本文除特殊说明外,所指的都是fate 1.9版本。
fate资料存在着多处版本功能与发布的文档不匹配的情况,各个模块都有独立的文档,功能又有关联,坑比较多,首先要理清楚各概念、模块之间的关系。
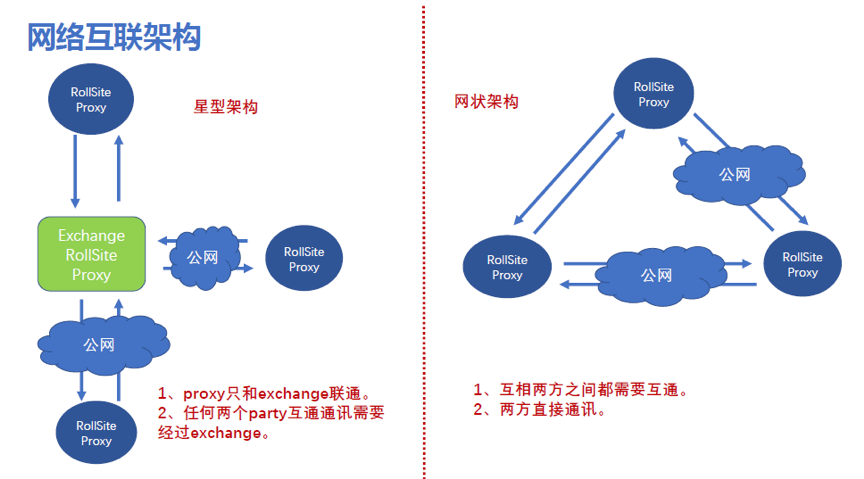
1. 概念解释:
RollSite是一个grpc通信组件,是eggroll引擎中的一个模块,相当于我们的grpc通信网关。
Exchange是RollSite中的一个功能,用于维护各方网关地址,并转发消息。参考《FATE exchange部署指南》
2. 对比解读:
l 网状架构相当于我们的一体化版本模式,但没有dop平台来维护网关,每方需要在配置文件里维护其他参与方的网关地址。
l 星型架构的好处是只在Exchange方维护所有参与方的网关地址,前提是需要信任Exchange,并且流量全部都需要从Exchange方中转,相当于我们的中心化版本。但不支持证书。
3. Exchange配置
在Exchange上配置路由表:

在各party方配置默认路由指向exchange,不需要再配置每个party的地址。
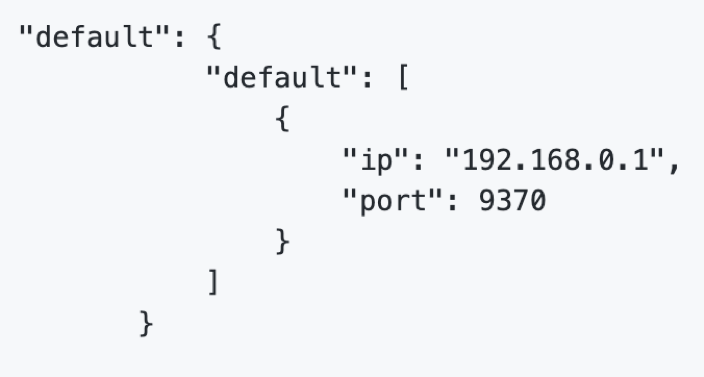
FATE支持eggroll和spark两种计算引擎,搭配不同的通信组件,共五种组合,不同的通信模块不能兼容。
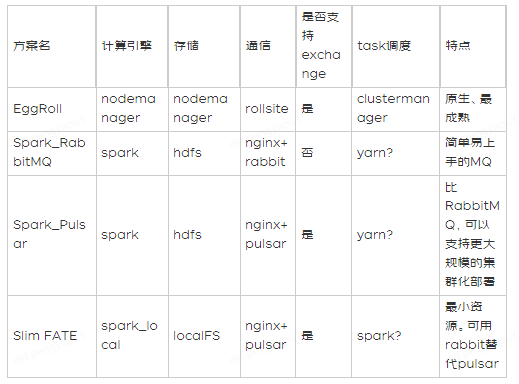
区别:
l RabbitMQ是一个简单易上手的MQ
l Pulsar相比RabbitMQ,可以支持更大规模的集群化部署,也支持exchange模式的网络结构。
l Slim FATE相比其他模式,最大化减少集群所需的组件,可以使用在小规模联邦学习计算,IOT设备等情况。
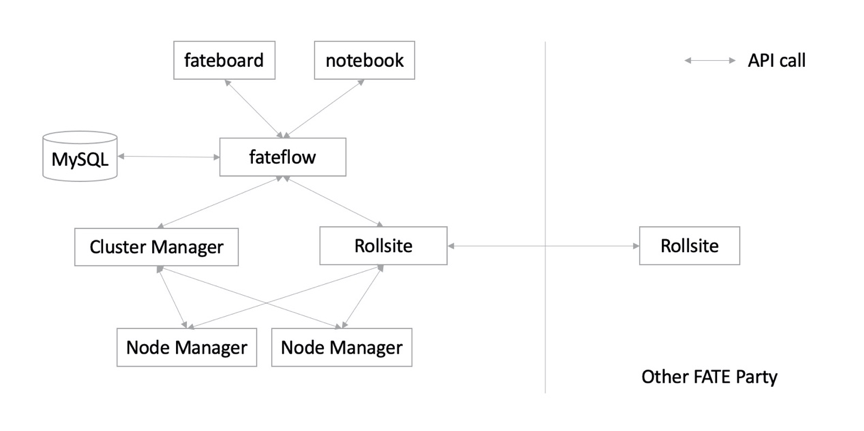
Eggroll是FATE原生支持的计算存储引擎,包括以下三个组件:
l rollsite负责数据传输,以前的版本里叫 Proxy+Federation
