正文
最近在读《数据密集型应用系统设计》,其中谈到了zookeeper对容错共识算法的应用。这让我想到之前参考的zookeeper学习资料中,误将容错共识算法写成了2PC(两阶段提交协议),所以准备以此文对共识算法和2PC做梳理和区分,也希望它能帮助像我一样对这两者有误解的同学。
1. 2PC(两阶段提交协议)
两阶段提交 (two-phase commit) 协议是一种用于实现 跨多个节点的原子事务(分布式事务)提交 的算法。它能确保所有节点提交或所有节点中止,并在某些数据库内部使用,也以 XA事务 的形式在分布式服务中使用。
在 Java EE 中,XA事务使用 JTA(Java Transaction API) 实现。
2PC的实现
2PC包含 准备阶段 和 提交阶段 两个阶段,需要借助 协调者(事务管理器,如阿里巴巴的Seata) 来实现,参与分布式事务的数据库节点为 参与者。当分布式服务中的节点准备提交时,协调者开始 准备阶段:发送一个 准备请求 到每个节点,询问它们是否能够提交,然后协调者会跟踪参与者的响应
- 如果所有参与者都回答"是",表示它们已经准备好提交,那么协调者在 提交阶段 发出 提交请求,分布式事务提交
- 如果任意一个参与者回答"否",则协调者在 提交阶段 中向所有节点发送 中止请求,分布式事务回滚
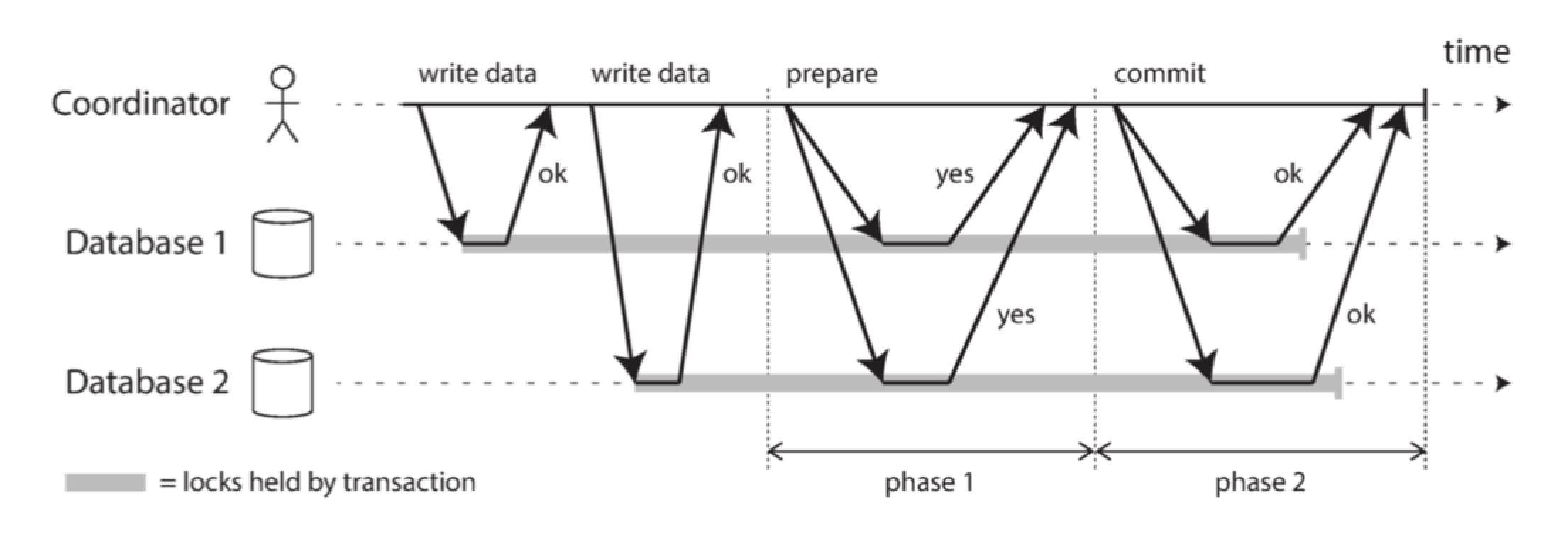
上图是2PC提交成功的情况,我们来详述下过程:
- 当服务启动一个分布式事务时,它会向协调者请求一个事务ID,此事务ID是全局唯一的
- 在每个参与者上启动单节点事务,每个单节点事务会持有这个全局事务 ID。所有的读写都是在这些单节点事务中各自完成的。如果在这个阶段出现任何问题(节点崩溃或请求超时),则协调者或任何参与者都可以中止
- 当应用准备提交时,对应准备阶段:协调者向所有参与者发送一个 准备请求,同样也持有全局事务 ID 。如果任意一个请求失败或超时,则协调者向所有参与者发送针对该事务 ID 的 中止请求,即2PC提交中止的情况
- 参与者收到 准备请求 时,需要确保在任意情况下都可以提交事务。这包括将所有事务数据写入磁盘(出现故障,电源故障,或硬盘空间不足都不能是稍后拒绝提交的理由)以及检查是否存在任何冲突或违反约束。通过向协调者回答 “是”,节点承诺这个事务一定可以不出差错地提交。也就是说:参与者没有实际提交,同时放弃了中止事务的权利
- 当协调者收到所有 准备请求 的答复时,会就 提交或中止事务 作出明确的决定(只有在 所有参与者 投赞成票的情况下才会提交),这里对应提交阶段。协调者必须把这个提交或中止事务的决定 写到磁盘上的事务日志中,记录为 提交点(commit point) 。如果它随后崩溃,能通过提交点进行恢复
