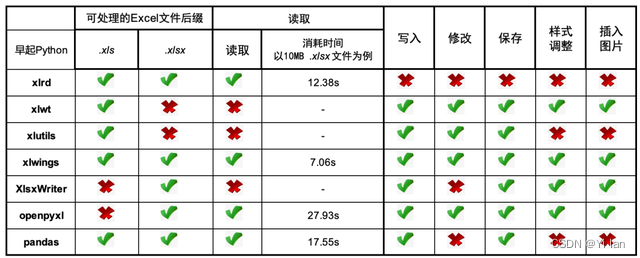
1.安装 openpyxl 组件
pip install openpyxl -i https://mirrors.aliyun.com/pypi/simple/
复制# coding=utf-8
from openpyxl import Workbook
wb = Workbook() # 新建工作簿
ws = wb.active # 获取工作表
ws.append(['姓名', '学号', '年龄']) # 追加一行数据
ws.append(['张三', "1101", 17]) # 追加一行数据
ws.append(['李四', "1102", 18]) # 追加一行数据
wb.save(r'测试1.xlsx') # 保存到指定路径,保存的文件必须不能处于打开状态,因为文件打开后文件只读
复制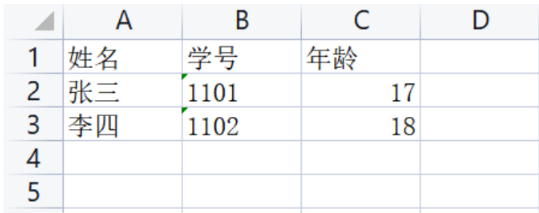
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active # 获取工作表
for row in ws.values: # 输出所有数据
print(row)
复制
wb.active :获取第一张工作表对象
wb[sheet_name] :获取指定名称的工作表对象
wb.sheetnames :获取所有工作表名称
wb.worksheets:获取所有工作表对象,wb.worksheets[0]可以根据索引获取工作表,0代表第一个
wb.create_sheet(sheet_name,index=“end”):创建并返回一个工作表对象,默认位置最后,0代表第一个
wb.copy_worksheet(sheet):在当前工作簿复制指定的工作表并返回复制后的工作表对象
wb.remove(sheet):删除指定的工作表
ws.save(path):保存到指定路径path的Excel文件中,若文件不存在会新建,若文件存在会覆盖
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r"测试1.xlsx")
"""获取工作表"""
active_sheet = wb.active # 获取第一个工作表
print(active_sheet) # 输出工作表:<Worksheet "Sheet">
by_name_sheet = wb["Sheet"] # 根据工作表名称获取工作表
by_index_sheet = wb.worksheets[0] # 根据工作表索引获取工作表
"""获取所有工作表"""
print("获取所有",wb.sheetnames)
"""新建工作表"""
New_Sheet = wb.create_sheet("New") # 在最后新建工作表
First_Sheet = wb.create_sheet("First",index=0) # 在开头新建工作表
print("新建后",wb.sheetnames)
"""复制工作表"""
Copy_Sheet = wb.copy_worksheet(active_sheet) # 复制第一个工作表
Copy_Sheet.title = "Copy"
print("复制后",wb.sheetnames)
"""删除工作表"""
wb.remove(First_Sheet) # 根据指定的工作表对象删除工作表
wb.remove(New_Sheet)
print("删除后",wb.sheetnames)
wb.save(r"测试2.xlsx")
复制ws.title:获取或设置工作表名
ws.max_row:工作表最大行数
ws.max_column:工作表最大列数
ws.append(list):表格末尾追加数据
ws.merge_cells(‘A2:D2’):合并单元格
ws.unmerge_cells(‘A2:D2’):解除合并单元格。
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active
print("工作表名",ws.title)
ws.title = "学生信息表"
print("修改后工作表名",ws.title)
print("最大行数",ws.max_row)
print("最大列数",ws.max_column)
ws.append(["王五","1103",17])
print("最大行数",ws.max_row)
wb.save(r"测试3.xlsx")
复制ws[‘A1’]:根据坐标获取单个单元格对象
ws.cell(row, column, value=None):根据行列获取单个单元格对象
ws[1]:获取第一行所有单元格对象,ws[“1”]也可
ws[“A”]:获取第A列所有单元格对象
ws["A”:“B”]:获取A到B列所有单元格对象,ws[“A:B”]也可
ws[1:2]:获取1到2行所有单元格对象,ws[“1:2”]也可
ws[“A1”:“B2”]:获取A1到B2范围所有单元格对象,ws[“A1:B2”]也可。
ws.values:获取所有单元格数据的可迭代对象,可以通过for循环迭代或通过list(ws.values)转换为数据列表
ws.rows:获取所有数据以行的格式组成的可迭代对象
ws.columns:获取所有数据以列的格式组成的可迭代对象
ws.iter_rows(min_row=None, max_row=None, min_col=None, max_col=None):获取指定边界范围并以行的格式组成的可迭代对象,默认所有行
ws.iter_cols(min_col=None, max_col=None, min_row=None, max_row=None): 获取指定边界范围并以列的格式组成的可迭代对象,默认所有列
cell.value :获取或设置值
cell.column : 数字列标
cell.column_letter : 字母列标
cell.row : 行号
cell.coordinate : 坐标,例如’A1’