l nodemanager负责存储和计算
l clustermanager负责管理nodemanager
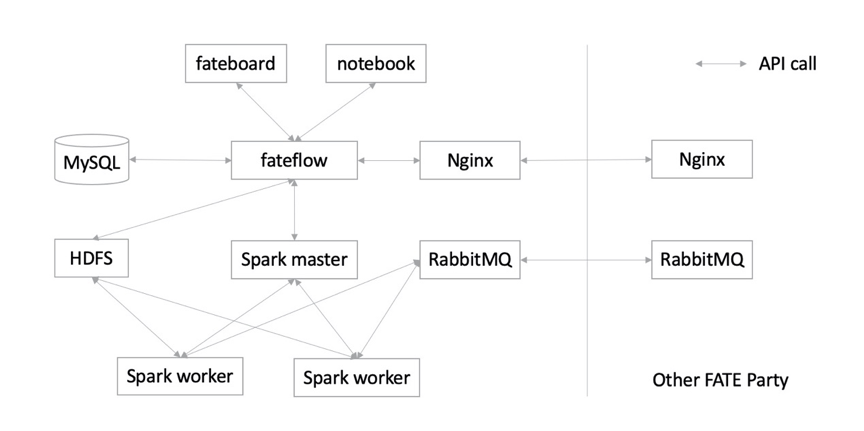
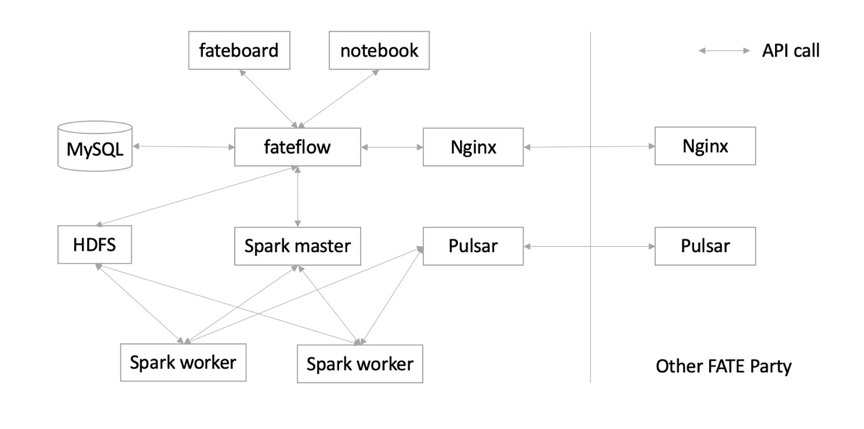
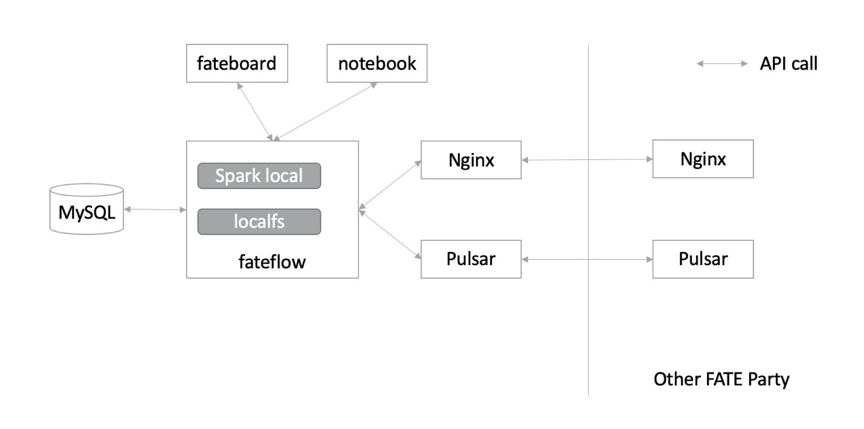
支持rabbitMQ替换pulsar
所有的fate项目都在这个叫FederateAI社区的URL下:https://github.com/FederatedAI
主项目:FATE是一个汇总的文档和超链集合, 学习入口,在线文档
关联项目:
•KubeFATE docker和k8s的部署
•AnsibleFATE 相当于我们的图形化部署版的底层脚本 学习入口
•FATE-Flow 联合学习任务流水线管理模块,注册、管理和调度中心。
•EggRoll 第一代fate的计算引擎
•FATE-Board 联合学习过程可视化模块,目前只能查看一些记录
•FATE-Serving 在线联合预测,学习入口
•FATE-Cloud 联邦学习云服务,类似于我们的dop平台,管理功能。
•FedVision 联邦学习支持的可视化对象检测平台
•FATE-Builder fate编译工具
•FedLCM 新增的项目:创建 FATE 联邦并部署FATE实例。目前仅支持部署以Spark和Pulsar作为基础引擎,并使用Exchange实现互相连接的
FATE Flow是调度系统,根据用户提交的作业DSL,调度算法组件执行。
服务能力:
· 数据接入
· 任务组件注册中心
· 联合作业&任务调度
· 多方资源协调
· 数据流动追踪
· 作业实时监测
· 联合模型注册中心
· 多方合作权限管理
· 系统高可用
· CLI、REST API、Python API
旧版,图比较立体
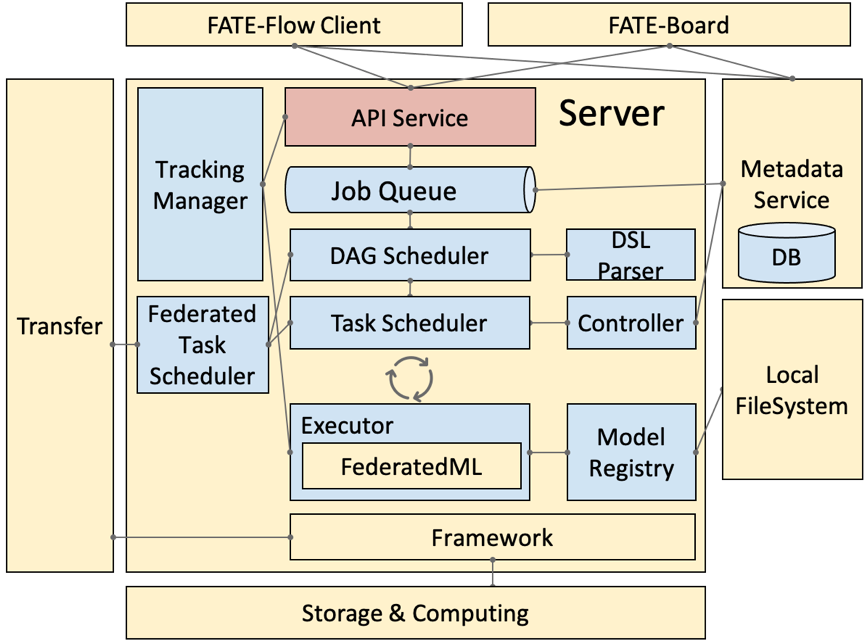
· DSL Parser:是调度的核心,通过 DSL parser 可以拿到上下游关系、依赖等。
