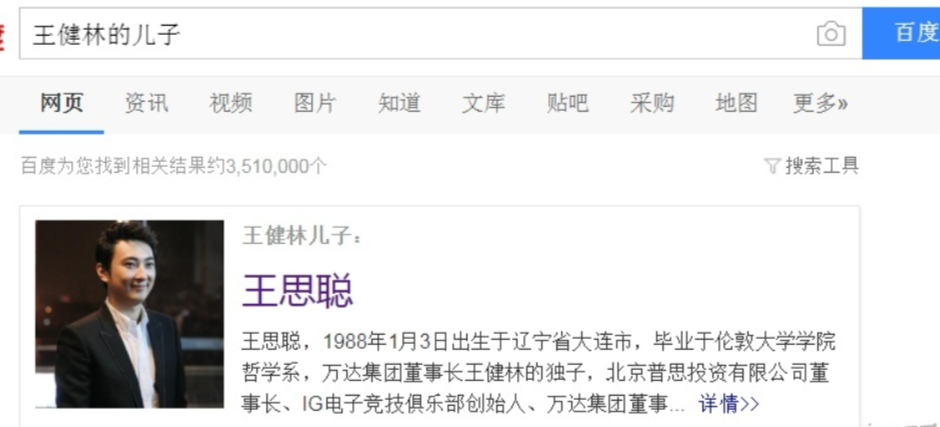
假设我们想知道 “王健林的儿子” 是谁,百度或谷歌一下,搜索引擎会准确返回王思聪的信息,说明搜索引擎理解了用户的意图,知道我们要找 “王思聪”,而不是仅仅返回关键词为 “王健林的儿子” 的网页:
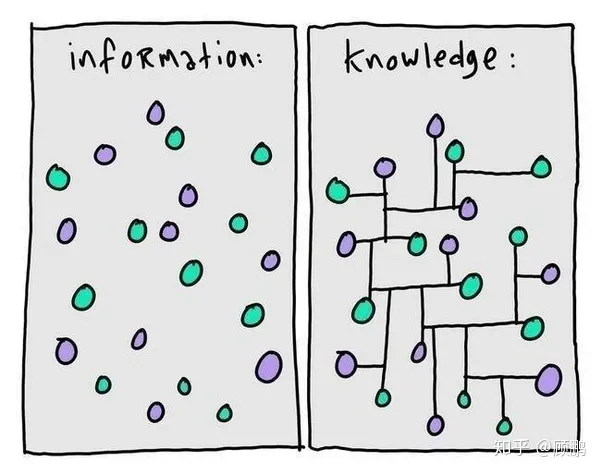
知识图谱,本质上,是一种揭示实体之间关系的语义网络,是一种基于图的数据结构。
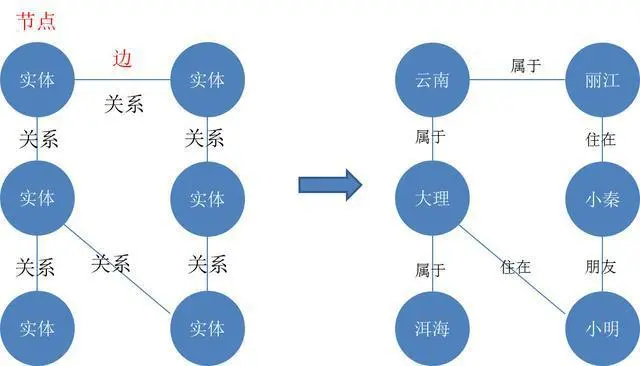
是一种结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。它的基本组成单位是“实体—关系—实体”三元组,以及实体及其相关属性—值对,实体间通过关系相互联结,构成网状的知识结构 。
语义网络(Semantic Network)是上个世纪五六十年代所提出的一种知识表示形式。如图:猫是一种哺乳动物;脊椎是哺乳动物的一部分。然而,语义网络由于缺少标准,其比较难应用于实践。
通俗定义:知识图谱就是把所有不同种类的信息连接在一起而得到的一个关系网络,因此知识图谱提供了从“关系”的角度去分析问题的能力。
基本的数据结构表达式是:G=(V,E),V=vertex(节点),E=edge(边)
实体指的可以是现实世界中的事物,比如人、地名、公司、电话、动物等;关系则用来表达不同实体之间的某种联系。
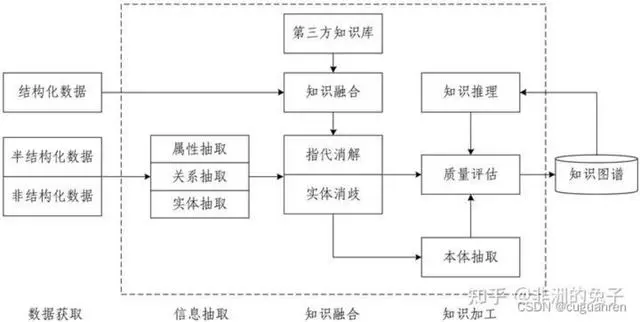
知识图谱构建的过程中,最主要的一个步骤就是把数据从不同的数据源中抽取出来,然后按一定的规则加入到知识图谱中,这个过程我们称为知识抽取。
数据源的分为两种:
具体是怎么实现的呢,接下来一一讨论。
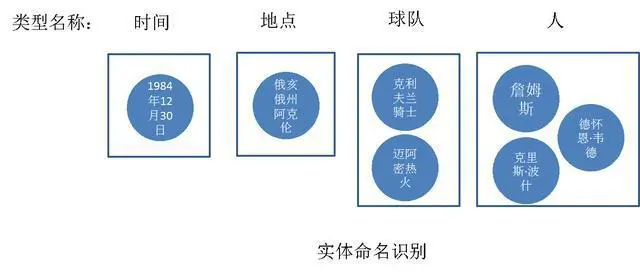
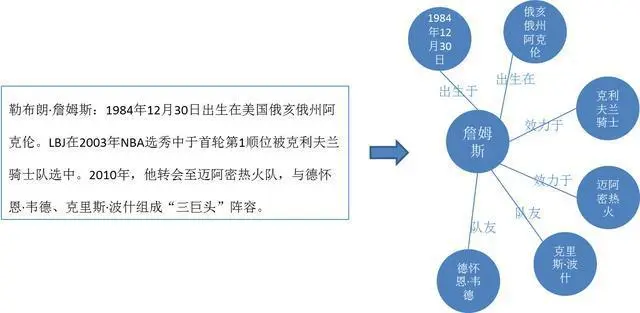
提取文本中的实体,并对每个实体进行分类或打标签,比如把文中“1984年12月30日”记为“时间”类型;“克利夫兰骑士”和“迈阿密热火”记为“球队”类型,这个过程就是实体命名。
