接触过TensorFlow v1的朋友都知道,训练一个TF模型有三个步骤:定义输入和模型结构,创建tf.Session实例sess,执行sess.run()启动训练。不管是因为历史遗留代码或是团队保守的建模规范,其实很多算法团队仍在大量使用TF v1进行日常建模。我相信很多算法工程师执行sess.run()不下100遍,但背后的运行原理大家是否清楚呢?不管你的回答是yes or no,今天让我们一起来探个究竟。
学习静态图运行原理能干什么?掌握它对我们TF实践中的错误排查、程序定制、性能优化至关重要,是必备的前置知识。
众所周知,TensorFlow程序有两种运行选择,即静态图模式与动态图模式。
静态图采用声明式编程范式(先编译后执行),根据前端语言(如python)描述的神经网络结构和参数信息构建固定的静成计算图,静态图在执行期间不依赖前端语言,而是由TF框架负责调度执行,因此非常适合做神经网络模型的部署。用户定义的静态图经序列化后用GraphDef表达,其包含的信息有:网络连接、参数设置、损失函数、优化器等。
有了完整的静态图定义后,TF编译器将计算图转化成IR(中间表示)。初始IR会经TF编译器一系列的转换和优化策略生成等价的计算图。编译器前端转换和优化包括:自动微分、常量折叠、公共子表达式消除;编译器后端与硬件相关,其转换和优化包括:代码指令生成和编译、算子选择、内存分配、内存复用等。
综上所述,静态图的生成过程可用下图简要概适:

动态图采用命令式编程范式,即编译与执行同时发生。动态图采用前端语言的解释器对用户代码进行解析,然后利用TF框架的算子分发功能,使得算子立即执行并向前端返回计算结果。当模型接收输入数据后,TF开始动态生成图拓扑结构,添加输入节点并将数据传输给后续节点。如果动态图中含有条件控制逻辑,会立即计算逻辑判断结果并确定后续数据流向,因此动态图完整的拓扑结构在执行前是未知的。另外,当模型根据新的batch训练时,原有的图结构则失效,必须根据输入和控制条件重新生成图结构。
综上所述,动态图生成过程可用下图简要概括:

为了方便大家深入理解动/静态图原理及异同点,梳理相关信息如下表:
| 静态图 | 动态图 | |
|---|---|---|
| 即时获取中间结果 | 否 | 是 |
| 代码调试难度 | 难 | 易 |
| 控制流实现方式 | TF特定语法 | 可采用前端语言语法 |
| 性能 | 多种优化策略,性能好 | 优化受限,性能差 |
| 内存占用 | 内存占用少 | 内存占用多 |
| 部署情况 | 可直接部署 | 不可直接部署 |
tf.Session代表用户程序和C++运行时之间的连接。一个Session类对象session可以用来访问本机计算设备,也可访问TF分布式运行时环境中的远程设备。session也能缓存tf.Graph信息,使得相同计算逻辑的多次执行得以高效实现。
tf.Session的构造方法定义如下:
def __init__(self, target='', graph=None, config=None): """Creates a new TensorFlow session. If no `graph` argument is specified when constructing the session, the default graph will be launched in the session. If you are using more than one graph (created with `tf.Graph()` in the same process, you will have to use different sessions for