OCR -- 文本识别 -- 理论篇
本章将详细介绍如何基于PaddleOCR完成CRNN文本识别模型的搭建、训练、评估和预测。数据集采用 icdar 2015,其中训练集有4468张,测试集有2077张。
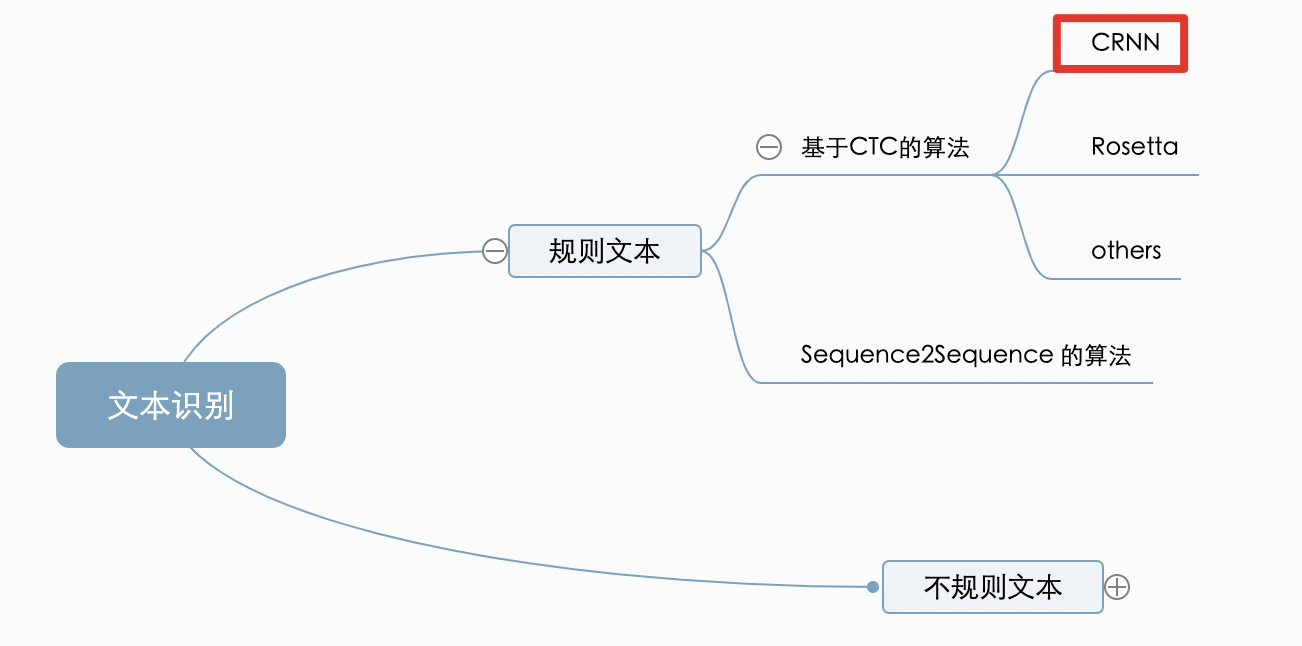
CRNN是基于CTC的算法,CRNN是较早被提出也是目前工业界应用较多的方法。主要用于识别规则文本,有效快的预测速度,并且因为序列不对齐,不受长度的影响,所以在长文本上有很好的预测效果,中文算法里的首选
第一节中 paddleocr 加载训练好的 CRNN 识别模型进行预测,本节将详细介绍 CRNN 的原理及流程。
CRNN 是基于CTC的算法,在理论部分介绍的分类图中,处在如下位置。可以看出CRNN主要用于解决规则文本,基于CTC的算法有较快的预测速度并且很好的适用长文本。因此CRNN是PPOCR选择的中文识别算法。
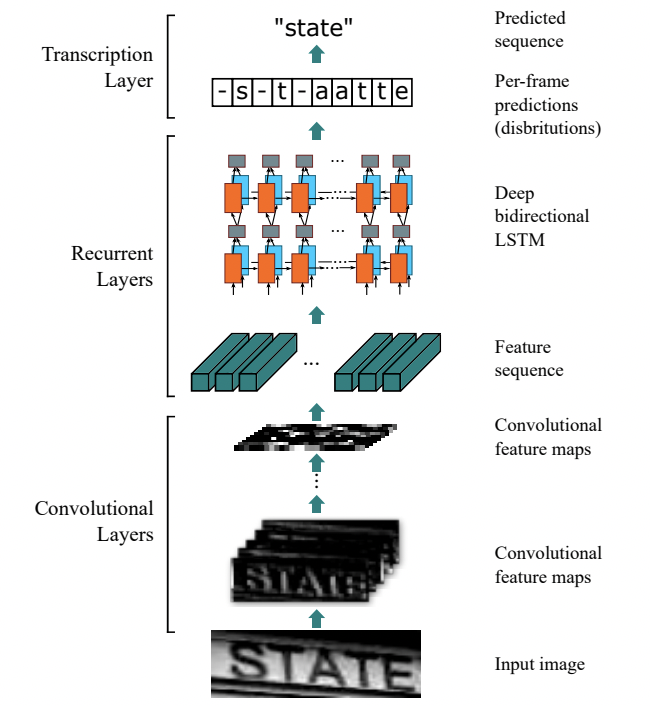
CRNN 的网络结构体系如下所示,从下往上分别为卷积层、递归层和转录层三部分:
1)backbone:
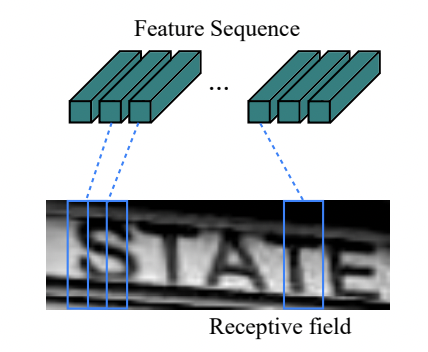
卷积网络作为底层的骨干网络,用于从输入图像中提取特征序列。由于 conv、max-pooling、elementwise 和激活函数都作用在局部区域上,所以它们是平移不变的。因此,特征映射的每一列对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与它们在特征映射上对应的列从左到右的顺序相同。由于CNN需要将输入的图像缩放到固定的尺寸以满足其固定的输入维数,因此它不适合长度变化很大的序列对象。为了更好的支持变长序列,CRNN将backbone最后一层输出的特征向量送到了RNN层,转换为序列特征。
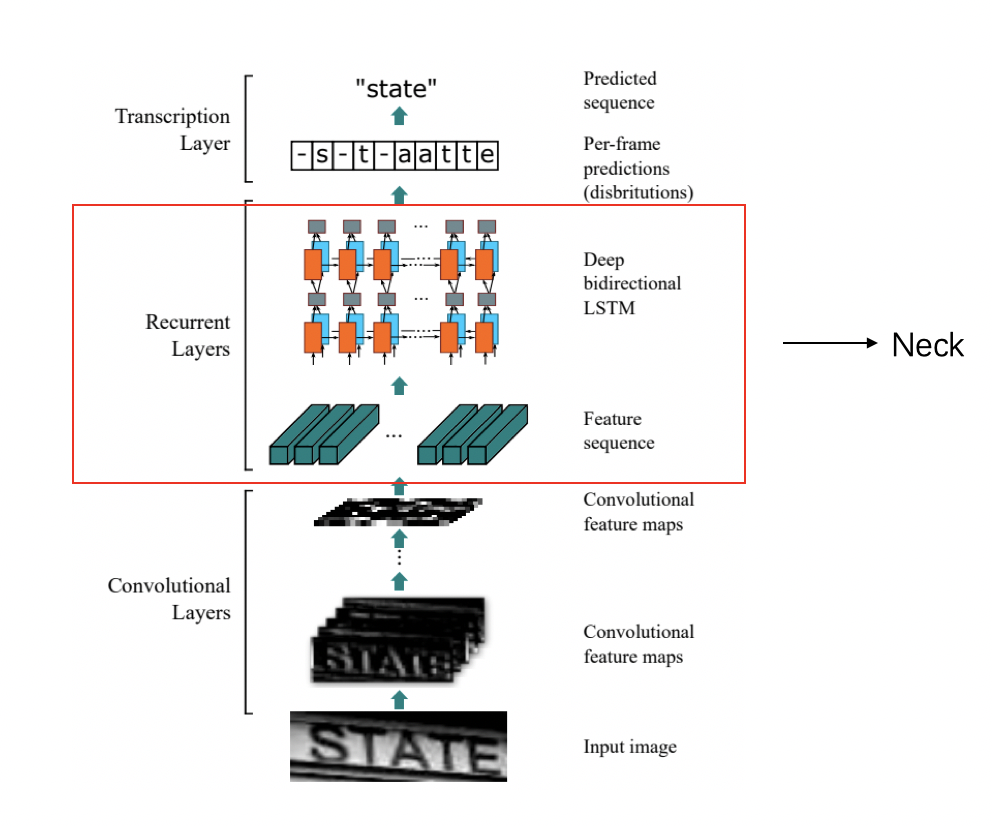
2)neck:
递归层,在卷积网络的基础上,构建递归网络,将图像特征转换为序列特征,预测每个帧的标签分布。
RNN具有很强的捕获序列上下文信息的能力。使用上下文线索进行基于图像的序列识别比单独处理每个像素更有效。以场景文本识别为例,宽字符可能需要几个连续的帧来充分描述。此外,有些歧义字符在观察其上下文时更容易区分。其次,RNN可以将误差差分反向传播回卷积层,使网络可以统一训练。第三,RNN能够对任意长度的序列进行操作,解决了文本图片变长的问题。CRNN使用双层LSTM作为递归层,解决了长序列训练过程中的梯度消失和梯度爆炸问题。
