作者:京东物流 陈昌浩
Redis 是当前最流行的 NoSQL数据库。Redis主要用来做缓存使用,在提高数据查询效率、保护数据库等方面起到了关键性的作用,很大程度上提高系统的性能。当然在使用过程中,也会出现一些异常情景,导致Redis失去缓存作用。
异常主要有 缓存雪崩 缓存穿透 缓存击穿。
缓存雪崩是指大量请求在缓存中没有查到数据,直接访问数据库,导致数据库压力增大,最终导致数据库崩溃,从而波及整个系统不可用,好像雪崩一样。
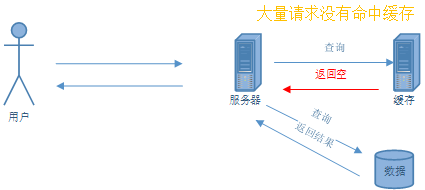
1.缓存服务不可用
redis的部署方式主要有单机、主从、哨兵和 cluster模式。
单机
只有一台机器,所有数据都存在这台机器上,当机器出现异常时,redis将失效,可能会导致redis缓存雪崩。
主从
主从其实就是一台机器做主,一个或多个机器做从,从节点从主节点复制数据,可以实现读写分离,主节点做写,从节点做读。
优点:当某个从节点异常时,不影响使用。
缺点:当主节点异常时,服务将不可用。
哨兵
哨兵模式也是一种主从,只不过增加了哨兵的功能,用于监控主节点的状态,当主节点宕机之后会进行投票在从节点中重新选出主节点。
优点:高可用,当主节点异常时,自动在从节点当中选择一个主节点。
缺点:只有一个主节点,当数据比较多时,主节点压力会很大。
cluster模式
集群采用了多主多从,按照一定的规则进行分片,将数据分别存储,一定程度上解决了哨兵模式下单机存储有限的问题。
优点:高可用,配置了多主多从,可以使数据分区,去中心化,减小了单台机子的负担.
缺点:机器资源使用比较多,配置复杂。
小结
从高可用得角度考虑,使用哨兵模式和cluster模式可以防止因为redis不可用导致的缓存雪崩问题。
2.大量KEY同时失效
可以通过设置永不失效、设置不同失效时间、使用二级缓存和定时更新缓存失效时间
设置永不失效
如果所有的key都设置不失效,不就不会出现因为KEY失效导致的缓存雪崩问题了。redis设置key永远有效的命令如下:
PERSIST key
缺点:会导致redis的空间资源需求变大。
设置随机失效时间
如果key的失效时间不相同,就不会在同一时刻失效,这样就不会出现大量访问数据库的情况。
redis设置key有效时间命令如下:
Expire key
示例代码如下,通过RedisClient实现
/**
* 随机设置小于30分钟的失效时间
* @param redisKey
* @param value
*/
private void setRandomTimeForReidsKey(String redisKey,String value){
//随机函数
Random rand = new Random();
//随机获取30分钟内(30*60)的随机数
int times = rand.nextInt(1800);
//设置缓存时间(缓存的key,缓存的值,失效时间:单位秒)
redisClient.setNxEx(redisKey,value,times);
}
复制public static void main(String[] args) {
CacheTest test = new CacheTest();
//从1级缓存中获取数据
String value = test.queryByOneCacheKey("key");
//如果1级缓存中没有数据,再二级缓存中查找
if(StringUtils.isBlank(value)){
value = test.queryBySecondCacheKey("key");
//如果二级缓存中没有,从数据库中查找
if(StringUtils.isBlank(value)){
value =test.getFromDb();
//如果数据库中也没有,就返回空
if(StringUtils.isBlank(value)){
System.out.println("数据不存在!");
}else{
//二级缓存中保存数据
test.secondCacheSave("key",value);
//一级缓存中保存数据
test.oneCacheSave("key",value);
System.out.println("数据库中返回数据!");
}
}else{
//一级缓存中保存数据
test.oneCacheSave("key",value);
System.out.println("二级缓存中返回数据!");
}
}else {
System.out.println("一级缓存中返回数据!");
}
}
复制public class CacheRunnable implements Runnable {
private ClusterRedisClientAdapter redisClient;
/**
* 要更新的key
*/
public String key;
public CacheRunnable(String key){
this.key =key;
}
@Override
public void run() {
//更细缓存时间
redisClient.expire(this.getKey(),1800);
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
}
public static void main(String[] args) {
CacheTest test = new CacheTest();
//从缓存中获取数据
String value = test.getFromCache("key");
if(StringUtils.isBlank(value)){
//从数据库中获取数据
value = test.getFromDb("key");