each graph, but each graph can be used in multiple sessions. In this case, it is often clearer to pass the graph to be launched explicitly to the session constructor. Args: target: (Optional.) The execution engine to connect to. Defaults to using an in-process engine. See @{$distributed$Distributed TensorFlow} for more examples. graph: (Optional.) The `Graph` to be launched (described above). config: (Optional.) A [`ConfigProto`](https://www.tensorflow.org/code/tensorflow/core/protobuf/config.proto) protocol buffer with configuration options for the session. """ super(Session, self).__init__(target, graph, config=config) # NOTE(mrry): Create these on first `__enter__` to avoid a reference cycle. self._default_graph_context_manager = None self._default_session_context_manager = None复制
我们来看一下__init__()方法的三个参数:
tf.Session.run()实际是调用tf.BaseSession.run()方法,其函数签名如下:
def run(self, fetches, feed_dict=None, options=None, run_metadata=None):复制
run()方法的参数说明如下:
当Session指定fetches后,根据要获取的结果决定tf.Graph实际执行的subgraph(并非整个tf.Graph都要执行)。执行静态图还有三个要点:
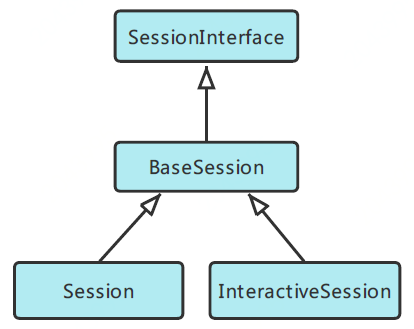
首先我们看一下和用户直接打交道的前端Session,具体分为普通Session和交互式InteractiveSession。前者全称为tf.Session,需要在启动之前先构建完整的计算图;后者全称为tf.InteractiveSession,它是先构建一个session,然后再定义各种操作,适用于shell和IPython等交互式环境。这两个类均继承自BaseSession,这个基类实现了整个生命周期的所有会话逻辑(相关代码在tensorflow/python/client/session.py中)。前端Session类的继承关系如下图:
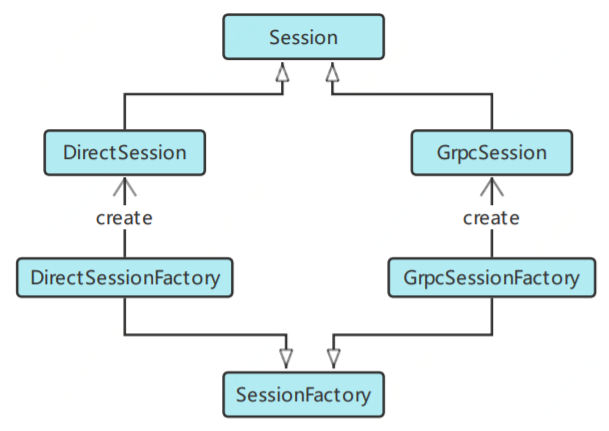