3)head:
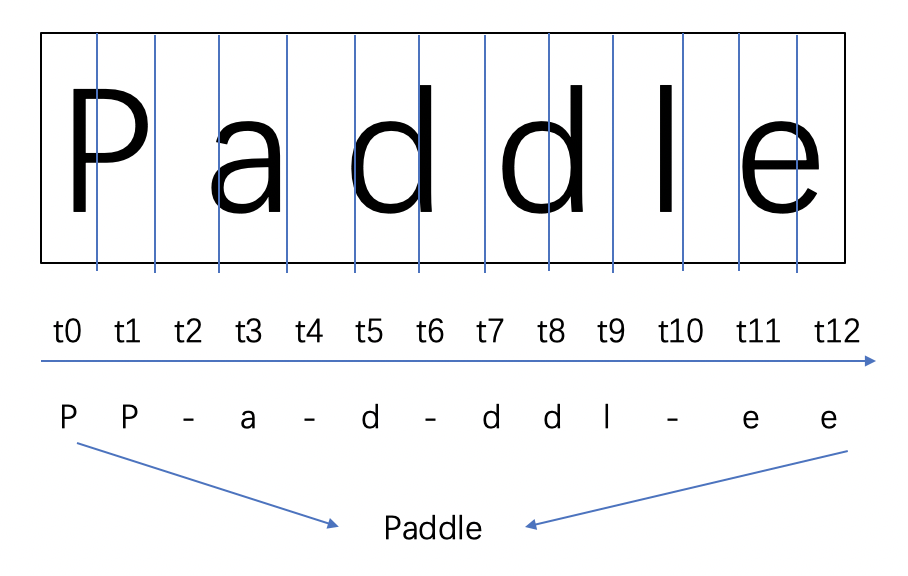
转录层,通过全连接网络和softmax激活函数,将每帧的预测转换为最终的标签序列。最后使用 CTC Loss 在无需序列对齐的情况下,完成CNN和RNN的联合训练。CTC 有一套特别的合并序列机制,LSTM输出序列后,需要在时序上分类得到预测结果。可能存在多个时间步对应同一个类别,因此需要对相同结果进行合并。为避免合并本身存在的重复字符,CTC 引入了一个 blank 字符插入在重复字符之间。
整个网络结构非常简洁,代码实现也相对简单,可以跟随预测流程依次搭建模块。本节需要完成:数据输入、backbone搭建、neck搭建、head搭建。
【数据输入】
数据送入网络前需要缩放到统一尺寸(3,32,320)【英文一般是(3,32,100),高度 32 效果比较好,】,并完成归一化处理。这里省略掉训练时需要的数据增强部分,以单张图为例展示预处理的必须步骤(源码位置):
中文字符,长、宽比,1:1, 10倍 320,
import cv2
import math
import numpy as np
def resize_norm_img(img):
"""
数据缩放和归一化
:param img: 输入图片
"""
# 默认输入尺寸 英文为 (3,32,100)
imgC = 3
imgH = 32 # 高度 32 效果比较好
imgW = 320 # 中文每个字长宽比为1:1,防止长宽比在resize后被压缩过小或拉伸过大,识别大概10个字左右,所以宽度 10倍 = 320
# 图片的真实高宽
h, w = img.shape[:2]
# 图片真实长宽比
ratio = w / float(h)
# 按比例缩放
if math.ceil(imgH * ratio) > imgW:
# 如大于默认宽度,则宽度为imgW
resized_w = imgW
else:
# 如小于默认宽度则以图片真实宽为准
resized_w = int(math.ceil(imgH * ratio))
# 缩放
resized_image = cv2.resize(img, (resized_w, imgH))
resized_image = resized_image.astype('float32')
# 归一化
resized_image = resized_image.transpose((2, 0, 1)) / 255
resized_image -= 0.5
resized_image /= 0.5
