大数据 ODS&DWD&DIM-SQL分享 需求
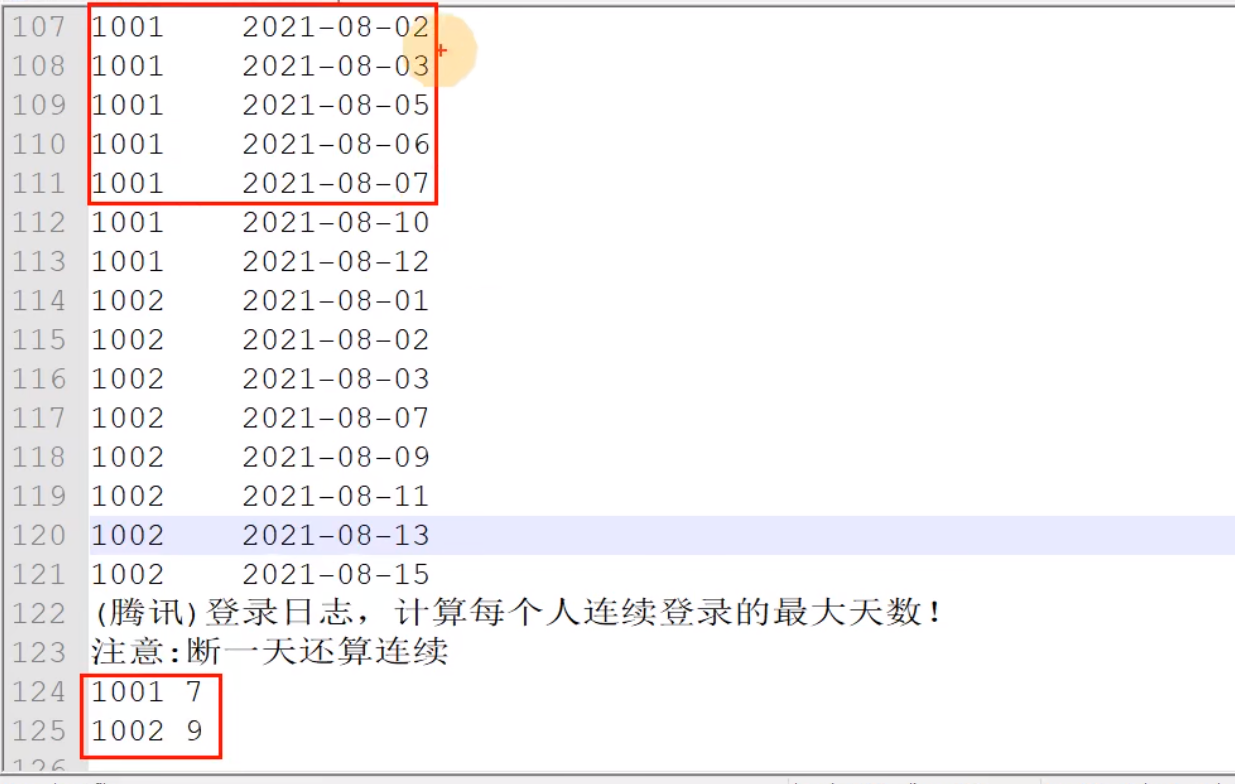
断2天、3天,嵌套太多
-- linux 中空格不能用 tab 键
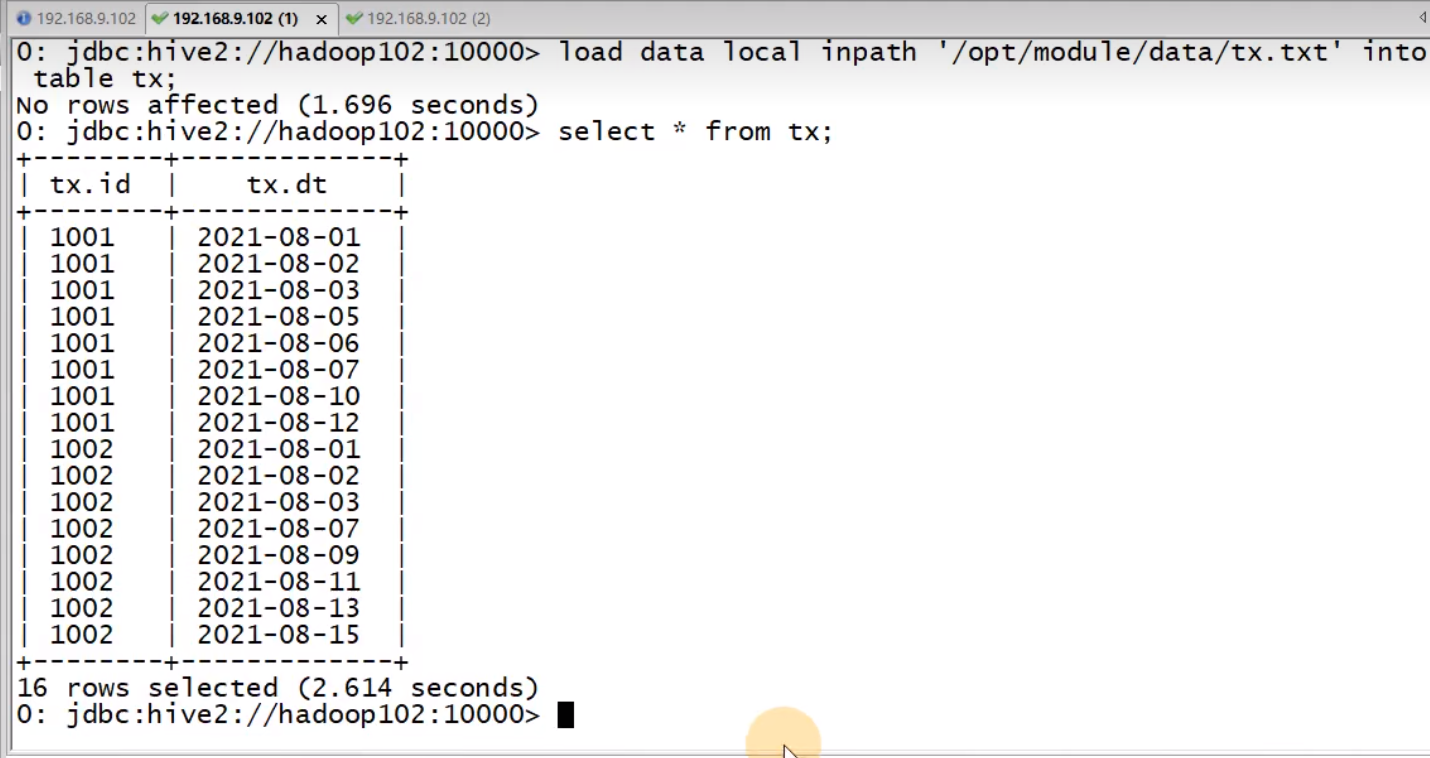
select id,dt,rank() over(partition by id order by dt) rk from tx;
复制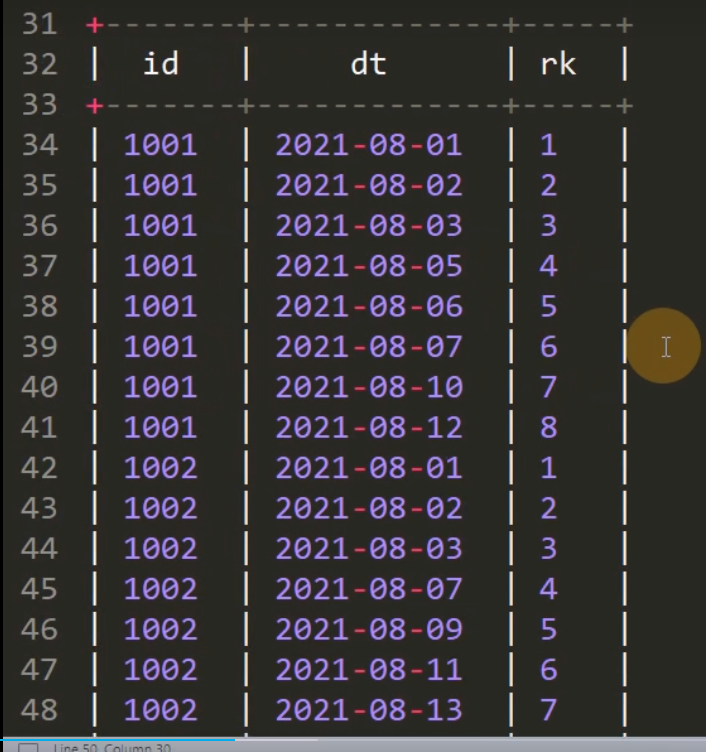
z: 等差
(x1+z)-(y1+z)=x1-y1