cell.data_type : 数据类型, ’s‘ = string字符串,‘n’ = number数值,会根据单元格值自动判断
cell.number_format :单元格格式,默认”General“常规,详见excel自定义数据类型
# coding=utf-8
from openpyxl import Workbook
wb = Workbook() # 新建工作簿
ws = wb.active
"""获取与设置单元格值的两种方式"""
cell1 = ws.cell(1,1) # 先获取第一行第一列的单元格对象
cell1.value = 18 # 再设置单元格对象的值
print("值",cell1.value)
print("数字列标",cell1.column)
print("字母列标",cell1.column_letter)
print("行号",cell1.row)
print("坐标",cell1.coordinate)
cell2 = ws.cell(2,1,17) # 直接在获取单元格的时候设置值
"""使用公式和不适用公式"""
cell3 = ws.cell(3,1,"=A1+A2") # 直接输入公式具有计算功能
cell4 = ws.cell(4,1,"=A1+A2")
cell4.data_type = 's' # 指定单元格数据类型为文本可以避免公式被计算
"""设置格式和不设置格式"""
cell5 = ws.cell(5,1,3.1415) # 默认常规格式
cell6 = ws.cell(6,1,3.1415)
cell6.number_format = "0.00" # 设置格式为保留两位小数
wb.save(r'测试4.xlsx') # 保存到指定路径
复制cell.font :获取或设置单元格Font对象 (字体名称,字体大小,是否加粗,字体颜色等)
cell.border : 获取或设置单元格边框
cell.alignment : 获取或设置单元格水平/垂直对齐方式
cell.fill:获取或设置单元格填充颜色
from openpyxl import Workbook
from openpyxl.styles import Font, Border, Side, Alignment,PatternFill
from copy import copy
wb = Workbook()
ws = wb.active
"""获取单元格并设置单元格值为 姓名 """
cell = ws.cell(1,1,"姓名")
"""设置单元格文字样式"""
cell.font = Font(bold=True, # 加粗
italic=True, # 倾斜
name="楷体", # 字体
size=13, # 文字大小
color="FF0000" # 字体颜色为红色
)
"""复制单元格样式"""
cell2 = ws.cell(1,2,"学号")
cell2.font = copy(cell.font)
"""设置单元格边框为黑色边框"""
cell.border = Border(bottom=Side(style='thin', color='000000'),
right=Side(style='thin', color='000000'),
left=Side(style='thin', color='000000'),
top=Side(style='thin', color='000000'))
"""设置单元格对齐方式为水平垂直居中"""
cell.alignment = Alignment(horizontal='center',vertical='center')
"""设置单元格底纹颜色为黄色"""
cell.fill = PatternFill(fill_type='solid', start_color='FFFF00')
"""
白色:FFFFFF,黑色:000000,红色:FF0000,黄色:FFFF00
绿色:00FF00,蓝色:0000FF,橙色:FF9900,灰色:C0C0C0
常见颜色代码表:https://www.osgeo.cn/openpyxl/styles.html#indexed-colours
"""
wb.save(r"测试5.xlsx")
复制ws.row_dimensions[行号]:获取行对象(非行数据,包括行的相关属性、行高等)
ws.column_dimensions[字母列标]:获取列对象(非行数据,包括行的相关属性、列宽等)
get_column_letter(index):根据列的索引返回字母
column_index_from_string(string):根据字母返回列的索引
row.height:获取或设置行高
column.width:获取或设置列宽
from openpyxl import Workbook
from openpyxl.utils import get_column_letter,column_index_from_string
wb = Workbook()
ws = wb.active
"""行"""
row = ws.row_dimensions[1] # 获取第一行行对象
print("行号",row.index)
row.height = 20 # 设置行高
print("行高",row.height)
"""列"""
column = ws.column_dimensions["A"] # 根据字母列标获取第一列列对象
column = ws.column_dimensions[get_column_letter(1)] # 根据数字列标获取第一列列对象
print("字母列标",column.index)
print("数字列标",column_index_from_string(column.index))
column.width = 15 # 设置列宽
print("列宽",column.width)
wb.save(r'测试6.xlsx')
复制如何根据输入内容计算其在excel的列宽是多少?
