基础
自然语言处理(NLP)
自然语言处理PaddleNLP-词向量应用展示
自然语言处理(NLP)-前预训练时代的自监督学习
自然语言处理PaddleNLP-预训练语言模型及应用
自然语言处理PaddleNLP-文本语义相似度计算(ERNIE-Gram)
自然语言处理PaddleNLP-词法分析技术及其应用
自然语言处理PaddleNLP-快递单信息抽取
理解
自然语言处理PaddleNLP-信息抽取技术及应用
自然语言处理PaddleNLP-基于预训练模型完成实体关系抽取--实践
自然语言处理PaddleNLP-情感分析技术及应用-理论
自然语言处理PaddleNLP-情感分析技术及应用SKEP-实践
问答
自然语言处理PaddleNLP-检索式文本问答-理论
自然语言处理PaddleNLP-结构化数据问答-理论
翻译
自然语言处理PaddleNLP-文本翻译技术及应用-理论
自然语言处理PaddleNLP-机器同传技术及应用-理论
对话
自然语言处理PaddleNLP-任务式对话系统-理论
自然语言处理PaddleNLP-开放域对话系统-理论
产业实践
自然语言处理 Paddle NLP - 预训练模型产业实践课-理论
词向量(Word embedding),即把词语表示成实数向量。“好”的词向量能体现词语直接的相近关系。词向量已经被证明可以提高NLP任务的性能,例如语法分析和情感分析。
PaddleNLP已预置多个公开的预训练Embedding,您可以通过使用paddlenlp.embeddings.TokenEmbedding接口加载各种预训练Embedding。本篇教程将介绍paddlenlp.embeddings.TokenEmbedding的使用方法,计算词与词之间的语义距离,并结合词袋模型获取句子的语义表示。
字典:有字,有索引(位置编码),就构成了一个字典,如下表
调词向量,是通过编码,去查词向量矩阵,通过 0 查到 人们
| 字 | 位置编码 |
|---|---|
| 人们 | 0 |
| 二 | 1 |
| 3 | 2 |
| 预训练模型中的字典,会和这边介绍的有所不同,分词后可能会变成拆开的 | |
| 字 | 位置编码 |
| ------------ | ------------ |
| 人 | 0 |
| 们 | 1 |
| 二 | 2 |
| 3 | 3 |
TokenEmbedding()参数
embedding_namew2v.baidu_encyclopedia.target.word-word.dim300的词向量。unknown_tokenunknown_token_vectorextended_vocab_pathtrainablehttps://gitee.com/paddlepaddle/PaddleNLP/blob/develop/paddlenlp/embeddings/token_embedding.py
def __init__(
self,
embedding_name=EMBEDDING_NAME_LIST[0], # 词向量名字
unknown_token=UNK_TOKEN,
unknown_token_vector=None,
extended_vocab_path=None,
trainable=True,
keep_extended_vocab_only=False,
):
...