select id,dt,date_sub(dt,rk) flg
from (select id,dt,rank() over(partition by id order by dt) rk from tx) t1;
复制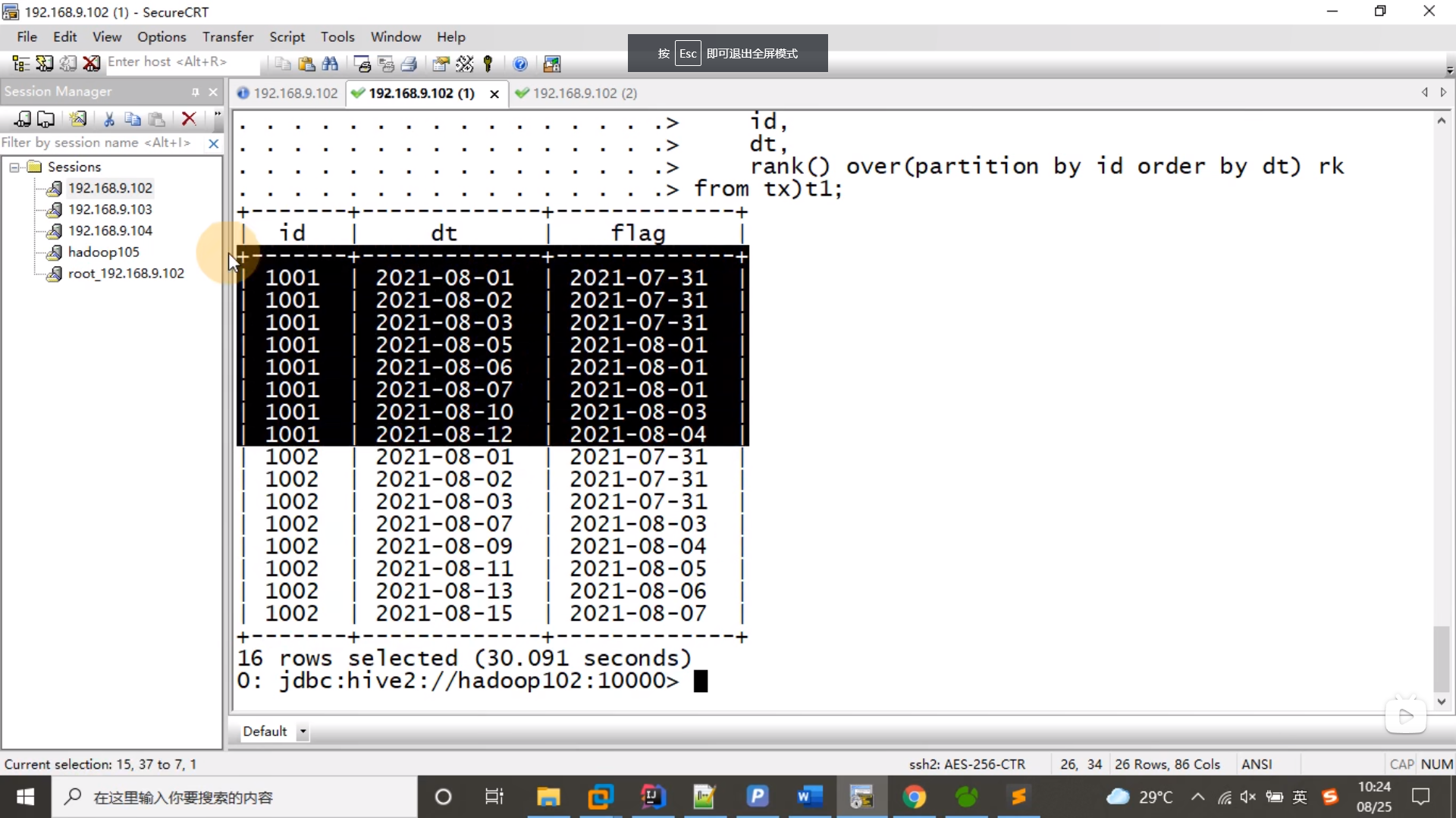
断一天的数据,flag 变成了连续
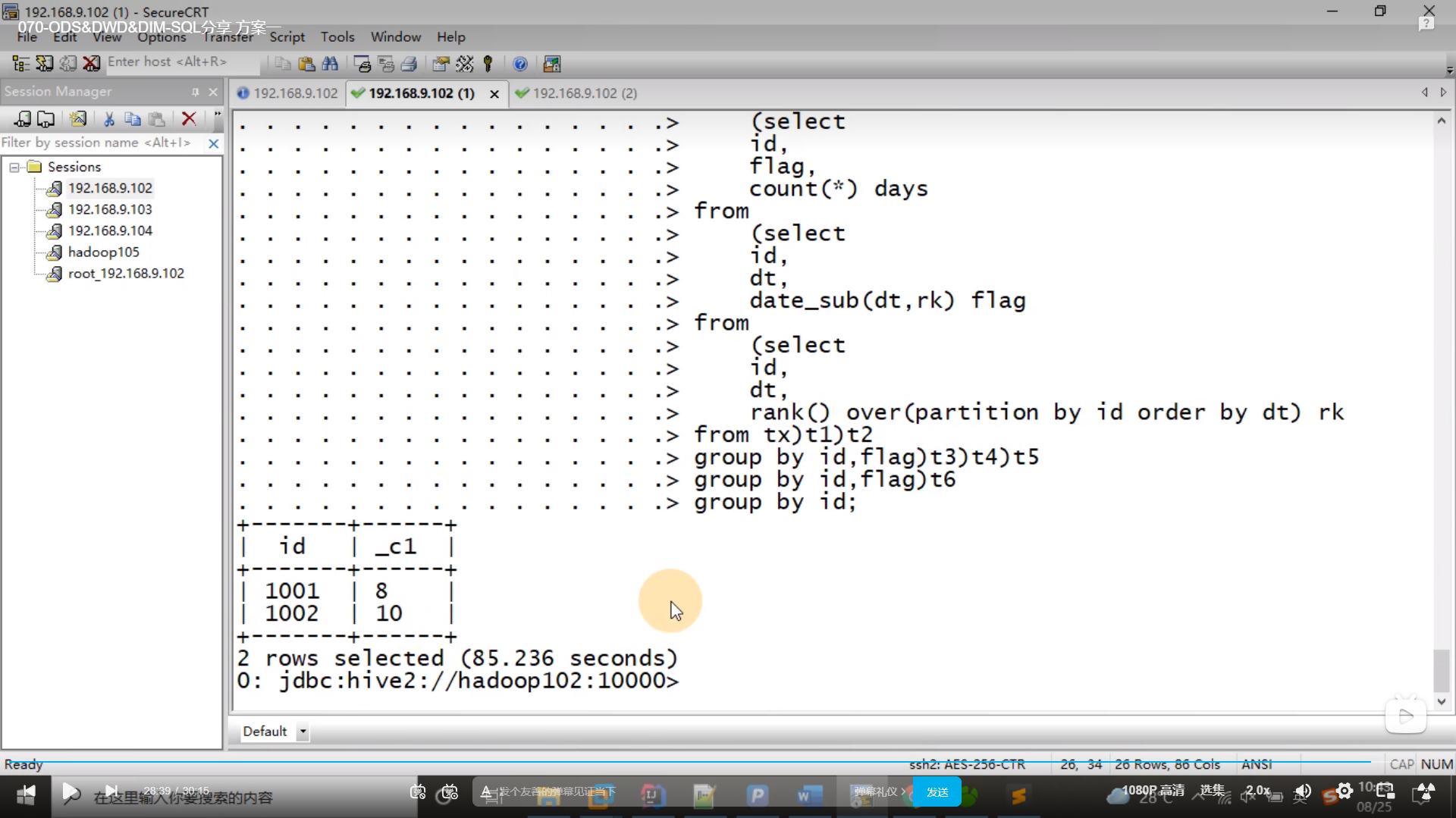
select id,flag,count(*) days
from (
select id,dt,date_sub(dt,rk) flg