· Job Scheduler:是 DAG 层面的调度,把 DAG 作为一个 Job,把 DAG 里面的节点 run 起来,就称为一个 task。
· Federated Task Scheduler:最小调度粒度就是 task,需要调度多方运行同一个组件但参数算法不同的 task,结束后,继续调度下一个组件,这里就会涉及到协同调度的问题。
· Job Controller:联邦任务控制器
· Executor:联邦任务执行节点,支持不同的 Operator 容器,现在支持 Python 和 Script 的 Operator。Executor,在我们目前的应用中拉起 FederatedML 定义的一些组件,如 data io 数据输入输出,特征选择等模块,每次调起一个组件去 run,然后,这些组件会调用基础架构的 API,如 Storage 和 Federation Service ( API 的抽象 ) ,再经过 Proxy 就可以和对端的 FATE-Flow 进行协同调度。
· Tracking Manager:任务输入输出的实时追踪,包括每个 task 输出的 data 和 model。
· Model Manager:联邦模型管理器
DataAccess 数据上传,下载,历史记录,参考示例
Job 提交(并运行),停止,查询,更新,配置,列表,task查询
Tracking
Pipeline
Model
Table
客户端命令行实际上是对api的包装调用,可以参考其示例
Python调用api示例
Federatedml模块包括许多常见机器学习算法联邦化实现。所有模块均采用去耦的模块化方法开发,以增强模块的可扩展性。具体来说,我们提供:
1.联邦统计: 包括隐私交集计算,并集计算,皮尔逊系数, PSI等
2.联邦特征工程:包括联邦采样,联邦特征分箱,联邦特征选择等。
3.联邦机器学习算法:包括横向和纵向的联邦LR, GBDT, DNN,迁移学习等
4.模型评估:提供对二分类,多分类,回归评估,聚类评估,联邦和单边对比评估