//将数据放在缓存中
test.oneCacheSave("key",value);
//返回数据
System.out.println("返回数据");
}else{
//异步任务更新缓存
CacheRunnable runnable = new CacheRunnable("key");
runnable.run();
//返回数据
System.out.println("返回数据");
}
}
复制3.小结
上面从服务不可用和key大面积失效两个方面,列举了几种解决方案,上面的代码只是提供一些思路,具体实施还要考虑到现实情况。当然也有其他的解决方案,我这里举例是比较常用的。毕竟现实情况,千变万化,没有最好的方案,只有最适用的方案。
缓存穿透是指当用户在查询一条数据的时候,而此时数据库和缓存却没有关于这条数据的任何记录,而这条数据在缓存中没找到就会向数据库请求获取数据。用户拿不到数据时,就会一直发请求,查询数据库,这样会对数据库的访问造成很大的压力。
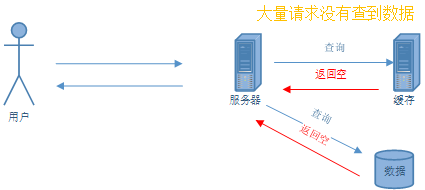
1.非法调用
可以通过缓存空值或过滤器来解决非法调用引起的缓存穿透问题。
private String queryMessager(String key){
//从缓存中获取数据
String message = getFromCache(key);
//如果缓存中没有 从数据库中查找
if(StringUtils.isBlank(message)){
message = getFromDb(key);
//如果数据库中也没有数据 就设置短时间的缓存
if(StringUtils.isBlank(message)){
//设置缓存时间(缓存的key,缓存的值,失效时间:单位秒)
redisClient.setNxEx(key,null,60);
}else{
redisClient.setNxEx(key,message,1800);
}
}
return message;
}
复制缺点:大量的空缓存导致资源的浪费,也有可能导致缓存和数据库中的数据不一致。
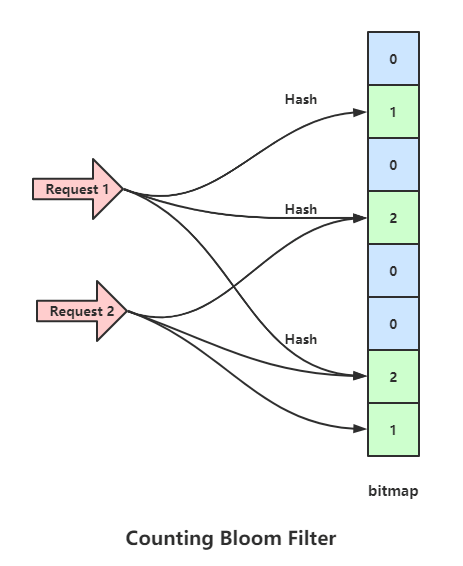
布隆过滤器的实现原理是一个超大的位数组和几个哈希函数。
假设哈希函数的个数为 3。首先将位数组进行初始化,初始化状态的维数组的每个位都设置位 0。如果一次数据请求的结果为空,就将key依次通过 3 个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为 1。当数据请求再次发过来时,用同样的方法将 key 通过哈希映射到位数组上的 3 个点。如果 3 个点中任意一个点不为 1,则可以判断key不为空。反之,如果 3 个点都为 1,则该KEY一定为空。
缺点:
可能出现误判,例如 A 经过哈希函数 存到 1、3和5位置。B经过哈希函数存到 3、5和7位置。C经过哈希函数得到位置 3、5和7位置。由于3、5和7都有值,导致判断A也在数组中。这种情况随着数据的增多,几率也变大。
布隆过滤器没法删除数据。
布隆过滤器增强版
增强版是将布隆过滤器的bitmap更换成数组,当数组某位置被映射一次时就+1,当删除时就-1,这样就避免了普通布隆过滤器删除数据后需要重新计算其余数据包Hash的问题,但是依旧没法避免误判。
布谷鸟过滤器
但是如果这两个位置都满了,它就不得不「鸠占鹊巢」,随机踢走一个,然后自己霸占了这个位置。不同于布谷鸟的是,布谷鸟哈希算法会帮这些受害者(被挤走的蛋)寻找其它的窝。因为每一个元素都可以放在两个位置,只要任意一个有空位置,就可以塞进去。所以这个伤心的被挤走的蛋会看看自己的另一个位置有没有空,如果空了,自己挪过去也就皆大欢喜了。但是如果这个位置也被别人占了呢?好,那么它会再来一次「鸠占鹊巢」,将受害者的角色转嫁给别人。然后这个新的受害者还会重复这个过程直到所有的蛋都找到了自己的巢为止。
缺点:
如果数组太拥挤了,连续踢来踢去几百次还没有停下来,这时候会严重影响插入效率。这时候布谷鸟哈希会设置一个阈值,当连续占巢行为超出了某个阈值,就认为这个数组已经几乎满了。这时候就需要对它进行扩容,重新放置所有元素。
2.小结
以上方法虽然都有缺点,但是可以有效的防止因为大量空数据查询导致的缓存穿透问题,除了系统上的优化,还要加强对系统的监控,发下异常调用时,及时加入黑名单。降低异常调用对系统的影响。
key中对应数据存在,当key中对应的数据在缓存中过期,而此时又有大量请求访问该数据,缓存中过期了,请求会直接访问数据库并回设到缓存中,高并发访问数据库会导致数据库崩溃。redis的高QPS特性,可以很好的解决查数据库很慢的问题。但是如果我们系统的并发很高,在某个时间节点,突然缓存失效,这时候有大量的请求打过来,那么由于redis没有缓存数据,这时候我们的请求会全部去查一遍数据库,这时候我们的数据库服务会面临非常大的风险,要么连接被占满,要么其他业务不可用,这种情况就是redis的缓存击穿。
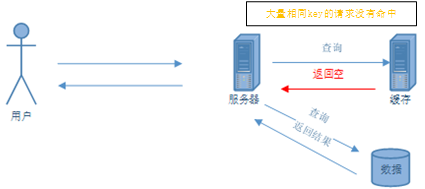
热点KEY失效的同时,大量相同KEY请求同时访问。
1.热点key失效
设置永不失效
如果所有的key都设置不失效,不就不会出现因为KEY失效导致的缓存雪崩问题了。redis设置key永远有效的命令如下:
PERSIST key
缺点:会导致redis的空间资源需求变大。
设置随机失效时间
如果key的失效时间不相同,就不会在同一时刻失效,这样就不会出现大量访问数据库的情况。
redis设置key有效时间命令如下:
Expire key
示例代码如下,通过RedisClient实现
/**
* 随机设置小于30分钟的失效时间
* @param redisKey
* @param value
*/