# 对宽度不足的位置,补0
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
# 转置 padding 后的图片用于可视化
draw_img = padding_im.transpose((1,2,0))
return padding_im, draw_img
复制【网络结构】
PaddleOCR 使用 MobileNetV3 作为骨干网络,组网顺序与网络结构一致,首先定义网络中的公共模块(源码位置):ConvBNLayer、ResidualUnit、make_divisible
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class ConvBNLayer(nn.Layer):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride,
padding,
groups=1,
if_act=True,
act=None):
"""
卷积BN层
:param in_channels: 输入通道数
:param out_channels: 输出通道数
:param kernel_size: 卷积核尺寸
:parma stride: 步长大小
:param padding: 填充大小
:param groups: 二维卷积层的组数
:param if_act: 是否添加激活函数
:param act: 激活函数
"""
super(ConvBNLayer, self).__init__()
self.if_act = if_act
self.act = act
self.conv = nn.Conv2D(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias_attr=False)
self.bn = nn.BatchNorm(num_channels=out_channels, act=None)
def forward(self, x):
# conv层
x = self.conv(x)
# batchnorm层
x = self.bn(x)
# 是否使用激活函数
if self.if_act:
if self.act == "relu":
x = F.relu(x)
elif self.act == "hardswish":
x = F.hardswish(x)
else:
print("The activation function({}) is selected incorrectly.".