5.安全协议:提供了多种安全协议,以进行更安全的多方交互计算。

Figure 1: Federated Machine Learning Framework
可开发在fate框架下运行的算法:指南
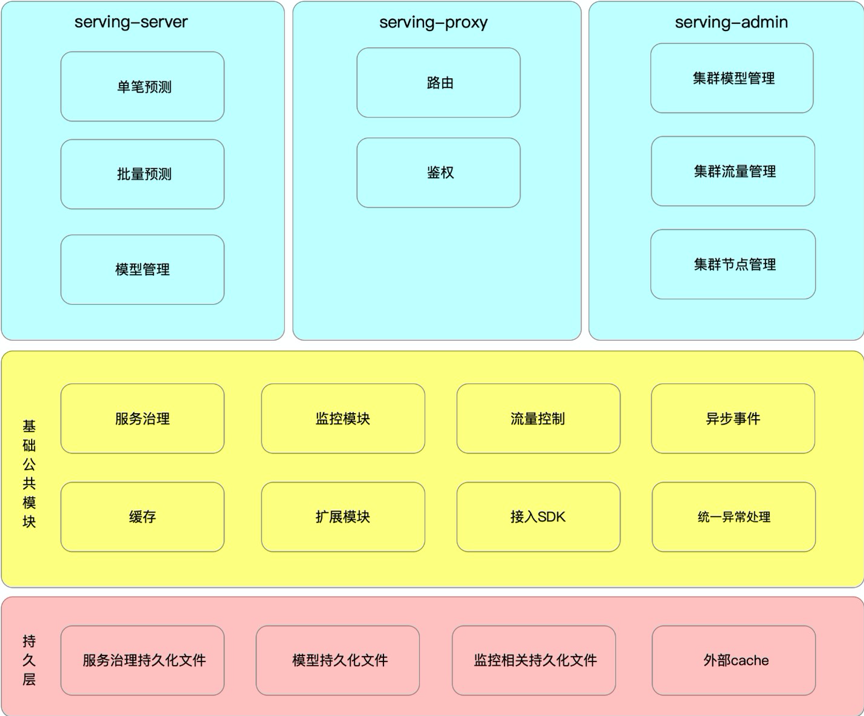
Adatptor:默认的情况使用系统自带的MockAdatptor,仅返回固定数据用于简单测试,实际生产环境中需要使用者需要自行开发并对接自己的业务系统。(这部分可以看看能不能对接咱们自己的在线预测系统。)
l 支持使用rollsite/nginx/fateflow作为多方任务协调通信代理
l rollsite支持fate on eggroll的场景,仅支持grpc协议,支持P2P组网及星型组网模式
l nginx支持所有引擎场景,支持http与grpc协议,默认为http,支持P2P组网及星型组网模式
l fateflow支持所有引擎场景,支持http与grpc协议,默认为http,仅支持P2P组网模式,也即只支持互相配置对端fateflow地址
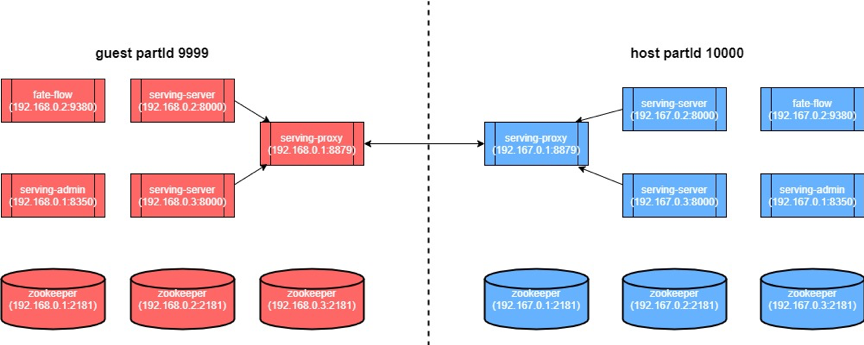

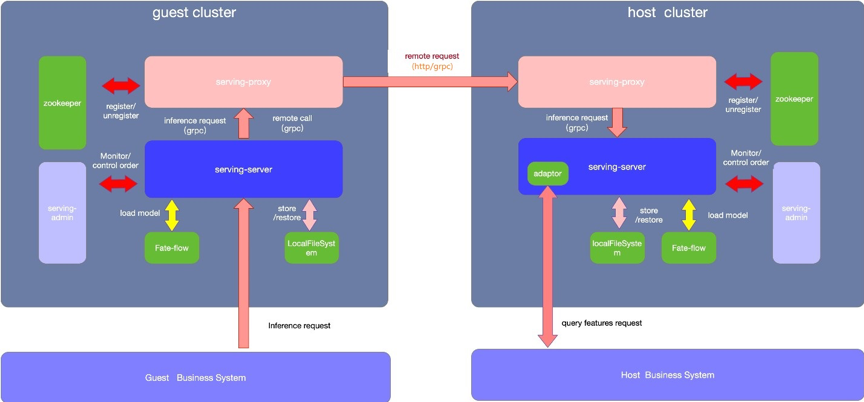
蓝色为guest集群,灰色代表host集群
1. 通过fate flow建模 2. 分别部署guest方 Fate-serving 与host方Fate-serving
3. 分别配置好guest方Fate-flow与guest方Fate-serving、host方Fate-flow 与host方Fate-serving。
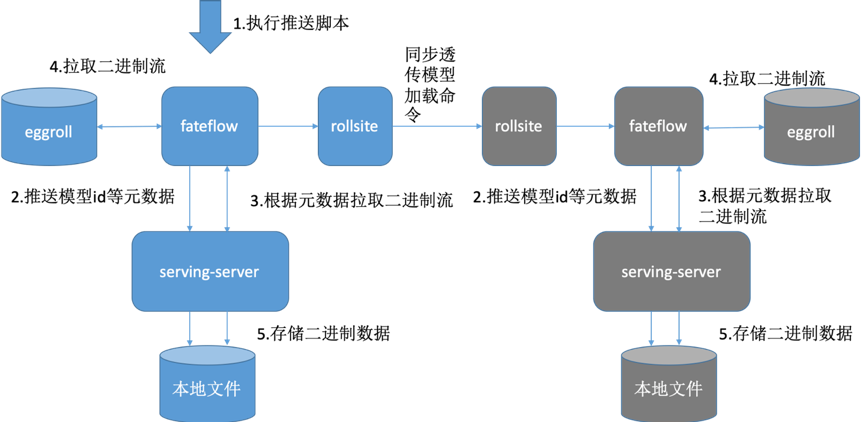
4. Fate-flow推送模型
5. Fate-flow将模型绑定serviceId
6. 以上操作完成后,可以在serving-admin页面上查看模型相关信息(此步操作非必需)。
7. 可以在serving-admin页面上测试调用(此步操作非必需)。