private void setRandomTimeForReidsKey(String redisKey,String value){
//随机函数
Random rand = new Random();
//随机获取30分钟内(30*60)的随机数
int times = rand.nextInt(1800);
//设置缓存时间(缓存的key,缓存的值,失效时间:单位秒)
redisClient.setNxEx(redisKey,value,times);
}
复制public static void main(String[] args) {
CacheTest test = new CacheTest();
//从1级缓存中获取数据
String value = test.queryByOneCacheKey("key");
//如果1级缓存中没有数据,再二级缓存中查找
if(StringUtils.isBlank(value)){
value = test.queryBySecondCacheKey("key");
//如果二级缓存中没有,从数据库中查找
if(StringUtils.isBlank(value)){
value =test.getFromDb();
//如果数据库中也没有,就返回空
if(StringUtils.isBlank(value)){
System.out.println("数据不存在!");
}else{
//二级缓存中保存数据
test.secondCacheSave("key",value);
//一级缓存中保存数据
test.oneCacheSave("key",value);
System.out.println("数据库中返回数据!");
}
}else{
//一级缓存中保存数据
test.oneCacheSave("key",value);
System.out.println("二级缓存中返回数据!");
}
}else {
System.out.println("一级缓存中返回数据!");
}
}
复制public class CacheRunnable implements Runnable {
private ClusterRedisClientAdapter redisClient;
/**
* 要更新的key
*/
public String key;
public CacheRunnable(String key){
this.key =key;
}
@Override
public void run() {
//更细缓存时间
redisClient.expire(this.getKey(),1800);
}
public String getKey() {
return key;
}
public void setKey(String key) {
this.key = key;
}
}
public static void main(String[] args) {
CacheTest test = new CacheTest();
//从缓存中获取数据
String value = test.getFromCache("key");
if(StringUtils.isBlank(value)){
//从数据库中获取数据
value = test.getFromDb("key");
//将数据放在缓存中
test.oneCacheSave("key",value);
//返回数据
System.out.println("返回数据");
}else{
//异步任务更新缓存
CacheRunnable runnable = new CacheRunnable("key");
runnable.run();
//返回数据
System.out.println("返回数据");
}
}
复制/**
* 根据key获取数据
* @param key
* @return
* @throws InterruptedException
*/
public String queryForMessage(String key) throws InterruptedException {
//初始化返回结果
String result = StringUtils.EMPTY;
//从缓存中获取数据
result = queryByOneCacheKey(key);
//如果缓存中有数据,直接返回
if(StringUtils.isNotBlank(result)){
return result;
}else{
//获取分布式锁
if(lockByBusiness(key)){
//从数据库中获取数据
result = getFromDb(key);
//如果数据库中有数据,就加在缓存中
if(StringUtils.isNotBlank(result)){
oneCacheSave(key,result);
}
}else {
//如果没有获取到分布式锁,睡眠一下,再接着查询数据
Thread.sleep(500);
return queryForMessage(key);
}
}
return result;
}
复制2.小结
除了以上解决方法,还可以预先设置热门数据,通过一些监控方法,及时收集热点数据,将数据预先保存在缓存中。
Redis缓存在互联网中至关重要,可以很大的提升系统效率。 本文介绍的缓存异常以及解决思路有可能不够全面,但也提供相应的解决思路和代码大体实现,希望可以为大家提供一些遇到缓存问题时的解决思路。如果有不足的地方,也请帮忙指出,大家共同进步。
web 应用服务器 CPU 消耗打到 99%,排查后发现是因为 ReDoS 导致了服务器发生了资源被耗尽、访问系统缓慢的问题。本片文章主要介绍ReDos 攻击的原理、常见场景以及防范和解决方案。