from (select id,dt,rank() over(partition by id order by dt) rk from tx) t1;
)t2 group by id,flag;
复制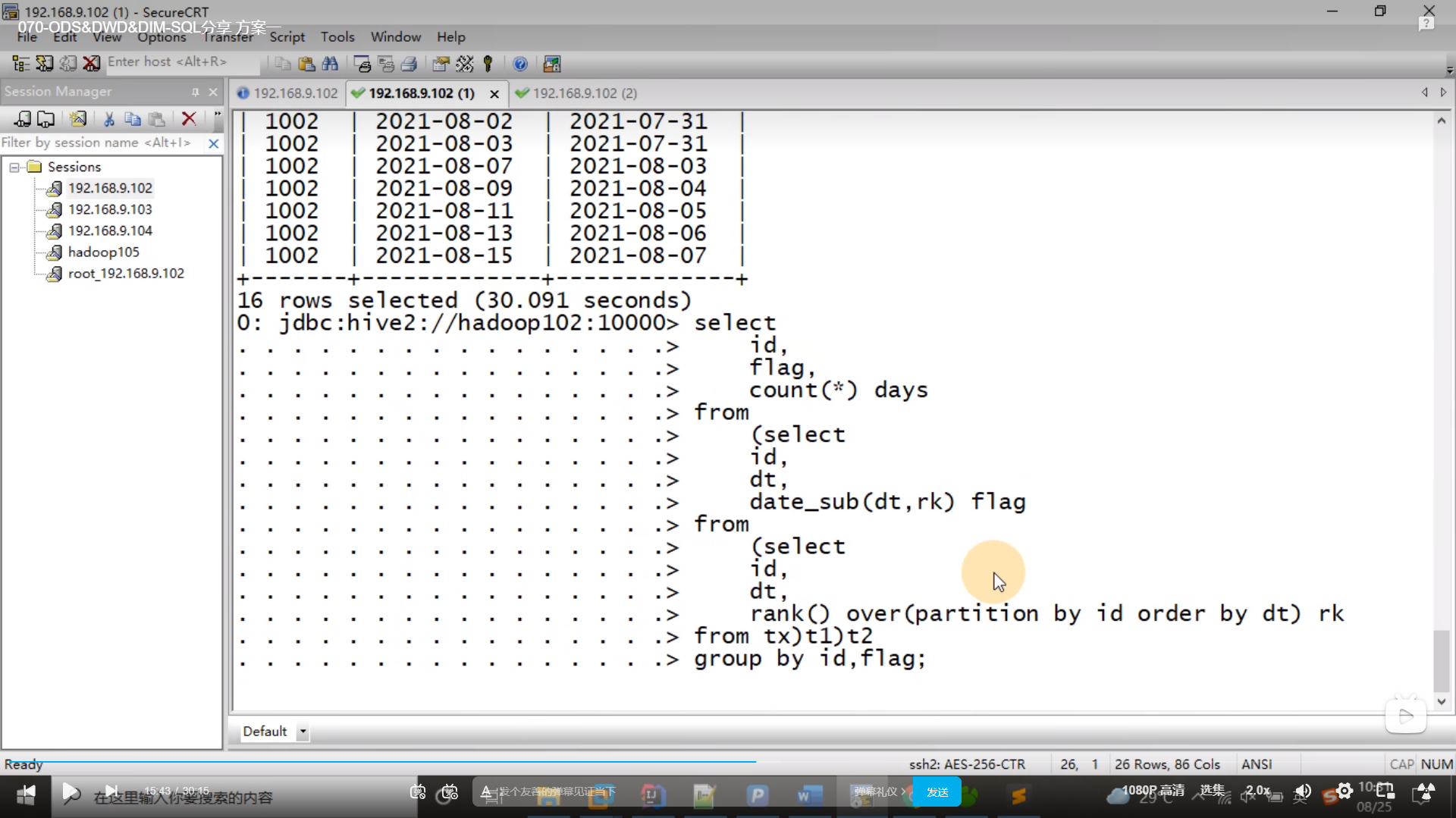
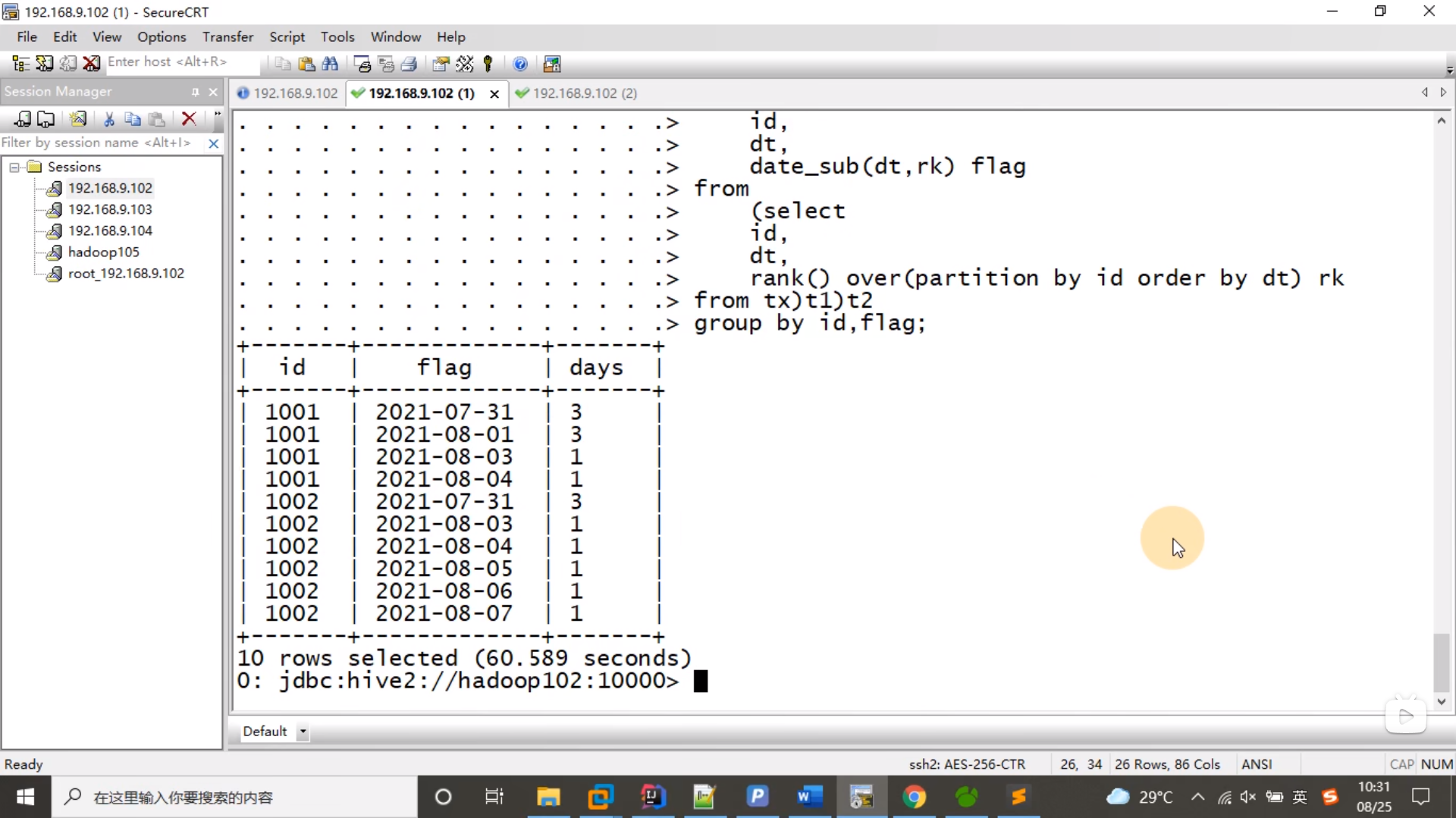
select id,flag,days,rank() over(partition by id order by flag) newFlag
from t3;
复制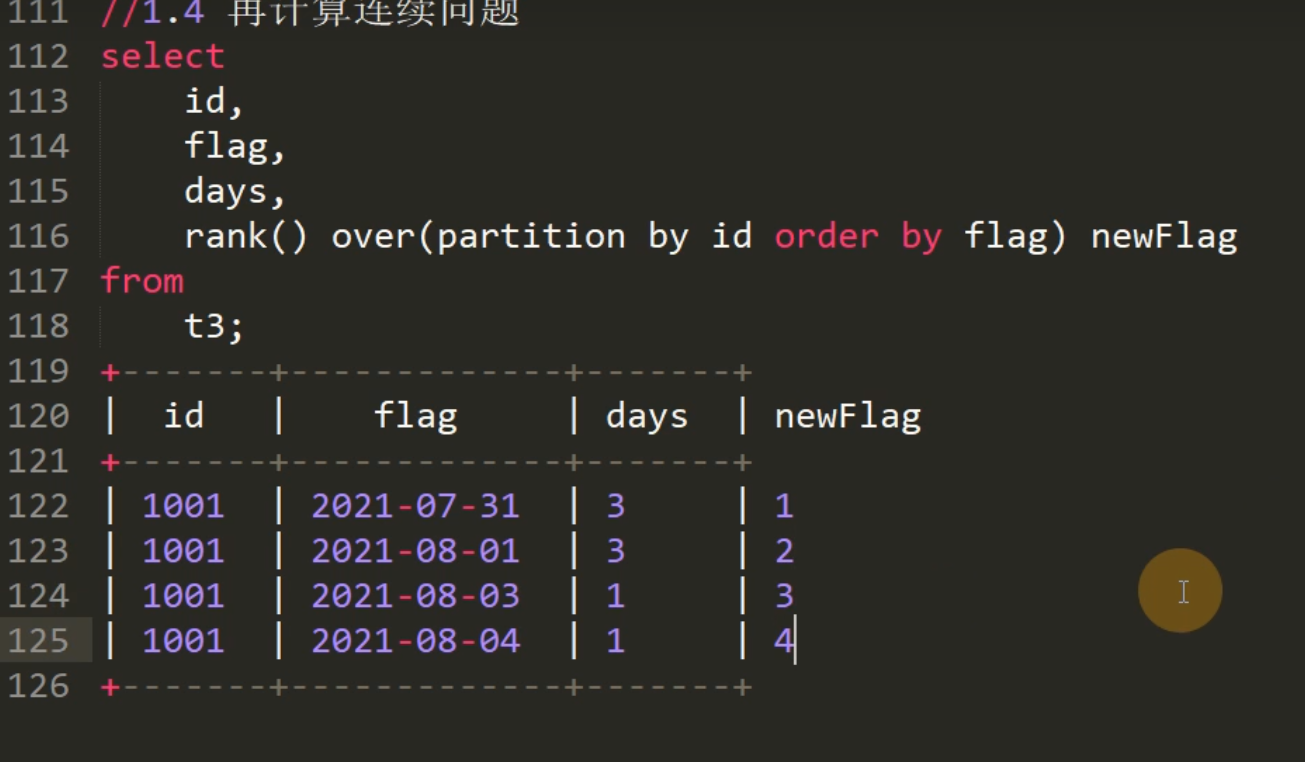