format(self.act))
exit()
return x
class SEModule(nn.Layer):
def __init__(self, in_channels, reduction=4):
"""
SE模块
:param in_channels: 输入通道数
:param reduction: 通道缩放率
"""
super(SEModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.conv1 = nn.Conv2D(
in_channels=in_channels,
out_channels=in_channels // reduction,
kernel_size=1,
stride=1,
padding=0)
self.conv2 = nn.Conv2D(
in_channels=in_channels // reduction,
out_channels=in_channels,
kernel_size=1,
stride=1,
padding=0)
def forward(self, inputs):
# 平均池化
outputs = self.avg_pool(inputs)
# 第一个卷积层
outputs = self.conv1(outputs)
# relu激活函数
outputs = F.relu(outputs)
# 第二个卷积层
outputs = self.conv2(outputs)
# hardsigmoid 激活函数
outputs = F.hardsigmoid(outputs, slope=0.2, offset=0.5)
return inputs * outputs
class ResidualUnit(nn.Layer):
def __init__(self,
in_channels,
mid_channels,
out_channels,
kernel_size,
stride,
use_se,
act=None):
"""
残差层
:param in_channels: 输入通道数
:param mid_channels: 中间通道数
:param out_channels: 输出通道数
:param kernel_size: 卷积核尺寸
:parma stride: 步长大小
:param use_se: 是否使用se模块
:param act: 激活函数
"""
super(ResidualUnit, self).__init__()
self.if_shortcut = stride == 1 and in_channels == out_channels
self.if_se = use_se
self.expand_conv = ConvBNLayer(
in_channels=in_channels,
out_channels=mid_channels,
kernel_size=1,
stride=1,
padding=0,
if_act=True,
act=act)
self.bottleneck_conv = ConvBNLayer(
in_channels=mid_channels,
out_channels=mid_channels,
kernel_size=kernel_size,
stride=stride,
padding=int((kernel_size - 1) // 2),
groups=mid_channels,
if_act=True,
act=act)
if self.if_se:
self.mid_se = SEModule(mid_channels)
self.linear_conv = ConvBNLayer(
in_channels=mid_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
if_act=False,
act=None)
def forward(self, inputs):
x = self.expand_conv(inputs)
x = self.bottleneck_conv(x)
if self.if_se:
x = self.mid_se(x)
x = self.linear_conv(x)
if self.if_shortcut:
x = paddle.add(inputs, x)
return x
def make_divisible(v, divisor=8, min_value=None):
"""
确保被8整除
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
复制利用公共模块搭建骨干网络
class MobileNetV3(nn.Layer):
def __init__(self,
in_channels=3,
model_name='small',
scale=0.5,
small_stride=None,
disable_se=False,
**kwargs):
super(MobileNetV3, self).__init__()
self.disable_se = disable_se
small_stride = [1, 2, 2, 2]
if model_name == "small":
cfg = [
# k, exp, c, se, nl, s,
[3, 16, 16, True, 'relu', (small_stride[0], 1)],
[3, 72, 24, False, 'relu', (small_stride[1], 1)],
[3, 88, 24, False, 'relu', 1],
[5, 96, 40, True, 'hardswish', (small_stride[2], 1)],
[5, 240, 40, True, 'hardswish', 1],
[5, 240, 40, True, 'hardswish', 1],
[5, 120, 48, True, 'hardswish', 1],
[5, 144, 48, True, 'hardswish', 1],
[5, 288, 96, True, 'hardswish', (small_stride[3], 1)],
[5, 576, 96, True, 'hardswish', 1],
[5, 576, 96, True, 'hardswish', 1],
]
cls_ch_squeeze = 576
else:
raise NotImplementedError("mode[" + model_name +
"_model] is not implemented!")
supported_scale = [0.35, 0.5, 0.75, 1.0, 1.25]
assert scale in supported_scale, \
"supported scales are {} but input scale is {}".format(supported_scale, scale)
inplanes = 16
# conv1
self.conv1 = ConvBNLayer(
in_channels=in_channels,
out_channels=make_divisible(inplanes * scale),
kernel_size=3,
stride=2,
padding=1,
groups=1,
if_act=True,
act='hardswish')
i = 0
block_list = []
inplanes = make_divisible(inplanes * scale)
for (k, exp, c, se, nl, s) in cfg:
se = se and not self.disable_se
block_list.append(
ResidualUnit(
in_channels=inplanes,
mid_channels=make_divisible(scale * exp),
out_channels=make_divisible(scale * c),
kernel_size=k,
stride=s,
use_se=se,
act=nl))
inplanes = make_divisible(scale * c)
i += 1
self.blocks = nn.Sequential(*block_list)
self.conv2 = ConvBNLayer(
in_channels=inplanes,
out_channels=make_divisible(scale * cls_ch_squeeze),
kernel_size=1,
stride=1,
padding=0,
groups=1,
if_act=True,
act='hardswish')
self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
self.out_channels = make_divisible(scale * cls_ch_squeeze)
def forward(self, x):
x = self.conv1(x)
x = self.blocks(x)
x = self.conv2(x)
x = self.pool(x)
return x