https://fate-serving.readthedocs.io/en/develop/example/nginx/
FATE-Serving 之间的交互可以通过nginx反向代理转发grpc请求,以下几种场景配置如下:
· 场景一:双方不配置TLS,通过nginx四层代理转发
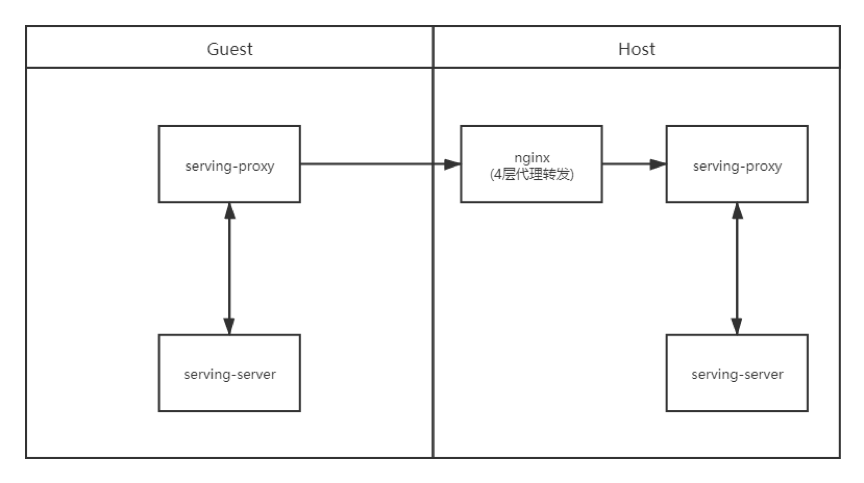
· 场景二:双方配置TLS,通过nginx四层代理转发,双方分别进行证书校验
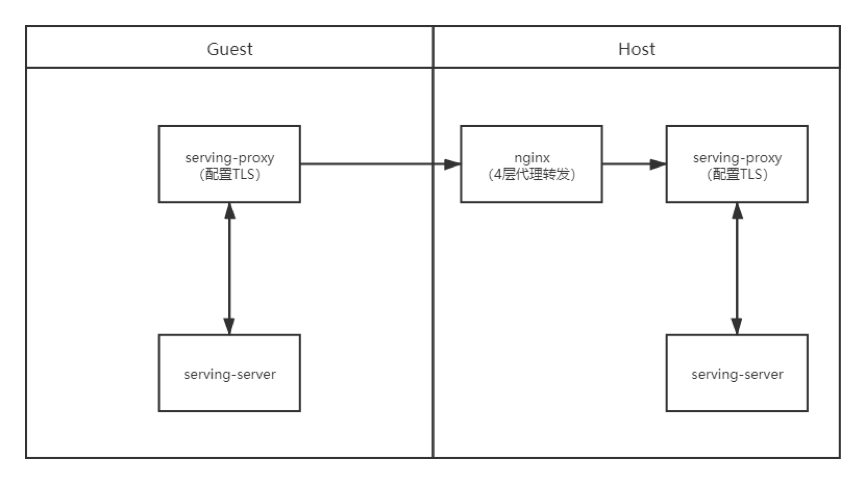
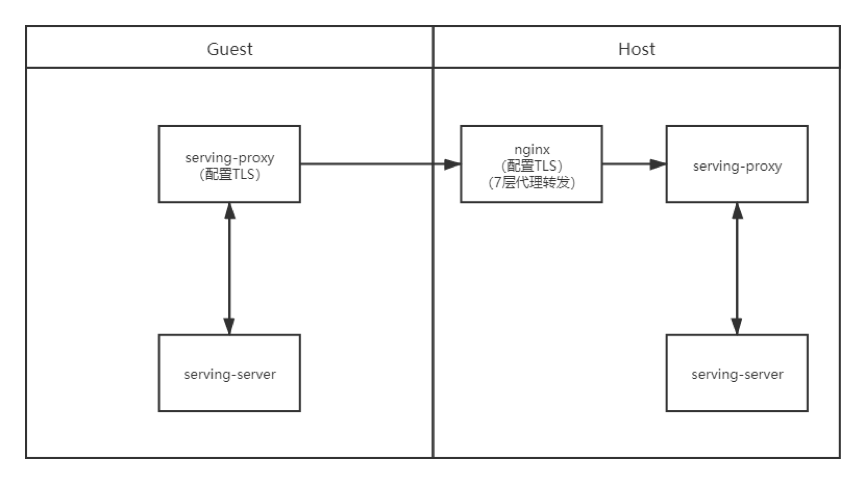
· 场景三:数据使用方配置Client端证书,Nginx配置Server端证书,Host不配置证书,通过nginx七层代理转发,由Client端和nginx进行证书校验
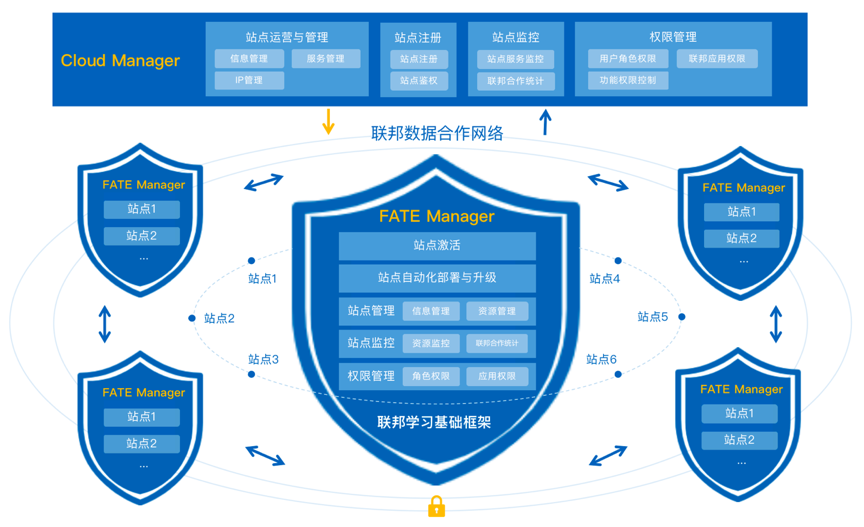
FATE Cloud由负责联邦站点管理的云管理端Cloud Manager和站点客户端管理端FATE Manager组成,提供了联邦站点的注册与管理、集群自动化部署与升级、集群监控、集群权限控制等核心功能。
联邦云管理端(Cloud Manager)
联邦云管理端即联邦数据网络的管理中心,负责统一运营和管理FATE Manager及各站点,监控站点的服务与联邦合作建模,执行联邦各权限控制,保证联邦数据合作网络的正常运作;
联邦站点管理端(FATE Manager)
联邦站点管理端,负责管理和维护各自的联邦站点,为站点提供加入联邦组织、执行站点服务的自动化部署与升级,监控站点的联邦合作与集群服务,并管理站点用户角色与应用权限;
共有4类部署方式,单机的安装模式是只提供了单机的安装文档,也可以研究怎么扩展成集群模式。
| | 单机(不推荐生产用) | 集群(生产推荐) | | 非容器 | AllinOne | ansible | | 容器 | docker compose | k8s |
