<Field> beforeFields = beforeSchema.fields();
for (Field field : beforeFields) {
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
//4.获取"after"数据
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List<Field> afterFields = afterSchema.fields();
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
//5.获取操作类型 CREATE UPDATE DELETE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("create".equals(type)) {
type = "insert";
}
//6.将字段写入JSON对象
result.put("database", database);
result.put("tableName", tableName);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("type", type);
//7.输出数据
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}
复制MyKafkaUtil
package com.atguigu.utils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.KafkaSerializationSchema;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import javax.annotation.Nullable;
import java.util.Properties;
public class MyKafkaUtil {
private static String brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092";
private static String default_topic = "DWD_DEFAULT_TOPIC";
public static FlinkKafkaProducer<String> getKafkaProducer(String topic) {
return new FlinkKafkaProducer<String>(brokers,
topic,
new SimpleStringSchema());
}
public static <T> FlinkKafkaProducer<T> getKafkaProducer(KafkaSerializationSchema<T> kafkaSerializationSchema) {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaProducer<T>(default_topic,
kafkaSerializationSchema,
properties,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE);
}
public static FlinkKafkaConsumer<String> getKafkaConsumer(String topic, String groupId) {
Properties properties = new Properties();
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
return new FlinkKafkaConsumer<String>(topic,
new SimpleStringSchema(),
properties);
}
//拼接Kafka相关属性到DDL
public static String getKafkaDDL(String topic, String groupId) {
return " 'connector' = 'kafka', " +
" 'topic' = '" + topic + "'," +
" 'properties.bootstrap.servers' = '" + brokers + "', " +
" 'properties.group.id' = '" + groupId + "', " +
" 'format' = 'json', " +
" 'scan.startup.mode' = 'latest-offset' ";
}
}
复制