- 一旦协调者的决定已经保存在事务日志中,提交或中止请求会发送给所有参与者。如果这个请求失败或超时,协调者 必须永远保持重试,直到成功为止,对于已经做出的决定,协调者不管需要多少次重试它都必须被执行
2PC协议中有两个关键的 不归路 需要注意:
- 一旦协调者做出决定,这一决定是不可撤销的
- 参与者投票 “是” 时,它承诺它稍后肯定能够提交(尽管协调者可能仍然选择放弃),即使参与者在此期间崩溃,事务也需要在其恢复后提交,而且由于参与者投了赞成,它不能在恢复后拒绝提交
这些承诺保证了2PC的 原子性。
协调者失效的情况
如果 协调者失效 并且所有参与者都收到了准备请求并投了是,那么参与者什么都做不了只能等待,而且这种情况 解决方案 是等待协调者恢复或数据库管理员介入操作来提交或回滚事务,当然如果在生产期间这需要承担运维压力。
所以,协调者在向参与者发送提交或中止请求 之前,将其提交或中止决定写入磁盘上的事务日志(提交点)。这样就能在协调者发生崩溃恢复后,通过读取其事务日志来确定所有 存疑事务 的状态,任何在协调者事务日志中没有提交记录的事务都会被终止。因此两阶段提交在第二阶段(提交阶段)存在阻塞等待协调者恢复的情况,所以两阶段提交又被称为 阻塞原子提交协议。
番外:3PC
三阶段提交协议也是应用在分布式事务提交中的算法,它的提出是为了解决两阶段提交协议中存在的阻塞问题。它分为 CanCommit阶段、PreCommit阶段 和 DoCommit阶段,通过引入 参与者超时判断机制 来解决2PC中存在的参与者依赖协调者的提交请求而阻塞导致的资源占用等问题。
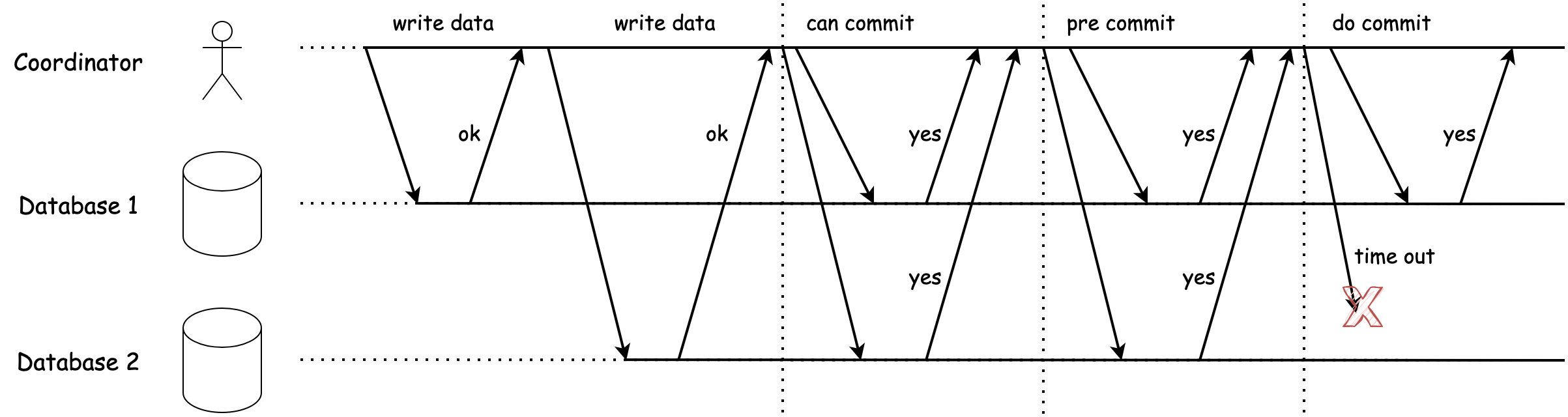
上图为在DoCommit阶段,参与者判断 DoCommit请求 超时情况的流程图,我们详述下它的避免阻塞的流程
- 服务在每个参与者上启动单节点事务,当参与者准备提交时,对应CanCommit阶段,协调者会向所有参与者发送 CanCommit请求,如果任意一个请求失败或超时,则协调者会向所有参与者发送针对该事务的 中止请求,执行事务回滚
- 当协调者收到所有CanCommit请求的答复时,如果全是“是”那么则进入PreCommit阶段,否则发送中止请求,执行事务回滚
- 进入PreCommit阶段后,协调者会向所有参与者发送 PreCommit请求,同样还是如果存在请求失败或超时,会发送中止请求执行事务回滚
- 协调者收到所有PreCommit请求的答复时,如果全是“是”那么则进入DoCommit阶段,否则发送中止请求,执行事务回滚