部署时会要求配置机器对应的角色,只能选host,guest和Exchange,其中host和guest并没有区别,实际运行联邦时还是在job的配置中去配置哪一方是guest,哪一方是host,任务只能在guest方提交。
所有的组件都部署在一台机器上,比较适合开发调试,参考链接。
尝试用ansible部署时遇到了python相关的错误,指导文档也缺少详细的步骤,没有相关错误的说明。
手上没有k8s环境,暂未测试。
容器部署尝试用docker compose方式部署了一对,比较顺利,参考了2篇官方文章,前边的准备步骤和安装过程参考此文,“验证部署”及之后的步骤参考《Docker Compose 部署 FATE》
不同点如下:
下载镜像较慢,如果大批量部署,可以搭建内网镜像服务。
| Role | party-id | OS | IP | | | host | 20001 | Centos7.6 | 11.50.52.81 | 8C64G | | guest | 20002 | Centos7.6 | 11.50.52.62 | 8C64G | | 部署机 | | Centos7.6 | 11.50.52.40 | |
以上内容替代文档中对应的部分内容。
一开始我只部署了一台host,本来打算这2台做一个集群,后来发现文档里没提这种方式,只好先按文档实验一次,于是又部署了guest,这样在guest的配置里已经写好了host的地址,于是手动将配置更新到了host的/data/projects/fate/confs-20001/confs/eggroll/conf/route_table.json
发现不需要重启容器后续步骤也没报错,说明可以动态修改路由信息。
进入容器的时候,容器名包含的平台id需要修改成实际的。
json格式定义说明文档
fateflow/examples/lr/test_hetero_lr_job_conf.json 中不同点,
修改对应的平台id
"initiator": {
"role": "guest",
"party_id": 20002
},
"role": {