select id,days,date_sub(flag,newFlag) flag
from t4;t5
复制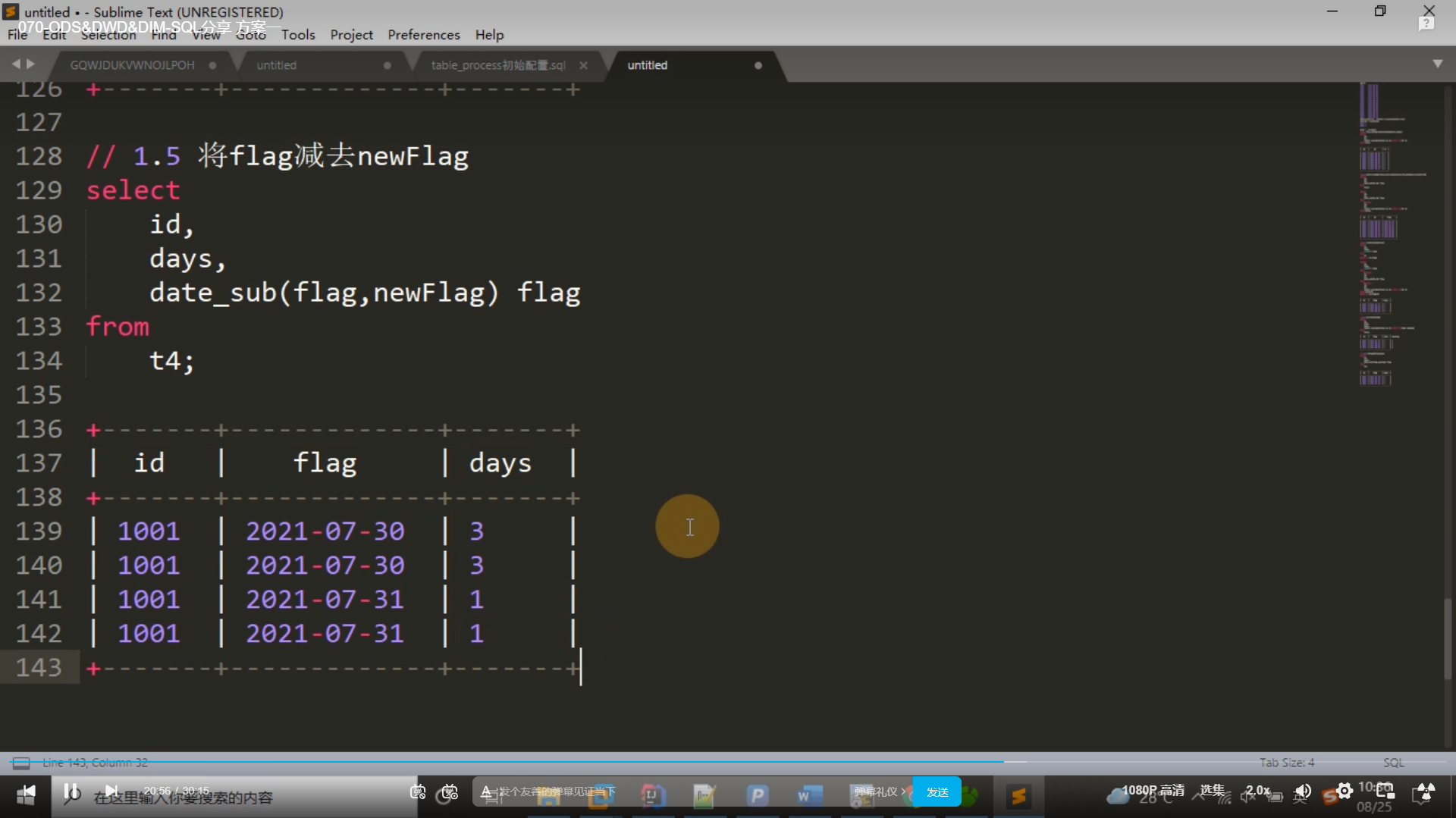
select id,sum(days)+count(1) days
from t5
group by id,flag;[t6]
复制select id,max(days)
from t6
group by id;
复制准后再-1
--下移默认值,一般给 1970-01-01,上移默认值一般 9999-01-01