复制# 图片输入骨干网络
backbone = MobileNetV3()
# 将numpy数据转换为Tensor
input_data = paddle.to_tensor([padding_im])
# 骨干网络输出
feature = backbone(input_data)
# 查看feature map的纬度
print("backbone output:", feature.shape)
复制neck 部分将backbone输出的视觉特征图转换为1维向量输入送到 LSTM 网络中,输出序列特征( 源码位置 ):
class Im2Seq(nn.Layer):
def __init__(self, in_channels, **kwargs):
"""
图像特征转换为序列特征
:param in_channels: 输入通道数
"""
super().__init__()
self.out_channels = in_channels
def forward(self, x):
B, C, H, W = x.shape
assert H == 1
x = x.squeeze(axis=2)
x = x.transpose([0, 2, 1]) # (NWC)(batch, width, channels)
return x
class EncoderWithRNN(nn.Layer):
def __init__(self, in_channels, hidden_size):
super(EncoderWithRNN, self).__init__()
self.out_channels = hidden_size * 2
self.lstm = nn.LSTM(
in_channels, hidden_size, direction='bidirectional', num_layers=2)
def forward(self, x):
x, _ = self.lstm(x)
return x
class SequenceEncoder(nn.Layer):
def __init__(self, in_channels, hidden_size=48, **kwargs):
"""
序列编码
:param in_channels: 输入通道数
:param hidden_size: 隐藏层size
"""
super(SequenceEncoder, self).__init__()
self.encoder_reshape = Im2Seq(in_channels)
self.encoder = EncoderWithRNN(
self.encoder_reshape.out_channels, hidden_size)
self.out_channels = self.encoder.out_channels
def forward(self, x):
x = self.encoder_reshape(x)
x = self.encoder(x)
return x
复制neck = SequenceEncoder(in_channels=288)
sequence = neck(feature)
print("sequence shape:", sequence.shape) # sequence shape:[1, 80, 96] 96 = hidden_size=48 * 2
复制预测头部分由全连接层和softmax组成,用于计算序列特征时间步上的标签概率分布,本示例仅支持模型识别小写英文字母和数字(26+10)36个类别(源码位置):
class CTCHead(nn.Layer):
def __init__(self,
in_channels,
out_channels,
**kwargs):
"""
CTC 预测层
:param in_channels: 输入通道数
:param out_channels: 输出通道数
"""
super(CTCHead, self).__init__()
self.fc = nn.Linear(
in_channels,
out_channels)
# 思考:out_channels 应该等于多少? fc(x) 的 out_channels = 37 因为有一个空字符 = (26+10)36个类别 + 1 = 37
self.out_channels = out_channels
def forward(self, x):
predicts = self.fc(x)
result = predicts
if not self.training:
predicts = F.softmax(predicts, axis=2)
result = predicts
return result
复制在网络随机初始化的情况下,输出结果是无序的,经过SoftMax之后,可以得到各时间步上的概率最大的预测结果,其中:pred_id 代表预测的标签ID,pre_scores 代表预测结果的置信度:
ctc_head = CTCHead(in_channels=96, out_channels=37)
predict = ctc_head(sequence)
print("predict shape:", predict.shape)
result = F.softmax(predict, axis=2)
pred_id = paddle.argmax(result, axis=2)
pred_socres = paddle.max(result, axis=2)
print("pred_id:", pred_id)
print("pred_scores:", pred_socres)
复制识别网络最终返回的结果是各个时间步上的最大索引值,最终期望的输出是对应的文字结果,因此CRNN的后处理是一个解码过程,主要逻辑如下:
def decode(text_index, text_prob=None, is_remove_duplicate=False):
""" convert text-index into text-label. """
character = "-0123456789abcdefghijklmnopqrstuvwxyz" # 没有从字典取字符,因为比较简单,就直接写在这了
result_list = []
# 忽略tokens [0] 代表ctc中的blank位
ignored_tokens = [0]
batch_size = len(text_index)
for batch_idx in range(batch_size):
char_list = []
conf_list = []
for idx in range(len(text_index[batch_idx])):
if text_index[batch_idx][idx] in ignored_tokens:
continue
# 合并blank之间相同的字符
if is_remove_duplicate:
# only for predict
if idx > 0 and text_index[batch_idx][idx - 1] == text_index[
batch_idx][idx]:
continue
# 将解码结果存在char_list内
char_list.append(character[int(text_index[batch_idx][
idx])])
# 记录置信度
if text_prob is not None:
conf_list.append(text_prob[batch_idx][idx])
else:
conf_list.append(1)
text = ''.join(char_list)
# 输出结果
result_list.append((text, np.mean(conf_list)))
return result_list
复制以 head 部分随机初始化预测出的结果为例,进行解码得到:
pred_id = paddle.argmax(result, axis=2)
pred_socres = paddle.max(result, axis=2)
print(pred_id)
decode_out = decode(pred_id, pred_socres)
print("decode out:", decode_out)
复制上述步骤完成了网络的搭建,也实现了一个简单的前向预测过程。
没有经过训练的网络无法正确预测结果,因此需要定义损失函数、优化策略,将整个网络run起来,下面将详细介绍网络训练原理。
PaddleOCR 支持两种数据格式:
lmdb 用于训练以lmdb格式存储的数据集(LMDBDataSet);通用数据 用于训练以文本文件存储的数据集(SimpleDataSet);本次只介绍通用数据格式读取
训练数据的默认存储路径是 ./train_data, 执行以下命令解压数据:
cd /home/aistudio/work/train_data/ && tar xf ic15_data.tar
复制解压完成后,训练图片都在同一个文件夹内,并有一个txt文件(rec_gt_train.txt)记录图片路径和标签,txt文件里的内容如下:
" 图像文件名 图像标注信息 "
train/word_1.png Genaxis Theatre
train/word_2.png [06]
...
