竞速榜是大促期间各采销群提供的基于京东实时销售数据的排行榜,同样应对大促流量洪峰场景,通过榜单撬动品牌在京东增加资源投入。竞速榜基于用户配置规则进行实时数据计算,榜单排名在大促期间实时变化,相关排名数据在微博、朋友圈广泛传播,相关计算以及排名的准确性至关重要。
竞速榜的每个榜单配置规则都会有差异,为保障榜单数据计算准确,需要在大促开始前对榜单实时排名数据进行核对,主要验证方案为在第二天取前一天的实时排名数据,另外根据榜单规则配置信息,计算相关的离线数据,进行实时离线数据对比,验证数据的一致性。
单个榜单规则有20+个不同配置项,每个配置都相互独立,需要针对每个规则分别进行数据验证
最初阶段为纯人工对数,分别获取对应竞速榜的实时和离线数据,进行人工比对
1)实时数据:每天23:59 定时读取榜单数据接口,记录对应榜单数据
2)离线数据:根据榜单规则手动编写离线SQL脚本,通过数据查询执行SQL获取榜单排名数据
整个操作过程消耗时间较长,SQL编写需要1小时,单SQL执行0.5小时,为覆盖所有规则,一次需要完成100多个规则的配置和SQL编写以及数据验证,在规则不变情况下,预计需要消耗20人日才能完成一次完整测试, 且脚本编写需要对业务规则深入了解,对测试人员SQL水平要求也较高。
竞速榜主要在大促期间使用,除功能测试覆盖规则外,在大促前还要对业务方配置的规则进行数据验证,确保用户配置规则的计算准确性,以23年618为例,共有5000+榜单规则,如果仍然使用纯人工验证数据的方案,需要900+天,完全不可行。因此实现了半自动化对数方案,和人工对数方案相比,解决了离线SQL的自动化生成,实时数据的自动获取等问题。
具体方案如下:
1、实时数据获取:基于榜单快照功能,自动记录榜单每日快照数据并写入数据库,
2、离线SQL生成和数据计算:
2.1、规则配置入库:通过系统自带的榜单规则导出功能,将榜单规则导出到excel,进而导入到hive表中;同时将榜单规则依赖的其他配置数据也导入到hive
2.2、规则化生成SQL:根据榜单规则配置信息,使用case when的方法,针对不同情况分别生成对应SQL片段,最后人工组合为上述SQL
2.3、合并SQL执行计算任务:将多个组合生成的SQL合并为1个,并配置离线调度任务,通过任务执行分别计算不同榜单的离线数据
2.4、数据推送到对数MySQL:将生成的离线榜单数据推送到实时数据存储的MySQL
3、实时离线数据对比:将实时和离线数据全部推送入数据库后,直接查询数据库,进行数据对比,并对超过阈值的数据进行高亮提示。
通过以上方法,完成了半自动化的实时离线对数,解决了人工对数中最消耗人力的SQL手动编写问题。但是,该方案仍然存在以下问题:
SQL需要人工介入:SQL的生成还存在多次人工操作,中间需要人工对生成的SQL进行调整
规则变化引发SQL调整:在大促前,用户会持续调整规则,这样就导致之前配置好的SQL 和用户规则不一致,进而导致对应榜单对数失败,需要重新生成对应SQL,配置调度任务并重新执行对数操作。
在22年618和双11期间,主要是研发同学使用进行相关SQL调整和数据验证,需要3个开发人员持续3周,整体消耗人力45人日。
为了进一步解放人力消耗,将对数操作从半自动化升级到全自动化,需要实现以下内容
无需人工介入,自动生成SQL,自动执行SQL
执行用的SQL根据规则变化每日自动调整,保证SQL可以自动持续更新
完整的自动化对数方案如下图所示:
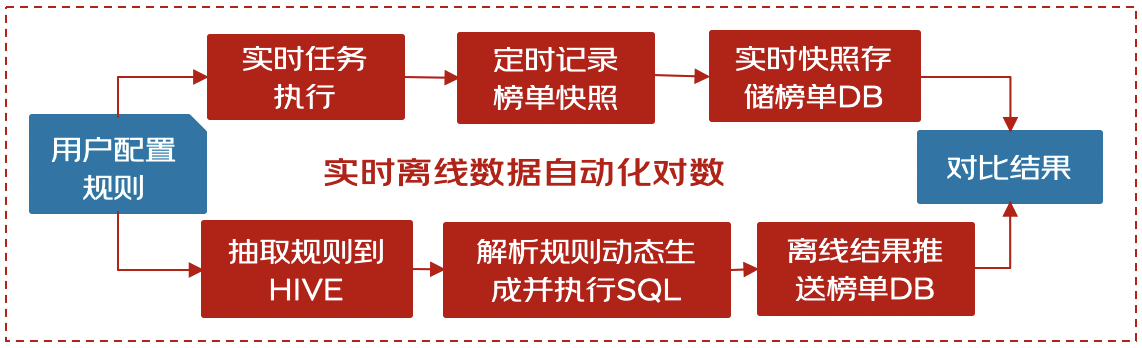
优化点细节:
1. 每天自动更新并存储SQL:榜单规则从手动页面导出变为每天自动抽取规则数据到HIVE中,进而每天自动更新目标SQL并将SQL存储到HIVE表中
2. 自动获取目标SQL并执行:将执行的目标SQL从HIVE中获取到后再执行SQL(使用了hive命令的一些特殊方法,预先获取到SQL再执行)
#HiveTask增加run_shell_cmd_out函数只返回标准流的内容在标准客户端执行如下python脚本
from HiveTask import HiveTask
ht = HiveTask()
ht.run_shell_cmd_out(shellcmd='hive -e "select * from table;"')
复制该方案在23年618期间投入使用,恰逢研发团队交接,新团队毫无对数经验,且有其他业务同步进行,无法投入全量人力。通过全自动化对数,解放了研发人力投入,极大提高了大促备战效率。需要人力主要是测试同学对整个链路的调度任务进行维护性处理。
作者:京东零售 王恒蕾、戚琪
来源:京东云开发者社区