问题发生在快递分拣的流程中,我尽可能将业务背景简化,让大家只关注并发问题本身。
分拣业务针对每个快递包裹都会生成一个任务,我们称它为 task。task 中有两个字段需要关注,一个是分拣中发生的异常(exp_type),另一个是分拣任务的状态(status)。另外,需要关注分拣状态上报接口,通过它来记录分拣过程中的异常和状态变更。
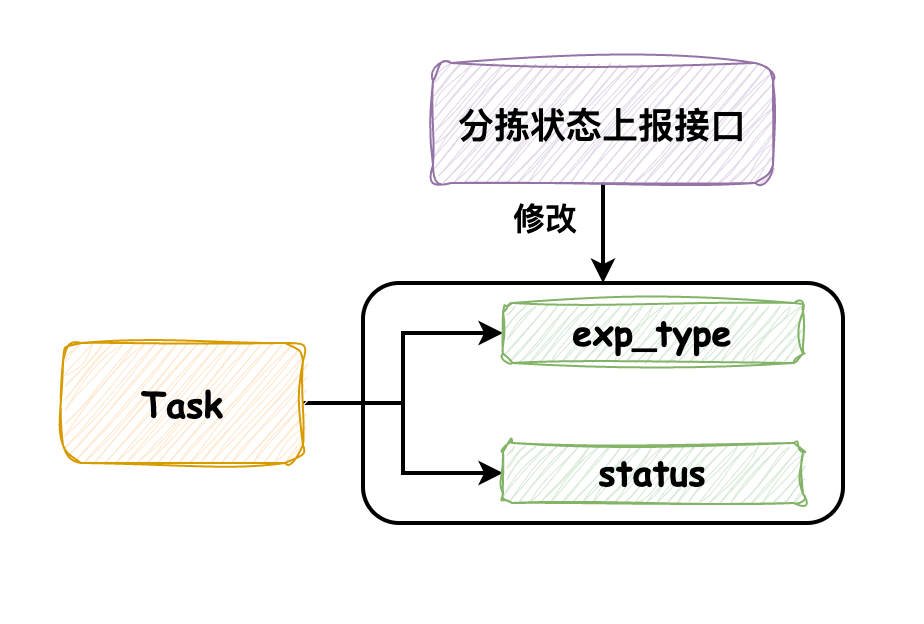
一般情况下,分拣机在分拣异常发生时会及时调用接口上报,在分拣完成时调用接口来标记为完成状态,两次接口调用的时间间隔较长,不会发生并发问题。
但是有一种特殊的分拣机,它不会在异常发生时及时上报,而是在分拣完成时将分拣过程中发生的异常和分拣结果一起上报,那么此时分拣状态上报接口在同一时间内就会有两次调用,这时便发生了预期外的并发问题。
我们先看下分拣状态上报接口的执行流程:
并发问题发生的图示如下:
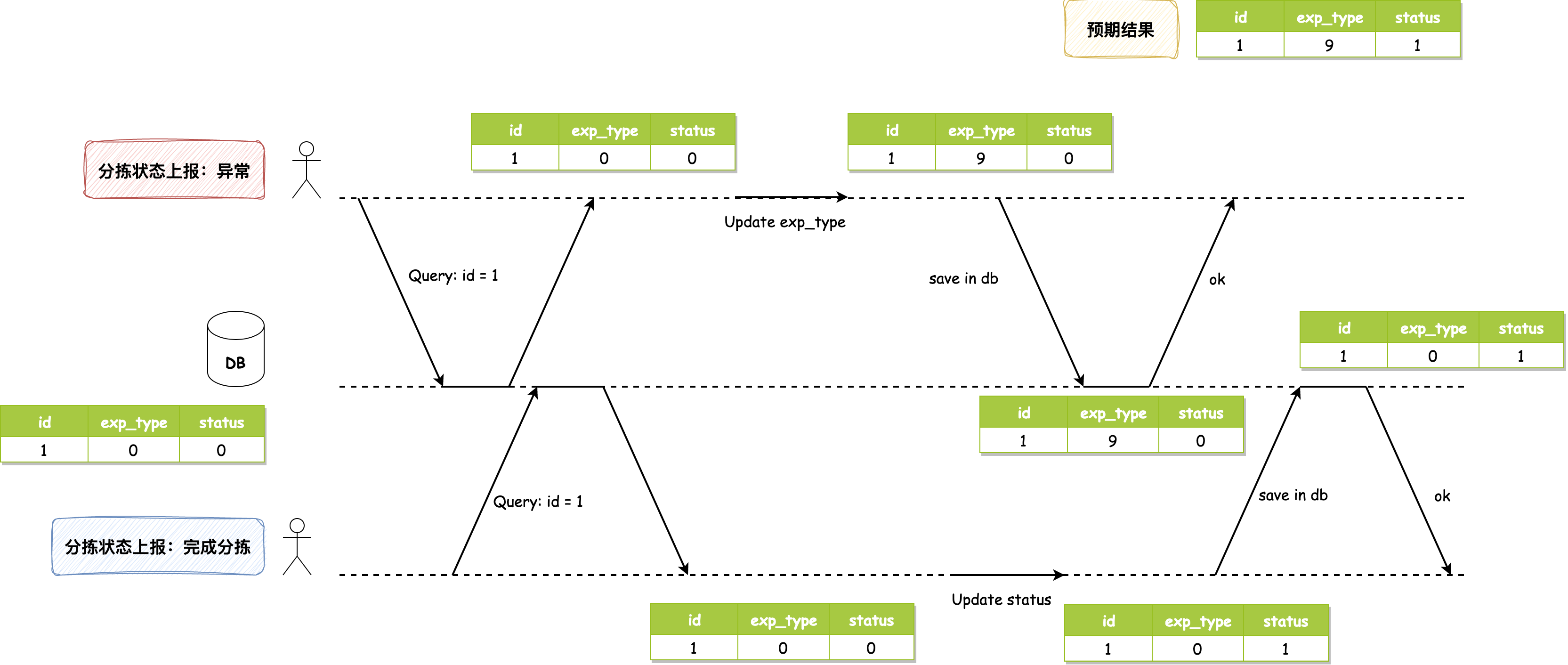
数据库初始值为1, 0, 0,分拣异常和分拣完成几乎同时上报,它们都读取到该值。分拣异常动作将 exp_type 修改为9,写入数据库,此时数据库值为1, 9, 0;分拣完成动作将 status 修改为1,写入数据库,使得数据库最终值为1, 0, 1,它将异常字段的值覆盖掉了。正常情况下,最终值应该为1, 9, 1,分拣完成动作应该读取到分拣异常完成后的值1, 9, 0后再进行修改才对。
发生这个问题的原因很容易就能发现:两个事务同时执行读取-修改-写入序列,其中一个写操作在没有合并另一个写操作变更的情况下,直接覆盖了另一个写操作的结果,所以导致了数据的丢失。
这种问题是比较典型的丢失更新问题,可以通过对数据库读操作加锁或者改变数据库的隔离级别为可串行化使事务串行执行的方式进行避免。下面我会将大家在讨论避免丢失更新问题时提出的方案进行介绍,并尽可能的用代码来表现它们。
我们可以考虑:如果对每条Task数据修改的事务都是在当前事务完成之后才允许后续事务进行修改,使事务串行执行,那么我们就能够避免这种情况。比较直接的实现是通过显式加锁来实现,如下
select exp_type, status
from task
where id = 1
for update;
复制先查询该行数据的事务会获取到该行数据的排他锁,后续针对该数据的所有读写请求都会被阻塞,直到先前事务执行完将锁释放。
这样通过加锁的方式实现了事务的串行执行。但是,在为SQL添加加锁语句时,需要确定是不是为该行数据加锁而不是锁住了整个表,如果是后者,那么可能会造成系统性能严重下降,而且还需要关注有哪些业务场景使用到了该SQL,是否存在长时间执行的只读事务使用,如果存在的话可能会出现因加锁导致延迟和系统性能下降,所以需要谨慎的评估。
此外,可串行化的数据库隔离级别也能保证事务的串行执行,不过它针对的是所有事务。一般情况下为了保证性能,我们不会采用这种方案(默认使用MySQL可重复读隔离级别)。