知识抽取主要是面向开放的链接数据,通过自动化的技术抽取出可用的知识单元,知识单元主要包括实体(概念的外延)、关系以及属性3个知识要素,并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。知识抽取有三个主要工作:
实体抽取:在技术上我们更多称为 NER(named entity recognition,命名实体识别),指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步;
关系抽取:目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则
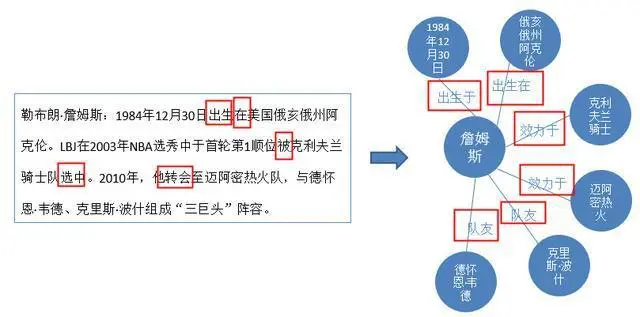
关系抽取是把实体之间的关系抽取出来的一项技术,其中主要是根据文本中的一些关键词,如“出生”、“在”、“转会”等,我们就可以判断詹姆斯与地点俄亥俄州、与迈阿密热火等实体之间的关系。
属性抽取:属性抽取主要是针对实体而言的,通过属性可形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的抽取问题转换为关系抽取问题。

在文本中可能同一个实体会有不同的写法,比如说“LBJ”就是詹姆斯的缩写,因此“勒布朗詹姆斯”和“LBJ”指的就是同一个实体,实体统一就是处理这样问题的一项技术。

指代消解跟实体统一类似,都是处理同一个实体的问题。比如说文本中的“他”其实指的就是“勒布朗詹姆斯”。所以指代消解要做的事情就是,找出这些代词,都指的是哪个实体。
指代消解和实体统一是知识抽取中比较难的环节。
知识图谱主要有两种存储方式:
RDF
图数据库
通用知识图谱:不太涉及行业知识及专业内容,一般是解决科普类、常识类等问题。主要应用于面向互联网的搜索、推荐、问答等业务场景。比如,搜索李小龙有几部电影,战狼2的导演是谁等。
行业知识图谱:针对某个垂直行业或细分领域的深入研究而定制的版本,主要是解决当前行业或细分领域的专业问题。一些应用如下:
假设银行要借钱给一个人,那要怎么判断这个人是真实用户还是欺诈的呢?
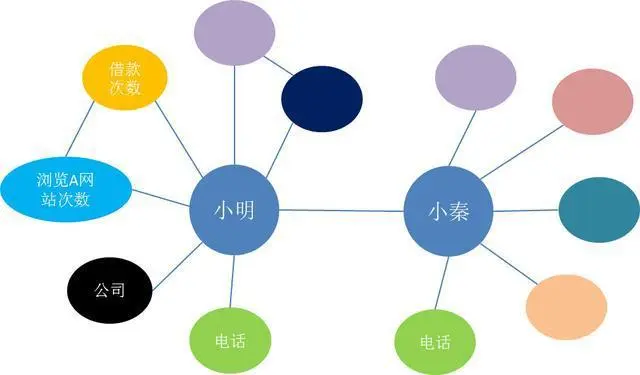
我们需要以人为核心,展开一系列的数据构建,比如说用户的基本信息、借款记录、工作信息、消费记录、行为记录、网站浏览记录等等。把这些信息整合到知识图谱中。从而整体进行预测和评分,用户欺诈行为的概率有多大。当然这个预测是需要通过机器学习,得到一个合理的模型,模型中可能会包括消费记录的权重、网站浏览记录的权重等等信息。
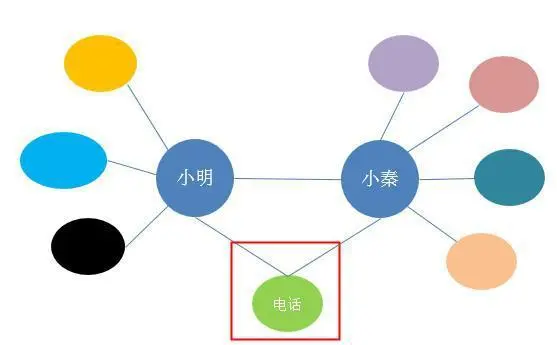
比如说不同的两个借款人,却填写了同一个电话号码,那说明这两个人中至少有一个是可疑的了,这时就需要重点关注了。
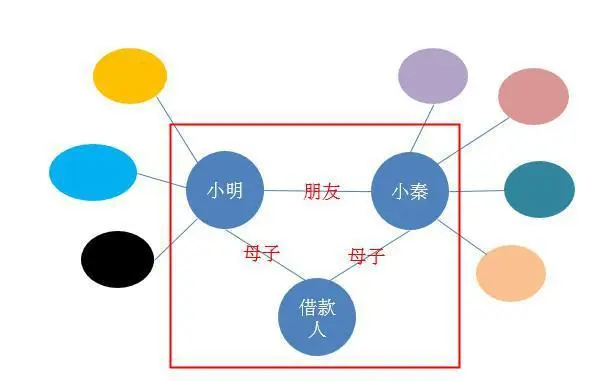
更复杂点的,可能需要知识图谱通过一些关系去推理了。比如说“借款人”跟小明和小秦都是母子关系,按推理的话小明跟小秦应该是兄弟关系,而在知识图谱上显示的是朋友关系,就有可能有异常了,因此也需要重点关注。
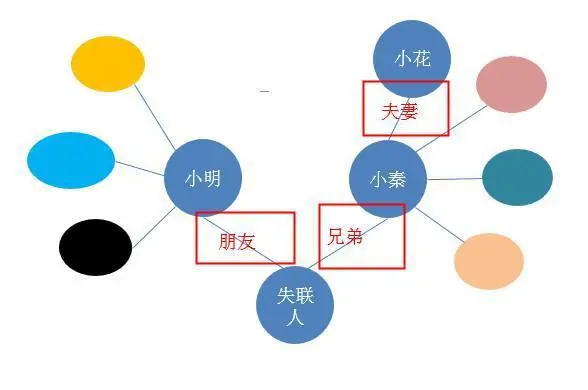
如果借款人失联了,通过知识图谱,是不是可以联系他的朋友,或兄弟,甚至是兄弟的妻子,去追踪失联人。
因此在失联的情况下,知识图谱可以挖掘更多失联人的联系人,从而提高催收效率。
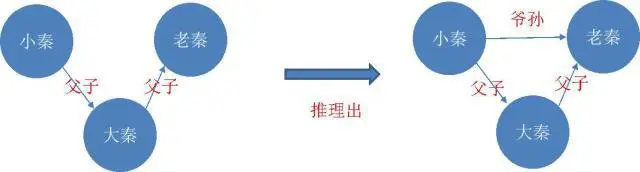
如上左图(注意这里的箭头方向),小秦是大秦的儿子,大秦是老秦的儿子,从这这样的关系,我们就可以推理出,小秦是老秦的孙子,这样就能使知识图谱更加完善了。
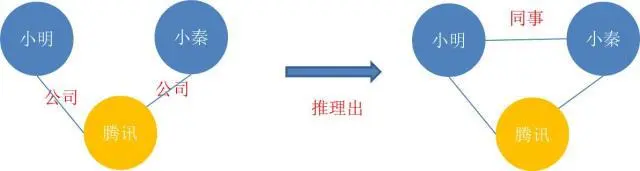
如上左图,小明在腾讯上班,小秦也在腾讯上班,从这样的关系,我们可以推理出,小明和小秦是同事关系。
推理能力其实就是机器模仿人的一种重要的能力,可以从已有的知识中发现一些隐藏的知识。当然这样的能力离不开深度学习,而随着深度学习的不断成熟,我相信知识图谱的能力也会越来越强大。
在此就介绍完了知识图谱的一些简单知识,在写这篇文章的同时,也参考了很多业界优秀大佬的文章,感谢各位大佬的无私分享。