TensorFlow后端会根据前端tf.Session(target='', graph=None, config=None)创建时指定的target来创建不同的后端Session。target是要连接的TF后端执行引擎,默认为空字符串。后端Session的创建采用抽象工厂模式,如果为空字符串,则创建本地DirectionSession;如果是grpc://开头的URL串,则创建分布式GrpcSession。DirectSession只能利用本地设备,将任务调度到本地的CPU/GPU设备上;GrpcSession可利用远程设备,将任务分发到不同机器的CPU/GPU上,然后机器之间通过gRPC进行通信。显而易见,DirectionSession的定义应在core/common_runtime/direction_session.h中;GrpcSession的定义在core/distributed_runtime/rpc/grpc_session.h中。后端Session的类图关系如下所示:
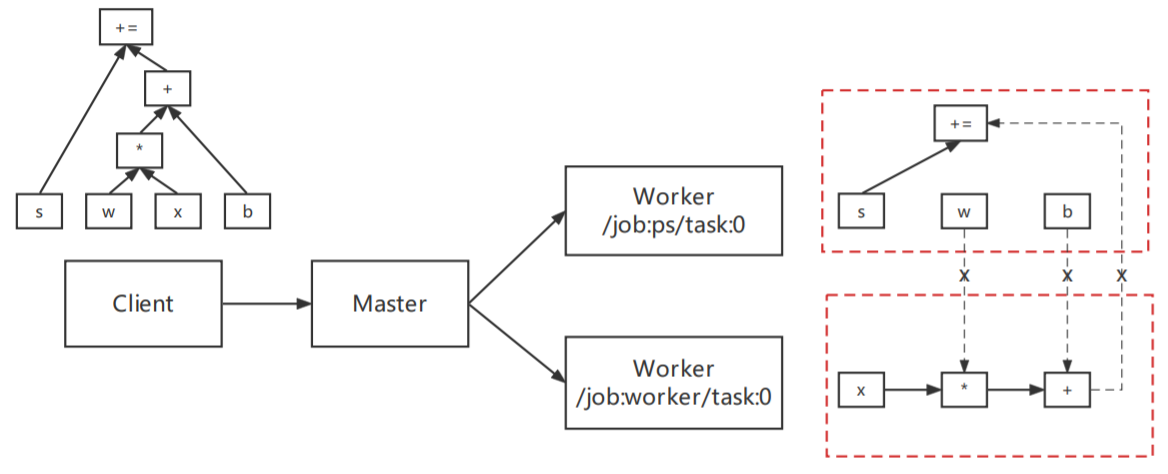
为便于大家理解,我们先给出粗粒度的静态图执行原理如下:
静态图的实际执行过程要比3.1节描述的复杂得多。由于本篇的初衷不是做源码的完整剖析,因此我们仅就Client向Master的处理过程做详细说明,旨在让读者亲身体会一下交互过程的复杂性。
Client创建GrpcSession,控制Client会话的生命周期;Master运行时被MasterSession控制。GrpcSession通过抽象工厂模式得到,首先得到工厂类GrpcSessionFactory的对象,并用SessionFactory句柄factory存储。然后通过factory的多态方法生成GrpcSession,如果target为grpc://的话。Master本质上是一个Server,每个Server均有一个MasterService和一个WorkerService。
Client通过GrpcSession调用Master节点的MasterService,这个过程需借助MasterInterface才可完成。MasterInterface用来和MasterService进行通信,它有两种不同的场景实现:
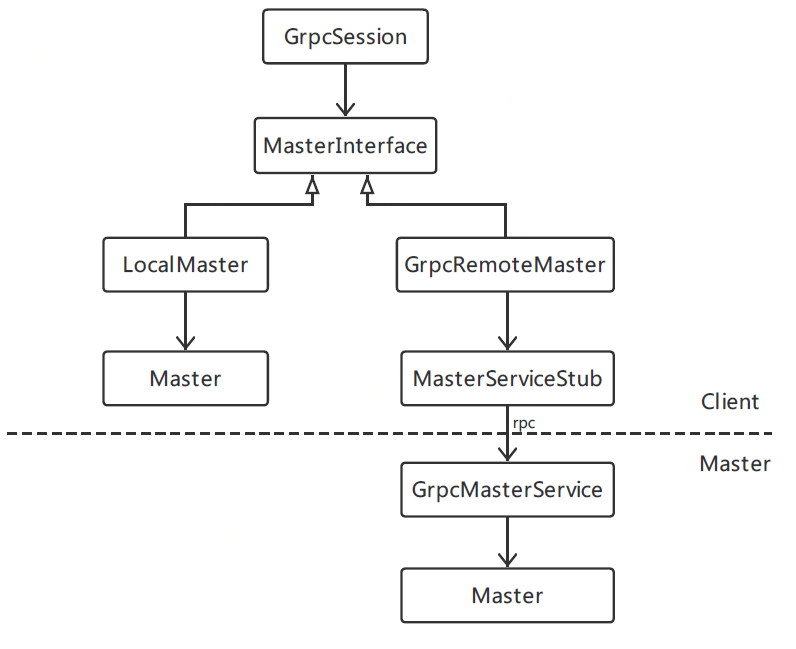
如果读者想对上述过程做更为深入的了解,可以参考几个关键类的源码:
其实Client到Master的处理过程还涉及MasterSession的创建,以及GrpcSession与MasterSession的交互与标识问题。篇幅所限,不展开了。
作为Dive into TensorFlow系列第一讲,本文由浅入深、系统讲解了静态图及其运行原理,以及支撑这些功能的架构设计与部分源码解析。回到文章开头提到的用户读懂全文能有什么收益?(尝试提几点)
1.Graphs and Sessions: https://github.com/tensorflow/docs/blob/master/site/en/r1/guide/graphs.md
2.《机器学习系统:设计与实现》: https://openmlsys.github.io/chapter_computational_graph/index.html
3.前后端连接的桥梁Session: https://www.likecs.com/show-306440850.html
4.TensorFlow v1.15.5源码: https://github.com/tensorflow/tensorflow/tree/v1.15.5/tensorflow/core/graph
5.TensorFlow Architecture: https://github.com/tensorflow/docs/blob/master/site/en/r1/guide/extend/architecture.md
6.TensorFlow分布式环境Session: https://www.cnblogs.com/rossiXYZ/p/16065124.html