MySQL的InnoDB引擎实现可串行化隔离级别采用的是2PL机制:在第一阶段事务执行时获取锁,第二阶段事务执行完成释放锁。
如果异常状态请求仅修改 exp_type 字段,分拣完成仅修改 status 字段的话,那么我们可以梳理一下业务逻辑,仅将必要修改的字段写入数据库,这样就不会发生丢失更新的异常,如下代码所示:
// 处理异常状态请求,封装修改数据的对象
Task task = new Task();
tast.setId(id);
task.setExpType(expType);
// 更改数据
taskService.updateById(task);
复制在执行修改数据前,创建一个新的修改对象,并只为其必要修改字段赋值。但是还需要考虑的是:如果这个业务流程处理已经很复杂了,很可能不清楚该为哪些字段赋值而导致再发生新的异常,所以采用这种方法需要对业务足够熟悉,并且在修改完后进行充分的测试。
分布式锁的方法与方法一类似,都是通过加锁的方式来保证同时只有一个事务执行,区别是方法一的锁加在了数据库层,而分布式锁是借助Redis来实现。
这种实现方式的好处是锁的粒度小,发生锁争抢仅限于单个包裹,无需像数据库加锁一样去考虑锁的粒度和对相关业务的影响。伪代码如下所示:
// 分布式锁KEY
String distributedKey = String.format(DISTRIBUTED_KEY_PREFIX, packageNo);
try {
// 分布式锁阻塞同一包裹号的修改
lock(distributedKey);
// 处理业务逻辑
handler();
} finally {
// 执行完解锁
redissonDistributedLocker.unlock(distributedKey);
}
复制需要注意,lock()加锁方法要保证加锁失败或发生其他异常情况不影响业务逻辑的执行,并设定好锁持有时间和等待锁的阻塞时间,此外解锁方法务必添加到finally代码块中保证锁的释放。
CAS是乐观的解决方案,它一般通过在数据库中增加时间戳列来记录上次数据更改的时间,当新的事务执行时,需要比对读取时该行数据的时间戳和数据库中保存的时间戳是否一致,以此来判断事务执行期间是否有其他事务修改过该行数据,只有在没有发生改变的情况下才允许更新,否则需要重试这个事务。样例SQL如下所示:
update task
set exp_type = #{expType}, status = #{status}, ts = #{currentTs}
where id = #{id} and ts = #{readTs}
复制它的原理不难理解,但是实现起来可能会存在困难,因为需要考虑在执行失败后该如何重试,重试的方式和重试的次数需要根据业务去判断。
作者:京东物流 王奕龙
来源:京东云开发者社区 自猿其说Tech 转载请注明出处