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx; t1
复制select id,dt,datediff(dt,lagDt) dtDiff
from t1; t2
复制执行
select id,dt,datediff(dt,lagDt) dtDiff
from (
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx) t1;
复制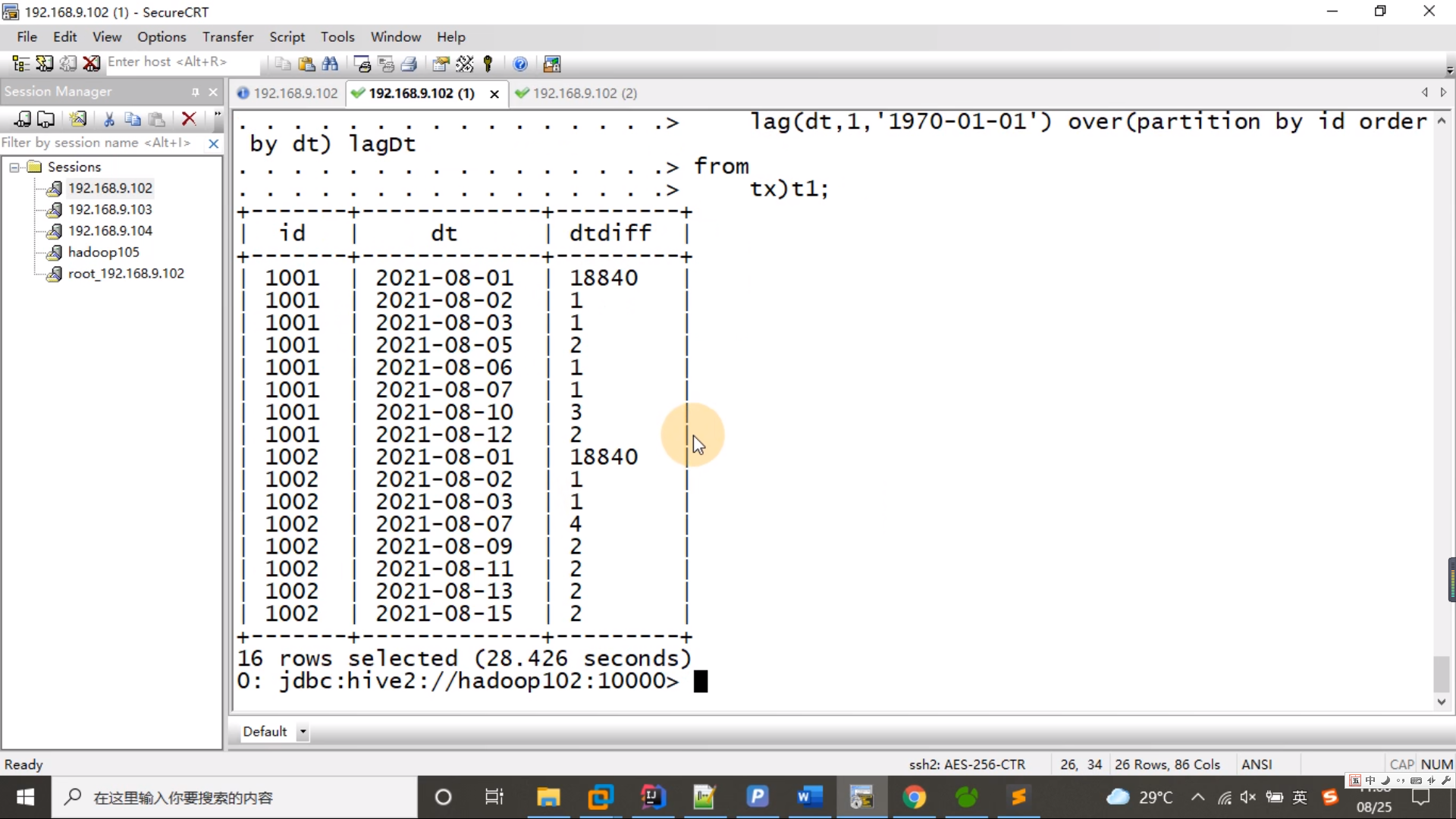
每碰到一个 >2 的就分组 + 1