# 是否要进行梯度更新,默认不做
def set_trainable(self, trainable):
# 查找词向量
def search(self, words):
# 通过词,找对应的ID
def get_idx_from_word(self, word):
# 余弦相似度
def cosine_sim(self, word_a, word_b):
w2v.baidu_encyclopedia.target.word-word.dim300 左右方向 300,上下方向:3万个
300维,每个词对应的词向量,训练词向量时,设置好的参数,如果设置200维,训练出来的所有词的词向量都是200维,将词压缩到300维空间做Embedding嵌入方式表征得到的结果。
300维这个数字是经验得来的,比较大,相对准一些,如果追求速度,就用100维的
Token: 比如打一句话,把它拆成中文能理解的一个个词,这个词就是一个Token,如果拆成一个字一个字,字就是 Token,NLP里就是这么叫的。专业词汇
常用的分词工具:jieba、IAC(百度)

医疗、法律,不建议使用训练好的通用词向量,需要自己去训练,会达到意想不到的效果
# TokenEmbedding => 向量矩阵 Skip-gram 中的 训练好的 W
from paddlenlp.embeddings import TokenEmbedding
# 初始化TokenEmbedding, 预训练embedding未下载时会自动下载并加载数据
# 中英文混杂比较厉害时不建议使用 训练好的词向量 `w2v.baidu_encyclopedia.target.word-word.dim300`,如果有就能调到如果没有就UNK,所以需要自己去训练
# https://gitee.com/paddlepaddle/PaddleNLP/blob/develop/paddlenlp/embeddings/constant.py
token_embedding = TokenEmbedding(embedding_name="w2v.baidu_encyclopedia.target.word-word.dim300")
# 查看token_embedding详情
print(token_embedding)
TokenEmbedding.search()
获得指定词汇的词向量。
test_token_embedding = token_embedding.search("中国")
print(test_token_embedding)
# 300维向量
[[ 0.260801 0.1047 0.129453 -0.257317 -0.16152 0.19567 -0.074868
0.361168 0.245882 -0.219141 -0.388083 0.235189 0.029316 0.154215
-0.354343 0.017746 0.009028 0.01197 -0.121429 0.096542 0.009255
0.039721 0.363704 -0.239497 -0.41168 0.16958 0.261758 0.022383
...
0.123634 0.282932 0.140399 -0.076253 -0.087103 0.07262 ]]
TokenEmbedding.cosine_sim()
计算词向量间余弦相似度,语义相近的词语余弦相似度更高,说明预训练好的词向量空间有很好的语义表示能力。
# 查找两个词之间的相似距离,向量的余弦夹角
score1 = token_embedding.cosine_sim("女孩", "女人")
score2 = token_embedding.cosine_sim("女孩", "书籍")
print('score1:', score1)
print('score2:', score2)
# 应用场景:输入法,
# (搜索、论文查重,是通过现有词向量,再做句子的表征,这样才能做句子和句子之间的匹配)
score1: 0.7017183
score2: 0.19189896
使用深度学习可视化工具VisualDL的High Dimensional组件可以对embedding结果进行可视化展示,便于对其直观分析,步骤如下:
pip install --upgrade visualdl
创建LogWriter并将记录词向量。
点击左侧面板中的可视化tab,选择‘token_hidi’作为文件并启动VisualDL可视化
# 获取词表中前1000个单词
labels = token_embedding.vocab.to_tokens(list(range(0, 1000)))
# 取出这1000个单词对应的Embedding
test_token_embedding = token_embedding.search(labels)
# 引入VisualDL的LogWriter记录日志
from visualdl import LogWriter
with LogWriter(logdir='./token_hidi') as writer:
writer.add_embeddings(tag='test', mat=[i for i in test_token_embedding], metadata=labels)
启动步骤:

可以看出,语义相近的词在词向量空间中聚集(如数字、章节等),说明预训练好的词向量有很好的文本表示能力。
使用VisualDL除可视化embedding结果外,还可以对标量、图片、音频等进行可视化,有效提升训练调参效率。关于VisualDL更多功能和详细介绍,可参考VisualDL使用文档。
在许多实际应用场景(如文档检索系统)中, 需要衡量两个句子的语义相似程度。此时我们可以使用词袋模型(Bag of Words,简称BoW)计算句子的语义向量。
首先,将两个句子分别进行切词,并在TokenEmbedding中查找相应的单词词向量(word embdding)。
然后,根据词袋模型,将句子的word embedding叠加作为句子向量(sentence embedding)。
最后,计算两个句子向量的余弦相似度。
相对于RNN,CNN,用词向量构造的句子表征有哪些优点:
在做一些相似度问题的时候,不管是检索还是其它搜索等等应用场景,做句子和句子匹配的一些相似度问题时,都可以分成两步
使用BoWEncoder搭建一个BoW模型用于计算句子语义。
paddlenlp.TokenEmbedding组建word-embedding层paddlenlp.seq2vec.BoWEncoder组建句子建模层,最简单,最快速的构建方式,常见的建模方式PaddleNLP 已封装了下列模型