- 进入DoCommit阶段后,协调者会向所有参与者发送 DoCommit请求,注意这里,如果某个参与者没有收到该请求,它默认认为协调者会发送提交请求,那么便本地执行提交事务,从而避免阻塞
3PC虽然解决了2PC中存在的阻塞问题,但是也引入了新的问题:
- 如果协调者在DoCommit阶段回复的是中止请求,那么超时节点自顾自地提交事务就会发生数据不一致的情况
- 通讯次数增加和实现相对复杂
3PC使原子提交协议变成非阻塞的,但是3PC 假定网络延迟和节点响应时间有限,在大多数具有无限网络延迟和进程暂停的实际系统中,它 并不能保证原子性。非阻塞原子提交需要一个 完美的故障检测器 来以可靠的机制判断一个节点是否已经崩溃,而在无限延迟的网络中,超时并不是一种可靠的故障检测机制,因为即使节点没有崩溃也会因为网络延迟而超时,出于这个原因,2PC仍然被使用,尽管存在协调者故障的问题。
2. 容错共识算法
容错共识算法用于 节点间数据同步,保证各个副本间数据的一致性和集群的高可用。它的通常形式是一个或多个节点可以 提议(propose) 某些值,而共识算法 决定(decides) 采用其中的某个值,并让这些节点就提议达成一致。共识算法必须具备如下性质:
- 一致同意:没有两个节点的决定不同
- 完整性:没有节点决定两次
- 有效性:如果节点决定了
v值,那么v由该节点所提议
- 终止性:由所有未崩溃的节点来最终决定值
终止性实质上是说:容错共识算法不能简单地永远闲坐着等待,而是需要根据大多数节点来达成一项决定,因此终止属性也暗含着 不超过一半的节点崩溃或不可达 的信息。
一致同意和完整性是共识的 核心思想,即所有节点决定了相同的结果并且决定后不能改变主意。
容错共识算法在节点集群内部都以某种形式使用一个领导者,并定义了一个 纪元编号(epoch number) 来确保在每个时代中,领导者都是唯一的。每当现任领导宕机时,节点间会开始一场投票,来选出一个新的领导,每次选举被赋予一个新的纪元编号(全序且单调递增),如果有两个不同时代的领导者之间出现冲突(脑裂问题),那么带有更高纪元编号的领导者说了算。领导者每想要做出的每一个决定,都必须将提议值发送给其他节点,并等待 法定人数 的节点响应并赞成提案。法定人数通常(但不总是)由多数节点组成(一般为过半),只有在没有发现任何带有更高纪元编号的领导者的情况下,一个节点才会投票赞成提议。
容错共识算法的局限性
- 节点在做出决定之前对提议进行投票的过程是一种同步复制
- 共识系统总是需要有 法定人数 的节点存活来保证运转
- 大多数共识算法假定参与投票的节点是固定的集合,这意味着你不能简单的在集群中添加或删除节点