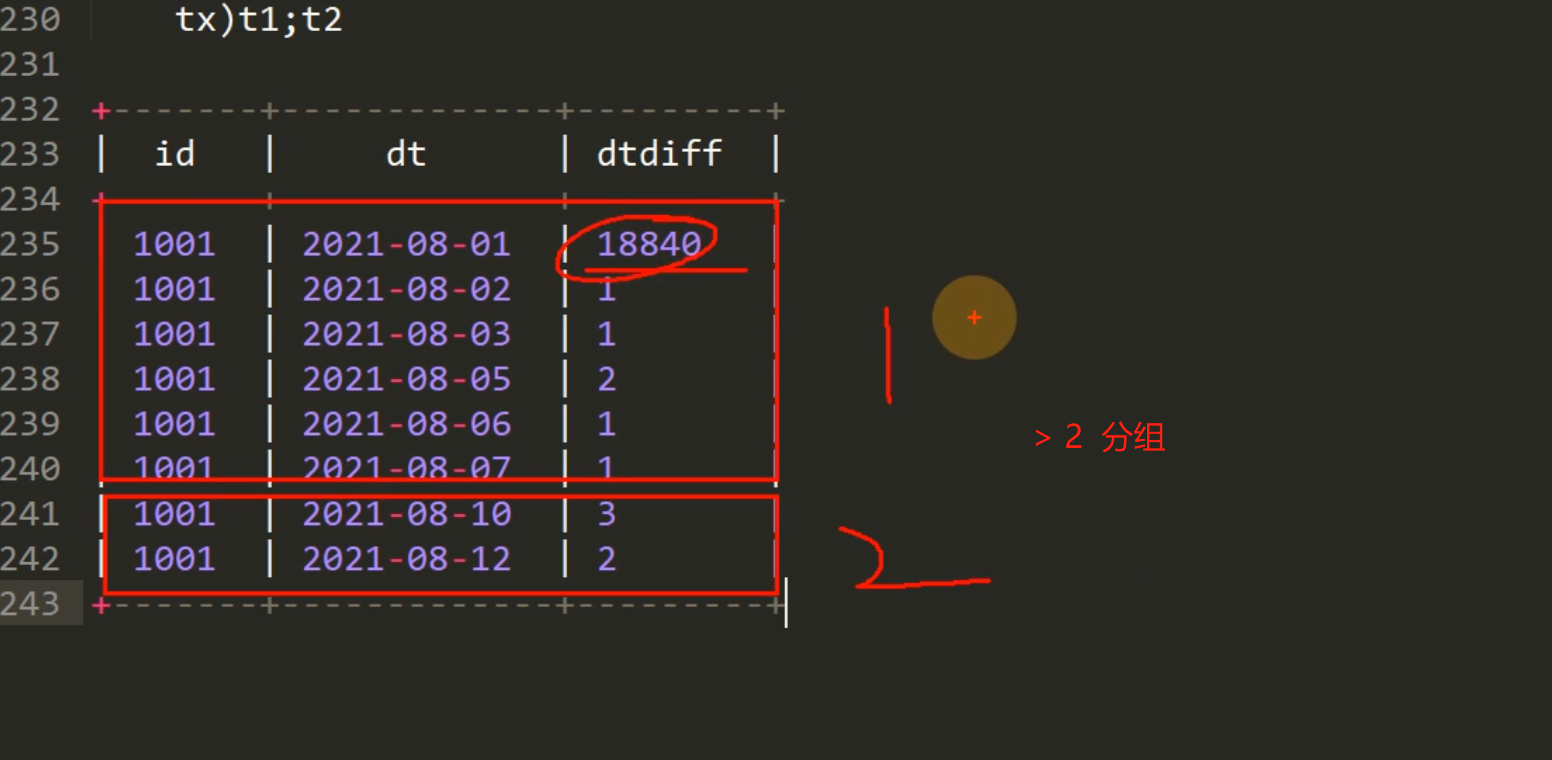
select id,dt,sum(if(dtDiff>2,1,0)) over(partition by id order by dt) flag
from t2; t3
复制select id,dt,sum(if(dtDiff>2,1,0)) over(partition by id order by dt) flag
from (
select id,dt,datediff(dt,lagDt) dtDiff
from (
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx) t1