复制注意: txt文件中默认将图片路径和图片标签用 \t 分割,如用其他方式分割将造成训练报错。
数据集应有如下文件结构:
|-train_data
|-ic15_data
|- rec_gt_train.txt
|- train
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
|- rec_gt_test.txt
|- test
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
复制确认配置文件中的数据路径是否正确,以 rec_icdar15_train.yml为例:
Train:
dataset:
name: SimpleDataSet
# 训练数据根目录
data_dir: ./train_data/ic15_data/
# 训练数据标签
label_file_list: ["./train_data/ic15_data/rec_gt_train.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 100] # [3,32,320]
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 256 # 第一次调试可以改小一点。防止一起来就崩了
drop_last: True
num_workers: 8
use_shared_memory: False
Eval:
dataset:
name: SimpleDataSet
# 评估数据根目录
data_dir: ./train_data/ic15_data
# 评估数据标签
label_file_list: ["./train_data/ic15_data/rec_gt_test.txt"]
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 100] # 要得训练的设置值一致
- KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: False
drop_last: False
batch_size_per_card: 256
num_workers: 4
use_shared_memory: False
复制送入网络的训练数据,需要保证一个batch内维度一致,同时为了不同维度之间的特征在数值上有一定的比较性,需要对数据做统一尺度缩放和归一化。
为了增加模型的鲁棒性,抑制过拟合提升泛化性能,需要实现一定的数据增广。
第二节中已经介绍了相关内容,这是图片送入网络之前的最后一步操作。调用 resize_norm_img 完成图片缩放、padding和归一化。
PaddleOCR中实现了多种数据增广方式,如:颜色反转、随机切割、仿射变化、随机噪声等等,这里以简单的随机切割为例,更多增广方式可参考:rec_img_aug.py
def get_crop(image):
"""
random crop
"""
import random
h, w, _ = image.shape
top_min = 1
top_max = 8
top_crop = int(random.randint(top_min, top_max))
top_crop = min(top_crop, h - 1)
crop_img = image.copy()
ratio = random.randint(0, 1)
if ratio:
crop_img = crop_img[top_crop:h, :, :]
else:
crop_img = crop_img[0:h - top_crop, :, :]
return crop_img
复制# 读图
raw_img = cv2.imread("/home/aistudio/work/word_1.png")
plt.figure()
plt.subplot(2,1,1)
# 可视化原图
plt.imshow(raw_img)
# 随机切割
crop_img = get_crop(raw_img)
plt.subplot(2,1,2)
# 可视化增广图
plt.imshow(crop_img)
plt.show()
复制
模型训练的入口代码是 train.py,它展示了训练中所需的各个模块: build dataloader, build post process, build model , build loss, build optim, build metric,将各部分串联后即可开始训练:
训练模型需要将数据组成指定数目的 batch ,并在训练过程中依次 yield 出来,本例中调用了 PaddleOCR 中实现的 SimpleDataSet
基于原始代码稍作修改,其返回单条数据的主要逻辑如下
def __getitem__(data_line, data_dir):
import os
mode = "train"
delimiter = '\t' # label 设置的时候,前面是图片的路径,所以要 \t 进行分隔后面真实的标签
try:
substr = data_line.strip("\n").split(delimiter)
file_name = substr[0]
label = substr[1]
img_path = os.path.join(data_dir, file_name)
data = {'img_path': img_path, 'label': label}
if not os.path.exists(img_path):
raise Exception("{} does not exist!".format(img_path))
with open(data['img_path'], 'rb') as f:
img = f.read()
data['image'] = img
# 预处理操作,先注释掉
# outs = transform(data, self.ops)
outs = data
except Exception as e:
print("When parsing line {}, error happened with msg: {}".format(
data_line, e))
outs = None
return outs
复制假设当前输入的标签为 train/word_1.png Genaxis Theatre, 训练数据的路径为 /home/aistudio/work/train_data/ic15_data/, 解析出的结果是一个字典,里面包含 img_path label image 三个字段:
data_line = "train/word_1.png Genaxis Theatre"
data_dir = "/home/aistudio/work/train_data/ic15_data/"
item = __getitem__(data_line, data_dir)
print(item)
复制实现完单条数据返回逻辑后,调用 padde.io.Dataloader 即可把数据组合成batch,具体可参考 build_dataloader
build model
build model 即搭建主要网络结构,具体细节如《2.3 代码实现》所述,本节不做过多介绍,各模块代码可参考modeling
build loss
CRNN 模型的损失函数为 CTC loss, 飞桨集成了常用的 Loss 函数,只需调用实现即可:
import paddle.nn as nn