- 共识系统通常依靠 超时 来检测失效的节点,在网络延迟高度变化的环境中,特别是在地理上散布的系统,经常发生一个节点由于暂时的网络问题,错误地认为领导者已经失效。虽然这种错误不会损害安全属性,但频繁的领导者选举会导致糟糕的性能表现,所以共识算法对网络问题比较敏感,而在面对不可靠的网络相关的共识算法研究仍在进展中
3. 2PC和容错共识算法的区别
- 负责解决的问题不同:2PC解决的是分布式事务的一致性,各个节点存储的数据各有不同,目标侧重于保证事务的ACID;容错共识算法解决的是节点副本间数据的一致性和保证集群的高可用,节点间存储的数据完全一致,目标侧重于数据的复制和同步
- 每个提议通过要求的参与节点数不同:2PC要求 所有的参与者表决成功 才通过;容错共识算法只需要 遵循基于法定人数的表决 即可,这也是容错共识算法 终止属性(由所有未崩溃的节点来决定最终值) 的体现
- 集群的高可用保证:2PC的协调者不是通过选举产生的,而是单独部署并人为指定的组件,所以它没有选主机制,不具备高可用性;应用容错共识算法的集群领导者是通过选举机制来指定的,并且在发生异常情况时(主节点宕机)能够选出新的领导者,并进入一致的状态,以此来保证集群的高可用
4. zookeeper中的一次Create请求
一些资料中会提到zookeeper在执行CRUD请求时,使用的是2PC,而 实际上它使用的是容错共识算法。我们以Create请求的流程为例(如下图),来加深和记忆这一知识
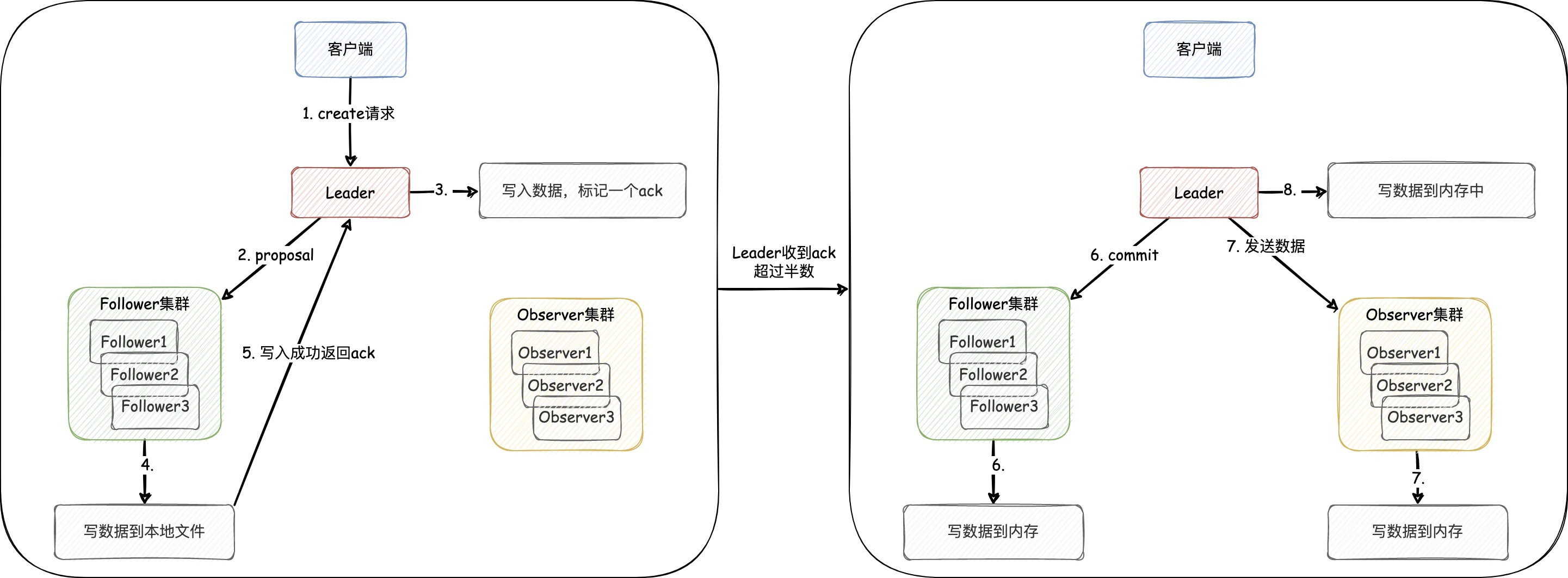
- 客户端发
create 请求到 Leader,即使请求没落到 Leader 上,那么其他节点也会将写请求转发到 Leader
- Leader 会先发一个 提议(proposal)请求给各个 Follower,且自己将数据写到本地文件
- Follower 集群收到 proposal 请求后会将数据写到本地文件,写成功后返回给 Leader 一个 ack回复
- Leader 发现收到 ack 回复的数量为 法定人数(过半,包含当前 Leader 节点)时,则提交一个 commit 请求给各个 Follower 节点。发送 commit 请求就代表该数据在集群内同步情况没有问题,并且 可以对外提供访问 了,此时Leader会把数据写到内存中
- Follower 收到 commit 请求后也会将数据写到各自节点的内存中,同时Leader会将数据发给 Observer集群,通知 Observer集群 将数据写到内存
巨人的肩膀
作者:京东物流 王奕龙
内容来源:京东云开发者社区