# coding=utf-8
from openpyxl import Workbook,load_workbook
import os
dir_path = "学生名单" # 要合并文件的文件夹地址
"""读取文件夹下的所有excel文件"""
files = []
for file in os.listdir(dir_path): # 获取当前目录下的所有文件
files.append(os.path.join(dir_path,file)) # 获取文件夹+文件名的完整路径
"""以第一个文件为基本表"""
merge_excel = load_workbook(files[0])
merge_sheet = merge_excel.active
"""遍历剩余文件,追加到基本表"""
for file in files[1:]:
wb = load_workbook(file)
ws = wb.active
for row in list(ws.values)[1:]: # 从第二行开始读取每一行并追加到基本表
merge_sheet.append(row)
merge_excel.save("高一学生汇总.xlsx")
复制# coding=utf-8
from openpyxl import Workbook,load_workbook
import os
file_path = "高一学生汇总.xlsx" # 要拆分的文件地址
split_dir = "拆分结果" # 拆分文件后保存的文件夹
group_item = "班级" # 拆分的依据字段
"""打开拆分的excel文件并读取标题"""
wb = load_workbook(file_path)
ws = wb.active
title = []
for cell in ws[1]:
title.append(cell.value)
"""开始分组,分组结果保存到字典,键为班级名,值为班级学生列表"""
group_result = {} # 存储分组结果
group_index = title.index(group_item) # 获取拆分依据字段的索引
for row in list(ws.values)[1:]:
class_name = row[group_index] # 获取分组依据数据,即班级名
if class_name in group_result: # 如果分组存在就追加,不存在就新建
group_result[class_name].append(row)
else:
group_result[class_name] = [row]
"""创建输出文件夹"""
if not os.path.exists(split_dir): # 如果不存在文件夹就新建
os.mkdir(split_dir)
os.chdir(split_dir) # 进入拆分文件夹
"""打印并输出分组后的数据"""
for class_name,students in group_result.items():
new_wb = Workbook() # 新建excel
new_ws = new_wb.active
new_ws.append(title) # 追加标题
for student in students:
new_ws.append(student) # 讲分组数组追加到新excel中
new_wb.save("{}.xlsx".format(class_name))
复制如何根据输入内容计算其在excel的列宽是多少?
利用GBK编码方式,非汉字字符占1个长度,汉字字符占2个长度
from openpyxl import Workbook
from openpyxl.utils import get_column_letter,column_index_from_string
wb = Workbook()
ws = wb.active
column = ws.column_dimensions[get_column_letter(1)] # 根据数字列标获取第一列列对象
value = "我爱中国ILoveChain" # 4*2+10*1+1=19
column.width = len(str(value).encode("GBK"))+1 # 根据内容设置列宽,+1既可以补充误差又可以让两边留有一定的空白,美观
print("列宽",column.width) # 输出:19
ws.cell(1,1,value)
wb.save(r'测试6.xlsx')
复制原文链接:https://blog.csdn.net/qq_40910781/article/details/127270735