class CTCLoss(nn.Layer):
def __init__(self, use_focal_loss=False, **kwargs):
super(CTCLoss, self).__init__()
# blank 是 ctc 的无意义连接符
self.loss_func = nn.CTCLoss(blank=0, reduction='none')
def forward(self, predicts, batch):
if isinstance(predicts, (list, tuple)):
predicts = predicts[-1]
# 转置模型 head 层的预测结果,沿channel层排列
predicts = predicts.transpose((1, 0, 2)) #[80,1,37]
N, B, _ = predicts.shape
preds_lengths = paddle.to_tensor([N] * B, dtype='int64')
labels = batch[1].astype("int32")
label_lengths = batch[2].astype('int64')
# 计算损失函数
loss = self.loss_func(predicts, labels, preds_lengths, label_lengths)
loss = loss.mean()
return {'loss': loss}
复制具体细节同样在《2.3 代码实现》有详细介绍,实现逻辑与之前一致。
优化器使用 Adam , 同样调用飞桨API: paddle.optimizer.Adam
metric 部分用于计算模型指标,PaddleOCR的文本识别中,将整句预测正确判断为预测正确,因此准确率计算主要逻辑如下:
def metric(preds, labels):
correct_num = 0
all_num = 0
norm_edit_dis = 0.0
for (pred), (target) in zip(preds, labels):
pred = pred.replace(" ", "") # 如果严格预测的话,把这代码注释掉,比较时,空格敏感的预测
target = target.replace(" ", "")
if pred == target:
correct_num += 1
all_num += 1
correct_num += correct_num
all_num += all_num
return {
'acc': correct_num / all_num,
}
复制preds = ["aaa", "bbb", "ccc", "123", "456"]
labels = ["aaa", "bbb", "ddd", "123", "444"]
acc = metric(preds, labels)
print("acc:", acc)
# 五个预测结果中,完全正确的有3个,因此准确率应为0.6
复制将以上各部分组合起来,即是完整的训练流程:
def main(config, device, logger, vdl_writer):
# init dist environment
if config['Global']['distributed']:
dist.init_parallel_env()
global_config = config['Global']
# build dataloader
train_dataloader = build_dataloader(config, 'Train', device, logger)
if len(train_dataloader) == 0:
logger.error(
"No Images in train dataset, please ensure\n" +
"\t1. The images num in the train label_file_list should be larger than or equal with batch size.\n"
+
"\t2. The annotation file and path in the configuration file are provided normally."
)
return
if config['Eval']:
valid_dataloader = build_dataloader(config, 'Eval', device, logger)
else:
valid_dataloader = None
# build post process
post_process_class = build_post_process(config['PostProcess'],
global_config)
# build model
# for rec algorithm
if hasattr(post_process_class, 'character'):
char_num = len(getattr(post_process_class, 'character'))
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
config['Architecture']["Models"][key]["Head"][
'out_channels'] = char_num
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
model = build_model(config['Architecture'])
if config['Global']['distributed']:
model = paddle.DataParallel(model)
# build loss
loss_class = build_loss(config['Loss'])
# build optim
optimizer, lr_scheduler = build_optimizer(
config['Optimizer'],
epochs=config['Global']['epoch_num'],
step_each_epoch=len(train_dataloader),
parameters=model.parameters())
# build metric
eval_class = build_metric(config['Metric'])
# load pretrain model
pre_best_model_dict = load_model(config, model, optimizer)
logger.info('train dataloader has {} iters'.format(len(train_dataloader)))
if valid_dataloader is not None:
logger.info('valid dataloader has {} iters'.format(
len(valid_dataloader)))
use_amp = config["Global"].get("use_amp", False)
if use_amp:
AMP_RELATED_FLAGS_SETTING = {
'FLAGS_cudnn_batchnorm_spatial_persistent': 1,
'FLAGS_max_inplace_grad_add': 8,
}
paddle.fluid.set_flags(AMP_RELATED_FLAGS_SETTING)