https://gitee.com/paddlepaddle/PaddleNLP/blob/develop/paddlenlp/seq2vec/encoder.py
__all__ = ["BoWEncoder", "CNNEncoder", "GRUEncoder", "LSTMEncoder", "RNNEncoder", "TCNEncoder"]
源码解读:
import paddle
import paddle.nn as nn
import paddlenlp
class BoWModel(nn.Layer):
def __init__(self, embedder):
super().__init__()
self.embedder = embedder # TokenEmbedding 300的词向量
emb_dim = self.embedder.embedding_dim
self.encoder = paddlenlp.seq2vec.BoWEncoder(emb_dim) # 把 300 维度传进去,进行初始化,词带模型就搭好了。
self.cos_sim_func = nn.CosineSimilarity(axis=-1) # 余弦相似度的计算公式
# 判断两个句子的相似度
def get_cos_sim(self, text_a, text_b):
text_a_embedding = self.forward(text_a) #句子A的向量
text_b_embedding = self.forward(text_b) #句子B的向量
cos_sim = self.cos_sim_func(text_a_embedding, text_b_embedding) # 余弦相似度计算
return cos_sim
# 模型数据扭转方式
def forward(self, text):
# 南哥来听课,南哥:1、来:3、听课:7、冒号:0 => text = 1 3 7 0
# batch_size = N 句话
# Shape: (batch_size, num_tokens, embedding_dim)
# 数据进来先过哪个层(上面定义好的 embedding 层
embedded_text = self.embedder(text)
# embedded_text 张量 => [[1对应300维的向量] [3对应300维的向量] [7对应300维的向量] [0对应300维的向量]]
# Shape: (batch_size, embedding_dim)
summed = self.encoder(embedded_text)
# 最终形成句子表征
return summed
# 模型的初始化(实类化)
model = BoWModel(embedder=token_embedding)
def forward(self, inputs, mask=None):
....
# Shape: (batch_size, embedding_dim)
# 沿着axis = 1 轴方向求和 ,就是将 1的位置相加、2的位置相加....、300的位置相加,得到整个句子的句向量
# 用词带的方式得到句子向量的表征,表达的句子简单些,想更准确些,可以加一下 tfidf 权重因子
summed = inputs.sum(axis=1)
return summed
class RNNEncoder(nn.Layer):
...
encoded_text, last_hidden = self.rnn_layer(inputs, sequence_length=sequence_length)
if not self._pooling_type:
# We exploit the `last_hidden` (the hidden state at the last time step for every layer)
# to create a single vector.
# If rnn is not bidirection, then output is the hidden state of the last time step
# at last layer. Output is shape of `(batch_size, hidden_size)`.
# If rnn is bidirection, then output is concatenation of the forward and backward hidden state
# of the last time step at last layer. Output is shape of `(batch_size, hidden_size * 2)`.
if self._direction != "bidirect":
output = last_hidden[-1, :, :]
else:
output = paddle.concat((last_hidden[-2, :, :], last_hidden[-1, :, :]), axis=1)
else:
# We exploit the `encoded_text` (the hidden state at the every time step for last layer)
# to create a single vector. We perform pooling on the encoded text.
# The output shape is `(batch_size, hidden_size * 2)` if use bidirectional RNN,
# otherwise the output shape is `(batch_size, hidden_size * 2)`.
# 池化层的操作
if self._pooling_type == "sum": # 求和池化
output = paddle.sum(encoded_text, axis=1)
elif self._pooling_type == "max": # 最大池化
output = paddle.max(encoded_text, axis=1)
elif self._pooling_type == "mean": # 平均池化
output = paddle.mean(encoded_text, axis=1)
else:
raise RuntimeError(
"Unexpected pooling type %s ."