"guest": [
20002
],
"host": [
20001
],
"arbiter": [
20001
]
},
复制按文档写资源不够运行不了,需要修改如下
"job_parameters": {
复制 "common": {
复制 "task_parallelism": 1,
复制 "computing_partitions": 1,
复制 "task_cores": 1
复制}复制
},复制
不要修改fateflow/examples/lr/test_hetero_lr_job_dsl.json文件,文档中的配置是旧版本的,修改了就不能执行了,里面的DataIO组件已废弃。
运行测试后可以通过board查看,成功的id:202211031508511267810
http://11.50.52.62:8080/#/history
http://11.50.52.81:8080/#/history
# flow model deploy --model-id arbiter-20001#guest-20002#host-20001#model --model-version 202211031508511267810
复制输出了产生的model_version是202211031811059832400
1. 修改加载模型的配置
# cat > fateflow/examples/model/publish_load_model.json <<EOF
{
"initiator": {
"party_id": "20002",
"role": "guest"
},
"role": {
"guest": [
"20002"
],
"host": [
"20001"
],
"arbiter": [
"20001"
]
},
"job_parameters": {
"model_id": "arbiter-20001#guest-20002#host-20001#model",
"model_version": "202211031811059832400"
}
}
EOF
复制2. 修改绑定模型的配置
# cat > fateflow/examples/model/bind_model_service.json <<EOF
{
"service_id": "test",
"initiator": {
"party_id": "20002",
"role": "guest"
},
"role": {
"guest": ["20002"],
"host": ["20001"],
"arbiter": ["20001"]
},
"job_parameters": {
"work_mode": 1,
"model_id": "arbiter-20001#guest-20002#host-20001#model",
"model_version": "202211031811059832400"
}
}
EOF
复制3. 在线测试
发送以下信息到"GUEST"方的推理服务"{SERVING_SERVICE_IP}:8059/federation/v1/inference"
# curl -X POST -H 'Content-Type: application/json' -i 'http://11.50.52.62:8059/federation/v1/inference' --data '{
"head": {
"serviceId": "test"
},
"body": {
"featureData": {
"x0": 1.88669,
"x1": -1.359293,
"x2": 2.303601,
"x3": 2.00137,
"x4": 1.307686
},
"sendToRemoteFeatureData": {
"phone_num": "122222222"
}
}
}'
复制Jupyter Notebook是web界面IDE。已集成在fate-client容器中。
本文旨在从宏观的角度分析FATE的源码分布、总体架构、主要功能及核心流程,尚有许多细节和功能未深入研究,欢迎大家留言,互相学习。