) t2;
复制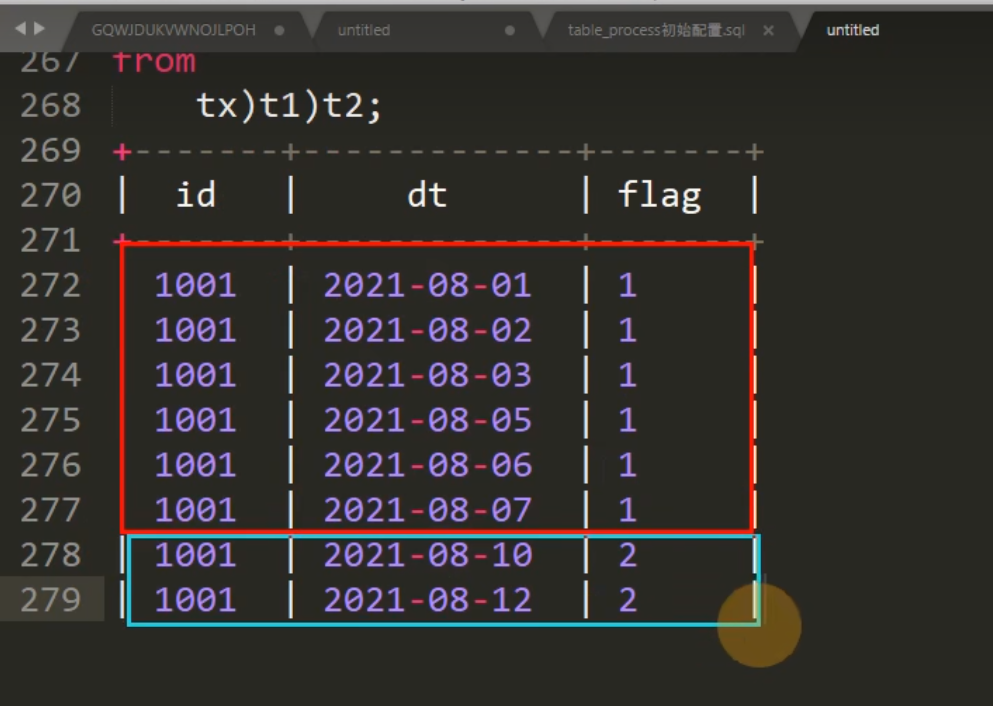
select id,flag,datediff(max(dt),min(dt))+1
from t3
group by id,flag;
复制带入执行
--断3天把2改成3,断4天把2改成4
select id,flag,datediff(max(dt),min(dt))+1
from (
select id,dt,sum(if(dtDiff>2,1,0)) over(partition by id order by dt) flag