"Pooling type must be one of sum, max and mean." % self._pooling_type
)
return output
data.py
import numpy as np
import jieba
import paddle
from collections import defaultdict
from paddlenlp.data import JiebaTokenizer, Pad, Stack, Tuple, Vocab
class Tokenizer(object):
def __init__(self):
self.vocab = {}
self.tokenizer = jieba
self.vocab_path = 'vocab.txt'
self.UNK_TOKEN = '[UNK]'
self.PAD_TOKEN = '[PAD]'
def set_vocab(self, vocab):
self.vocab = vocab
self.tokenizer = JiebaTokenizer(vocab)
def build_vocab(self, sentences):
word_count = defaultdict(lambda: 0)
for text in sentences:
words = jieba.lcut(text)
for word in words:
word = word.strip()
if word.strip() !='':
word_count[word] += 1
word_id = 0
for word, num in word_count.items():
if num < 5:
continue
self.vocab[word] = word_id
word_id += 1
self.vocab[self.UNK_TOKEN] = word_id
self.vocab[self.PAD_TOKEN] = word_id + 1
self.vocab = Vocab.from_dict(self.vocab,
unk_token=self.UNK_TOKEN, pad_token=self.PAD_TOKEN)
# dump vocab to file
self.dump_vocab(self.UNK_TOKEN, self.PAD_TOKEN)
self.tokenizer = JiebaTokenizer(self.vocab)