scale_loss = config["Global"].get("scale_loss", 1.0)
use_dynamic_loss_scaling = config["Global"].get(
"use_dynamic_loss_scaling", False)
scaler = paddle.amp.GradScaler(
init_loss_scaling=scale_loss,
use_dynamic_loss_scaling=use_dynamic_loss_scaling)
else:
scaler = None
# start train
program.train(config, train_dataloader, valid_dataloader, device, model,
loss_class, optimizer, lr_scheduler, post_process_class,
eval_class, pre_best_model_dict, logger, vdl_writer, scaler)
复制PaddleOCR 识别任务与检测任务类似,是通过配置文件传输参数的。
要进行完整的模型训练,首先需要下载整个项目并安装相关依赖:
# 克隆PaddleOCR代码
#!git clone https://gitee.com/paddlepaddle/PaddleOCR
# 修改代码运行的默认目录为 /home/aistudio/PaddleOCR
import os
os.chdir("/home/aistudio/PaddleOCR")
# 安装PaddleOCR第三方依赖
!pip install -r requirements.txt
复制创建软链,将训练数据放在PaddleOCR项目下:
!ln -s /home/aistudio/work/train_data/ /home/aistudio/PaddleOCR/
复制下载预训练模型:
为了加快收敛速度,建议下载训练好的模型在 icdar2015 数据上进行 finetune
!cd PaddleOCR/
# 下载MobileNetV3的预训练模型
!wget -nc -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_mv3_none_bilstm_ctc_v2.0_train.tar
# 解压模型参数
!tar -xf pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train.tar && rm -rf pretrain_models/rec_mv3_none_bilstm_ctc_v2.0_train.tar
复制启动训练命令很简单,指定好配置文件即可。另外在命令行中可以通过 -o 修改配置文件中的参数值。启动训练命令如下所示
其中:
Global.pretrained_model: 加载的预训练模型路径Global.character_dict_path : 字典路径(这里只支持26个小写字母+数字)Global.eval_batch_step : 评估频率,[0,200] 从第0次开始计算,每200次评估一次Global.epoch_num: 总训练轮数# -o 修改默认的参数值,命令行修改优先级会更高
!python3 tools/train.py -c configs/rec/rec_icdar15_train.yml \
-o Global.pretrained_model=rec_mv3_none_bilstm_ctc_v2.0_train/best_accuracy \
Global.character_dict_path=ppocr/utils/ic15_dict.txt \
Global.eval_batch_step=[0,200] \
Global.epoch_num=40 \
Global.use_gpu=false
复制根据配置文件中设置的的 save_model_dir 字段,会有以下几种参数被保存下来:
output/rec/ic15
├── best_accuracy.pdopt # 每次评估时,拿到的最优评估结果
├── best_accuracy.pdparams
├── best_accuracy.states
├── config.yml # 命令行修改后的参数(当前训练的参数)
├── iter_epoch_3.pdopt # 每3个epoch保存一次,会看到 epoch_3、epoch_6、epoch_9 训练的中间状态,可以在配置文件中修改保存的频度
├── iter_epoch_3.pdparams
├── iter_epoch_3.states
├── latest.pdopt
├── latest.pdparams
├── latest.states
└── train.log
复制其中 best_accuracy.* 是评估集上的最优模型;iter_epoch_x.* 是以 save_epoch_step 为间隔保存下来的模型;latest.* 是最后一个epoch的模型。
总结:
如果需要训练自己的数据需要修改:
评估数据集可以通过 configs/rec/rec_icdar15_train.yml 修改Eval中的 label_file_path 设置。
这里默认使用 icdar2015 的评估集,加载刚刚训练好的模型权重:
!python tools/eval.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=output/rec/ic15/best_accuracy \ Global.character_dict_path=ppocr/utils/ic15_dict.txt复制
评估后,可以看到训练模型在验证集上的精度。
PaddleOCR支持训练和评估交替进行, 可在 configs/rec/rec_icdar15_train.yml 中修改 eval_batch_step 设置评估频率,默认每2000个iter评估一次。评估过程中默认将最佳acc模型,保存为 output/rec/ic15/best_accuracy 。
如果验证集很大,测试将会比较耗时,建议减少评估次数,或训练完再进行评估。
使用 PaddleOCR 训练好的模型,可以通过以下脚本进行快速预测。
预测图片:

默认预测图片存储在 infer_img 里,通过 -o Global.checkpoints 加载训练好的参数文件:
!python tools/infer_rec.py -c configs/rec/rec_icdar15_train.yml -o Global.checkpoints=output/rec/ic15/best_accuracy Global.character_dict_path=ppocr/utils/ic15_dict.txt复制
得到输入图像的预测结果:
infer_img: doc/imgs_words_en/word_19.png
result: slow 0.8795223
复制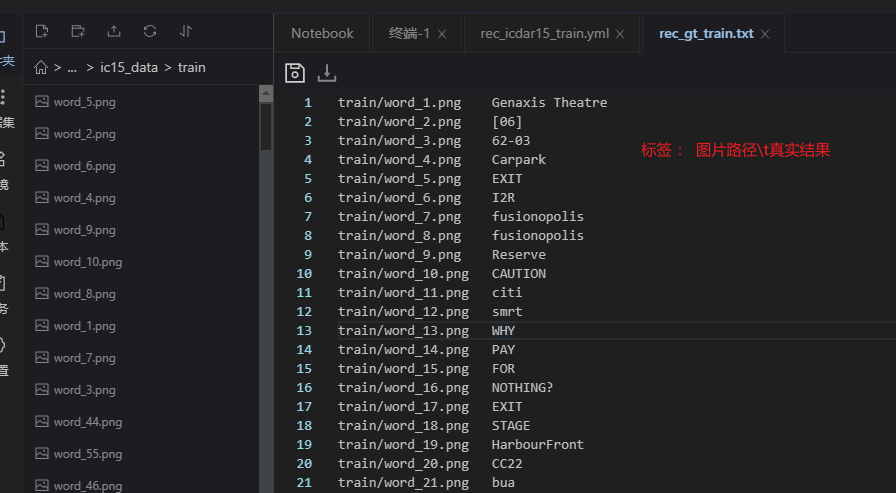
原文:AI Studio学习『动手学OCR·十讲』https://aistudio.baidu.com/aistudio/course/introduce/25207?sharedLesson=2077537&sharedType=2&sharedUserId=2631487&ts=1685512885510