Redis作为基于内存的非关系型的K-V数据库。因读写响应快速、原子操作、提供了多种数据类型String、List、Hash、Set、Sorted Set、在项目中有着广泛的使用,今天我们来探讨下下Redis的数据结构是如何实现的。
Redis将数据存储在redisDb中,默认0~15共16个db。每个库都是独立的空间,不必担心key冲突问题,可通过select命令切换db。集群模式使用db0
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
dict *expires; /* Timeout of keys with a timeout set */
...
} redisDb;
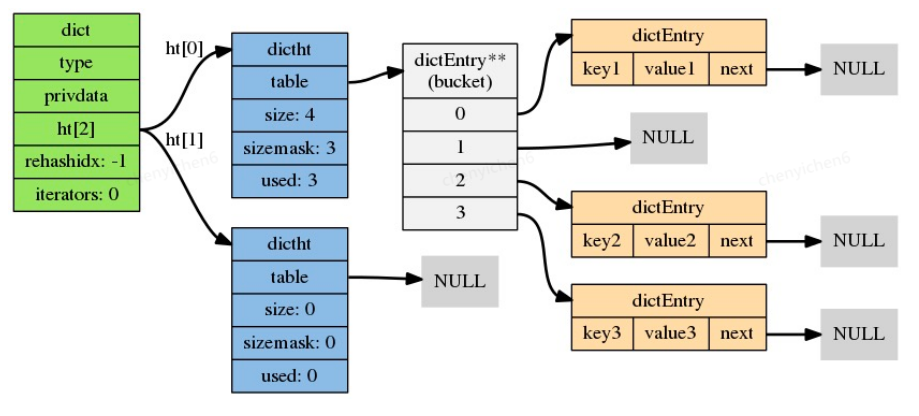
复制2.2.1 哈希字典dict
K-V存储我们最先想到的就是map,在Redis中通过dict实现,数据结构如下:
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
复制hash数据存在两个特点:
针对hash数据的特点,存在hash碰撞的问题,dict通过dictType中的函数能够解决这个问题
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
...
} dictType;
复制2.2.2 哈希表 dictht
dict.h/dictht表示一个哈希表,具体结构如下:
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
复制键值对dict.h/dictEntry
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
复制使用hash表就一定会存在hash碰撞的问题,hash碰撞后在当前数组节点形成一个链表,在数据量超过hash表长度的情况下,就会存在大量节点称为链表,极端情况下时间复杂度会从O(1)变为O(n);如果hash表的数据再不断减少,会造成空间浪费的情况。Redis会针对这两种情况根据负载因子做扩展与收缩操作:
收缩操作:
Redis在扩容时如果全量扩容会因为数据量问题导致客户端操作短时间内无法处理,所以采用渐进式 rehash进行扩容,步骤如下:
在渐进式 rehash 进行期间,字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行;在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找,如果没找到的话,就会继续到ht[1]里面进行查找;新添加到字典的键值对一律会被保存到 ht[1] 里面,而ht[0]则不再进行任何添加操作:这一措施保证了ht[0]包含的键值对数量会只减不增(如果长时间不进行操作时,事件轮询进行这种操作),并随着rehash操作的执行而最终变成空表。
dict.h/redisObject
Typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS;
int refcount;
void *ptr;
}
复制完整结构图如下:
String 字符串存在有三种类型:字符串,整数,浮点。主要有以下使用场景
1)页面动态缓存
比如生成一个动态页面,首次可以将后台数据生成页面,并且存储到redis字符串中。再次访问,不再进行数据库请求,直接从redis中读取该页面。特点是:首次访问比较慢,后续访问快速。
2)数据缓存
在前后分离式开发中,有些数据虽然存储在数据库,但是更改特别少。比如有个全国地区表。当前端发起请求后,后台如果每次都从关系型数据库读取,会影响网站整体性能。
我们可以在第一次访问的时候,将所有地区信息存储到redis字符串中,再次请求,直接从数据库中读取地区的json字符串,返回给前端。
3)数据统计
redis整型可以用来记录网站访问量,某个文件的下载量。(原子自增自减)
4)时间内限制请求次数
比如已登录用户请求短信验证码,验证码在5分钟内有效的场景。当用户首次请求了短信接口,将用户id存储到redis 已经发送短信的字符串中,并且设置过期时间为5分钟。当该用户再次请求短信接口,发现已经存在该用户发送短信记录,则不再发送短信。
5)分布式session
当我们用nginx做负载均衡的时候,如果我们每个从服务器上都各自存储自己的session,那么当切换了服务器后,session信息会由于不共享而会丢失,我们不得不考虑第三应用来存储session。通过我们用关系型数据库或者redis等非关系型数据库。关系型数据库存储和读取性能远远无法跟redis等非关系型数据库。
Redis并没有直接使用C字符串实现String类型,在Redis3.2版本之前通过SDS实现
Typedef struct sdshdr {
int len;
int free;
char buf[];
};
复制3.3.1 查询时间复杂度
C获取字符串长度的复杂度为O(N)。而SDS通过len记录长度,从C的O(n)变为O(1)。
3.3.2 缓冲区溢出
C字符串不记录自身长度容易造成缓冲区溢出(buffer overflow)。SDS的空间分配策略完全杜绝了发生缓冲区溢出的可能性,当需要对SDS进行修改时,会先检查SDS的空间是否满足修改所需的要求,如果不满足的话SDS的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用SDS既不需要手动修改SDS的空间大小,也不会出现缓冲区溢出问题。
在SDS中,buf数组的长度不一定就是字符数量加一,数组里面可以包含未使用的字节,而这些字节的数量就由SDS的free属性记录。通过未使用空间,SDS实现了空间预分配和惰性空间释放两种优化策略:
3.3.3 二进制安全
C字符串中的字符必须符合某种编码(比如 ASCII,并且除了字符串的末尾之外,字符串里面不能包含空字符, 否则最先被程序读入的空字符将被误认为是字符串结尾。
SDS的API都是二进制安全的(binary-safe):都会以处理二进制的方式来处理SDS存放在buf数组里的数据,程序不会对其中的数据做任何限制、过滤、或者假设 —— 数据在写入时是什么样的,它被读取时就是什么样。redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据。
String类型所存储的数据可能会几byte存在大量这种类型数据,但len、free属性的int类型会占用4byte共8byte存储,3.2之后会根据字符串大小使用sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64数据结构存储,具体结构如下:
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
复制redisObject包装存储的value值,通过字符集编码对数据存储进行优化,string类型的编码方式有如下三种:



redis作为k-v数据存储,因查找和操作的时间复杂度都是O(1)和丰富的数据类型及数据结构的优化,了解了这些数据类型和结构更有利于我们平时对于redis的使用。下一期将对其它常用数据类型List、Hash、Set、Sorted Set所使用的ZipList、QuickList、SkipList做进一步介绍,对于文章中不清晰不准确的地方欢迎大家一起讨论交流。
作者:盛旭