from (
select id,dt,datediff(dt,lagDt) dtDiff
from (
select id,dt,lag(dt,1,'1970-01-01') over(partition by id order by dt) lagDt
from tx) t1
) t2
)t3
group by id,flag;
复制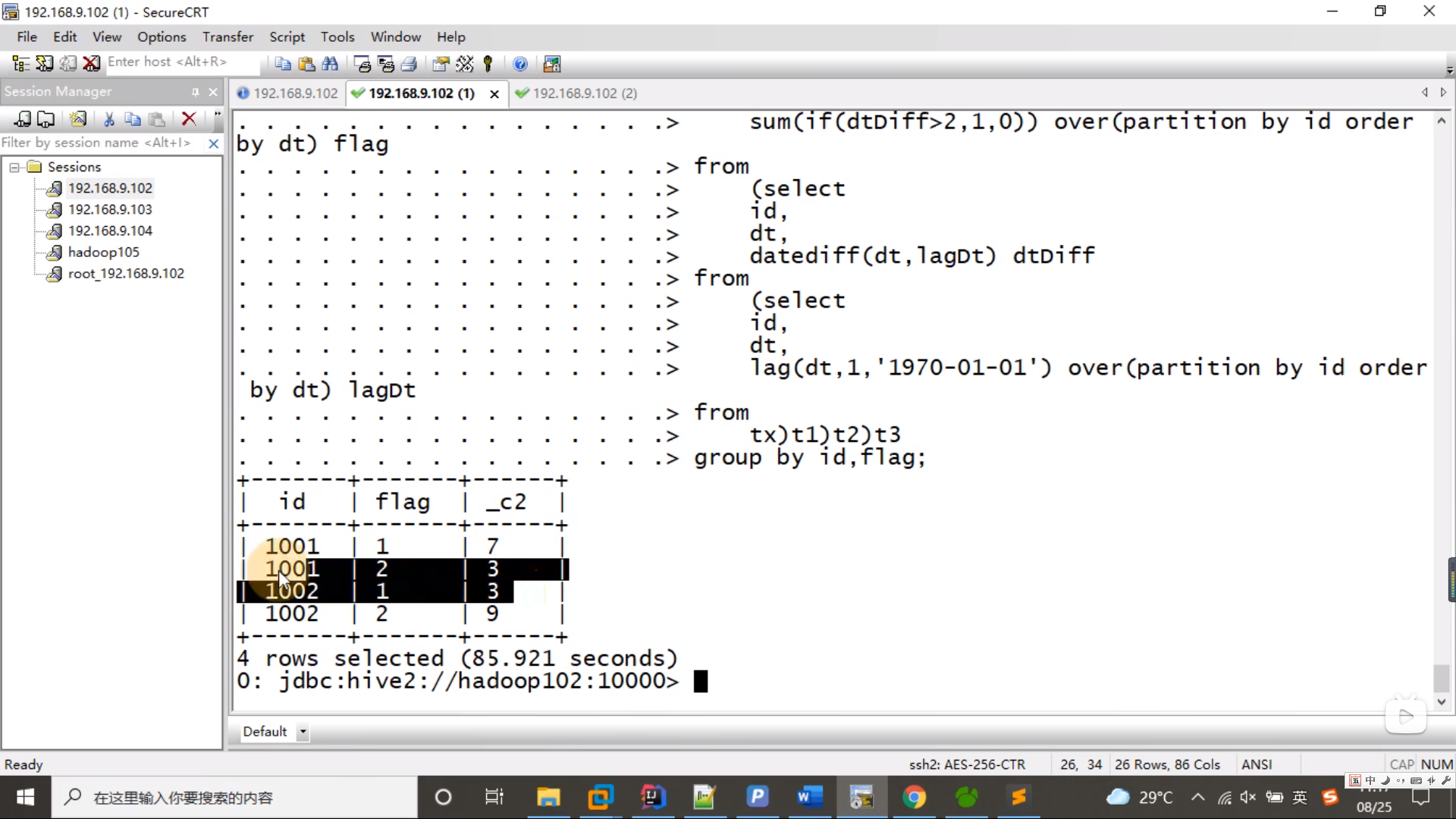
HiveOnSpark: 有个BUG, datediff over 子查询 => null point
解决方案: