Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据)
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
print(myvar[1]) # 2
复制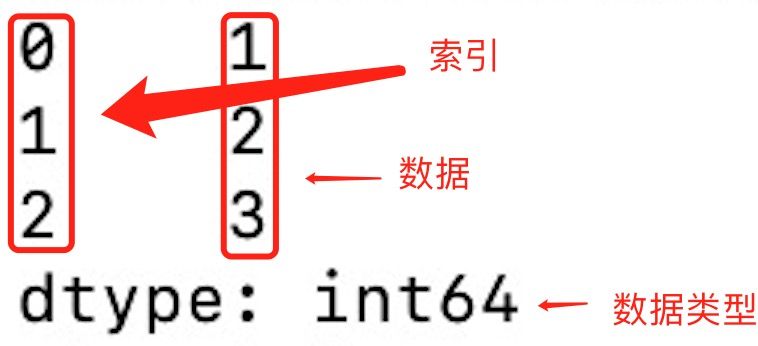
如果没有指定索引,索引值就从 0 开始,
如下实例:
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
print(myvar["y"]) # Runoob
复制
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
复制
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)
复制
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
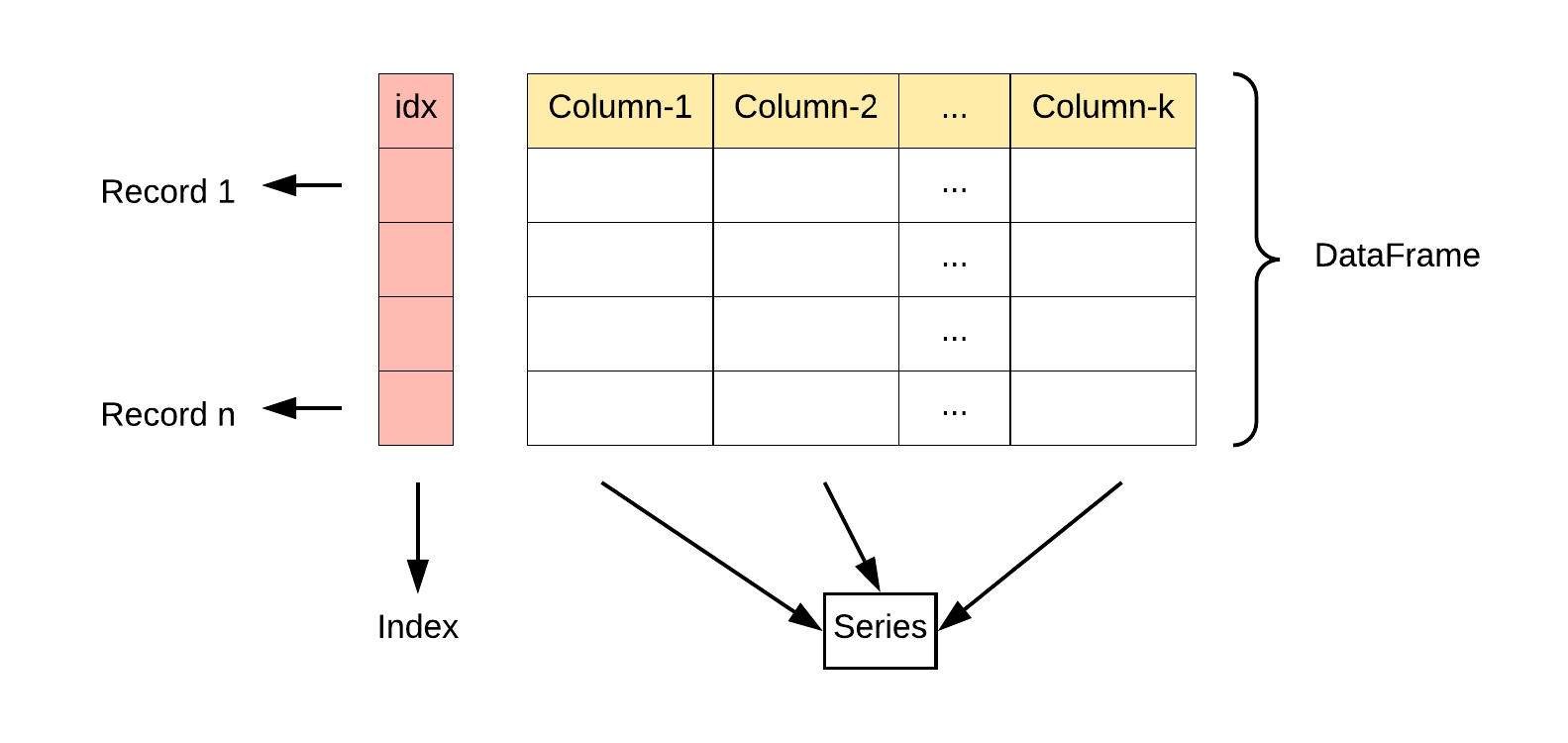
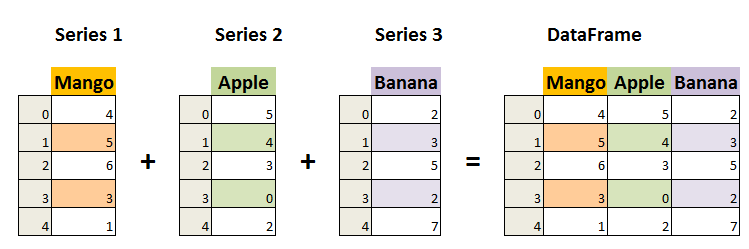
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
# data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]} # 也可以这样写
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
复制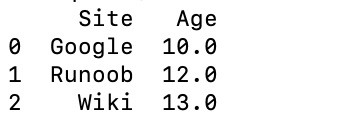
DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):

import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
复制输出
a b c
0 1 2 NaN
1 5 10 20.0
复制import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
# calories 420
# duration 50
print(df.loc[0])
# 返回第二行
# calories 380
# duration 40
print(df.loc[1])
# 返回第一行和第三行
# calories duration
#0 420 50
#2 390 45
print(df.loc[[0, 2]])
复制