return self.vocab
def dump_vocab(self, unk_token, pad_token):
with open(self.vocab_path, "w", encoding="utf8") as f:
for word in self.vocab._token_to_idx:
f.write(word + "\n")
def text_to_ids(self, text):
input_ids = []
unk_token_id = self.vocab[self.UNK_TOKEN]
for token in self.tokenizer.cut(text):
token_id = self.vocab.token_to_idx.get(token, unk_token_id)
input_ids.append(token_id)
return input_ids
def convert_example(self, example, is_test=False):
input_ids = self.text_to_ids(example['text'])
if not is_test:
label = np.array(example['label'], dtype="int64")
return input_ids, label
else:
return input_ids
def create_dataloader(dataset,
trans_fn=None,
mode='train',
batch_size=1,
pad_token_id=0):
"""
Creats dataloader.
Args:
dataset(obj:`paddle.io.Dataset`): Dataset instance.
mode(obj:`str`, optional, defaults to obj:`train`): If mode is 'train', it will shuffle the dataset randomly.
batch_size(obj:`int`, optional, defaults to 1): The sample number of a mini-batch.
pad_token_id(obj:`int`, optional, defaults to 0): The pad token index.
Returns:
dataloader(obj:`paddle.io.DataLoader`): The dataloader which generates batches.
"""
if trans_fn:
dataset = dataset.map(trans_fn, lazy=True)
shuffle = True if mode == 'train' else False
sampler = paddle.io.BatchSampler(
dataset=dataset, batch_size=batch_size, shuffle=shuffle)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=pad_token_id), # input_ids
Stack(dtype="int64") # label
): [data for data in fn(samples)]
dataloader = paddle.io.DataLoader(
dataset,
batch_sampler=sampler,
return_list=True,
collate_fn=batchify_fn)
return dataloader
使用TokenEmbedding词表构造Tokenizer。
from data import Tokenizer
tokenizer = Tokenizer() # 分词
tokenizer.set_vocab(vocab=token_embedding.vocab) # 加载字典
以提供的样例数据text_pair.txt为例,该数据文件每行包含两个句子。
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 多项式矩阵的左共轭积及其应用
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 退化阻尼对高维可压缩欧拉方程组经典解的影响
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 Burgers方程基于特征正交分解方法的数值解法研究
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 有界对称域上解析函数空间的若干性质
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 基于卷积神经网络的图像复杂度研究与应用
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 Cartesian发射机中线性功率放大器的研究
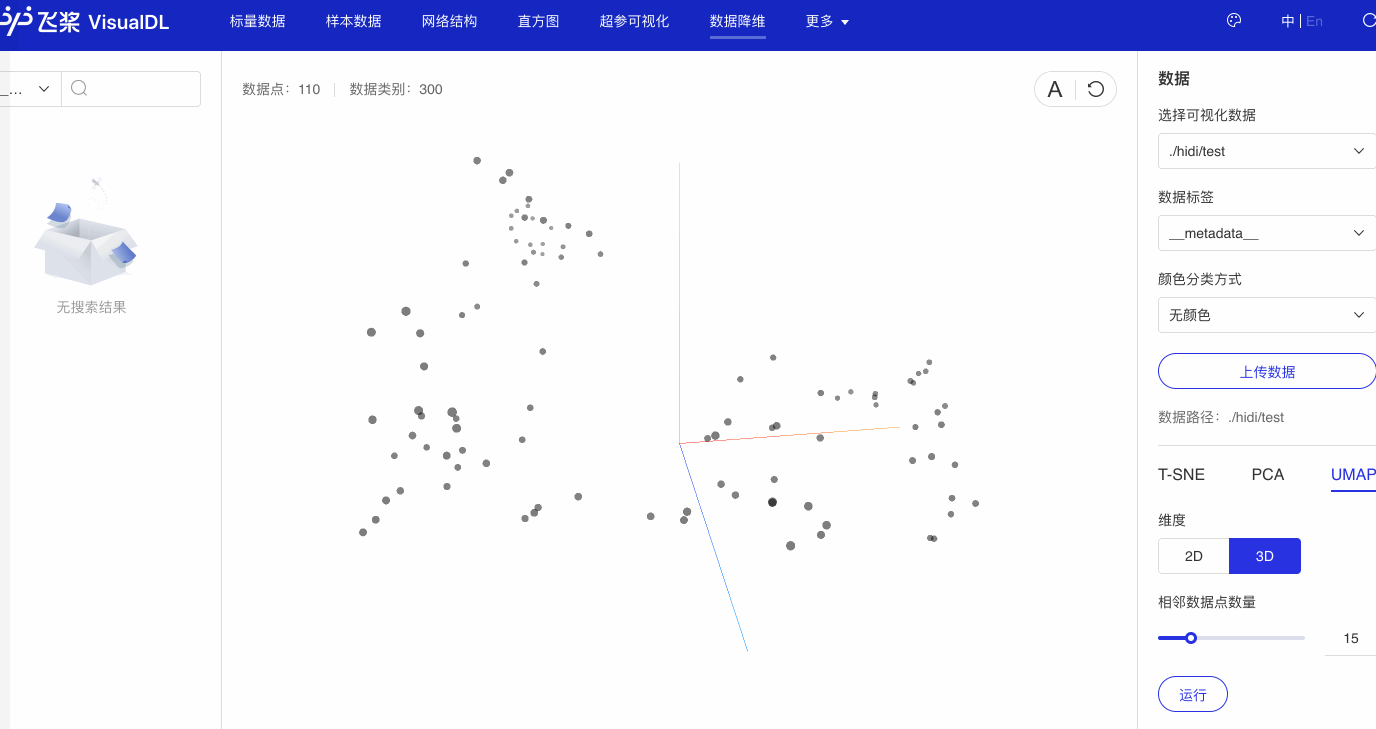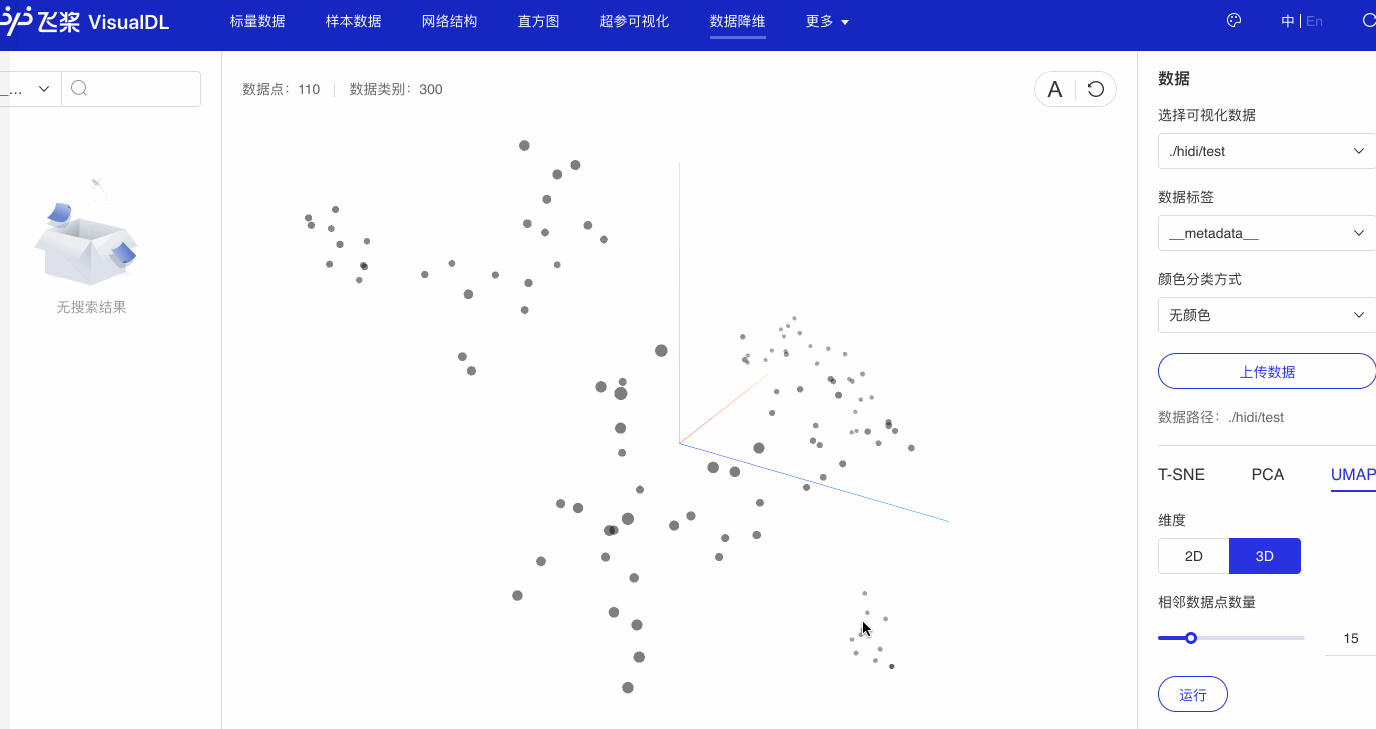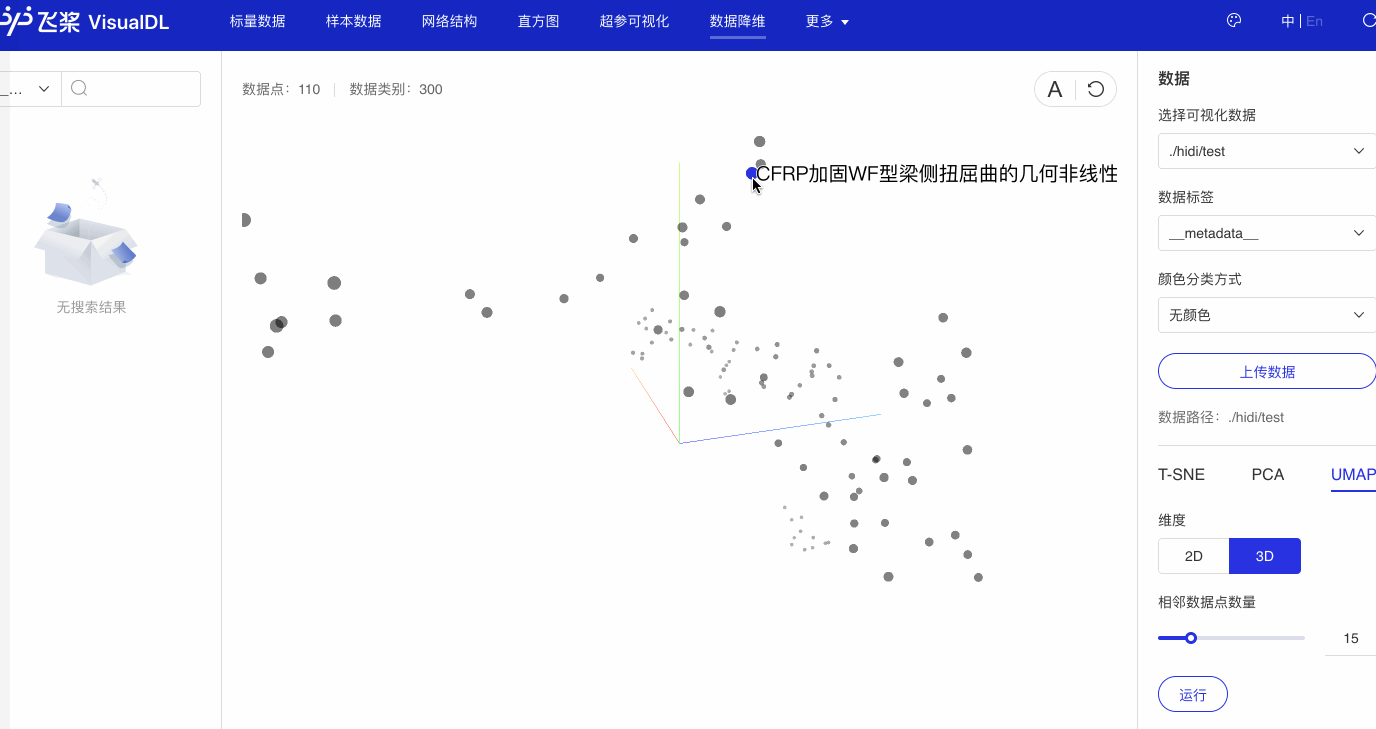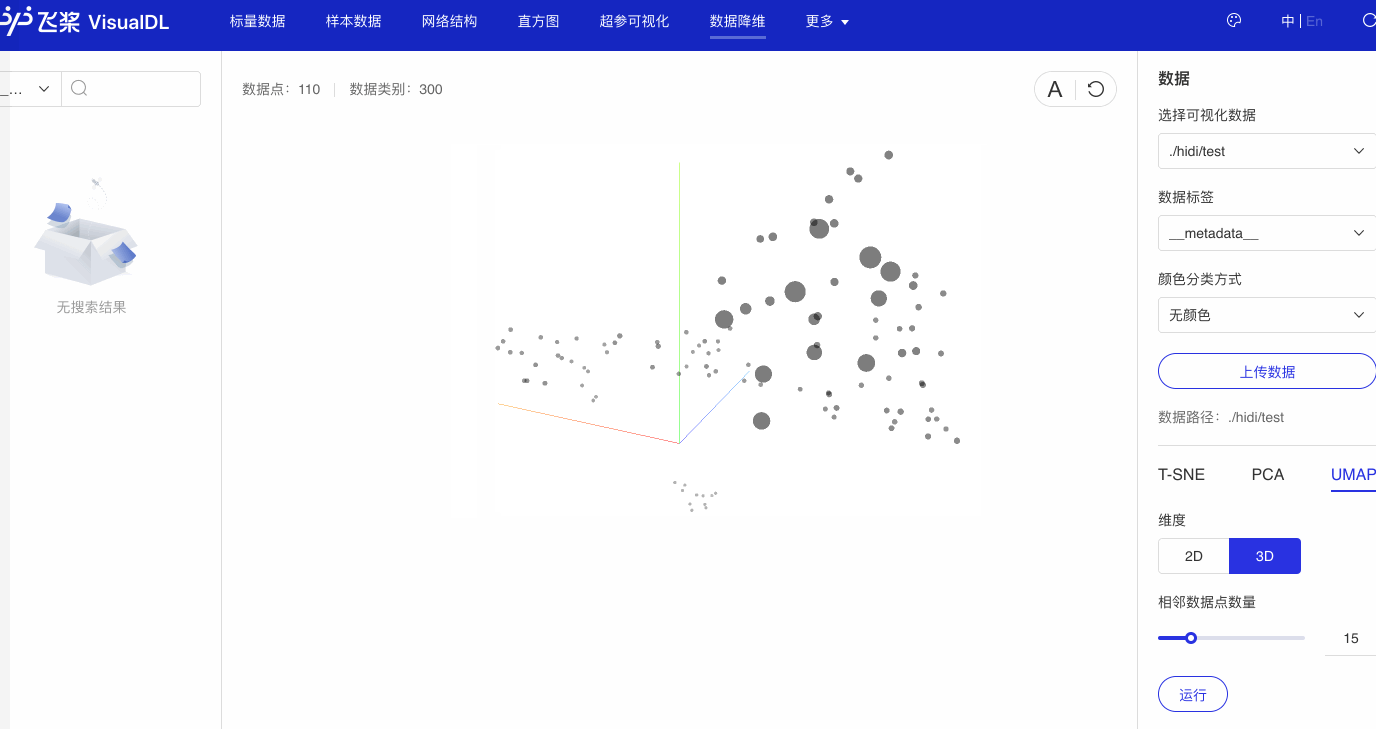
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 CFRP加固WF型梁侧扭屈曲的几何非线性有限元分析
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 基于线性CCD自适应成像的光刻机平台调平方法研究
多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解 基于变分贝叶斯理论的图像复原方法研究
text_pairs = {}
with open("text_pair.txt", "r", encoding="utf8") as f:
for line in f:
text_a, text_b = line.strip().split("\t")
if text_a not in text_pairs:
text_pairs[text_a] = []
text_pairs[text_a].append(text_b)
for text_a, text_b_list in text_pairs.items():
text_a_ids = paddle.to_tensor([tokenizer.text_to_ids(text_a)])
for text_b in text_b_list:
text_b_ids = paddle.to_tensor([tokenizer.text_to_ids(text_b)])
print("text_a: {}".format(text_a))
print("text_b: {}".format(text_b))
print("cosine_sim: {}".format(model.get_cos_sim(text_a_ids, text_b_ids).numpy()[0]))
print()
text_a: 多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解
text_b: 多项式矩阵的左共轭积及其应用
cosine_sim: 0.8861938714981079
text_a: 多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解
text_b: 退化阻尼对高维可压缩欧拉方程组经典解的影响
cosine_sim: 0.7975839972496033
text_a: 多项式矩阵左共轭积对偶Sylvester共轭和数学算子完备参数解
text_b: Burgers方程基于特征正交分解方法的数值解法研究
cosine_sim: 0.8188782930374146
# 引入VisualDL的LogWriter记录日志
import numpy as np
from visualdl import LogWriter
# 获取句子以及其对应的向量
label_list = []
embedding_list = []
for text_a, text_b_list in text_pairs.items():
text_a_ids = paddle.to_tensor([tokenizer.text_to_ids(text_a)])
embedding_list.append(model(text_a_ids).flatten().numpy())
label_list.append(text_a)
for text_b in text_b_list:
text_b_ids = paddle.to_tensor([tokenizer.text_to_ids(text_b)])
embedding_list.append(model(text_b_ids).flatten().numpy())
label_list.append(text_b)
with LogWriter(logdir='./sentence_hidi') as writer:
writer.add_embeddings(tag='test', mat=embedding_list, metadata=label_list)
步骤如上述观察词向量降维效果一模一样。
可以看出,语义相近的句子在句子向量空间中聚集(如有关课堂的句子、有关化学描述句子等)。