ringbuffer因为它能复用缓冲空间,通常用于网络通信连接的读写,虽然市面上已经有了go写的诸多版本的ringbuffer组件,虽然诸多版本,实现ringbuffer的核心逻辑却是不变的。但发现其内部提供的方法并不能满足我当下的需求,所以还是自己造一个吧。
源码已经上传到github
https://github.com/HobbyBear/ringbuffer
我在基于epoll实现一个网络框架时,需要预先定义好的和客户端的通信协议,当从连接读取数据时需要判读当前连接是否拥有完整的协议(实际网络环境中可能完整的协议字节只到达了部分),有才会将数据全部读取出来,然后进行处理,否则就等待下次连接可读时,再判断连接是否具有完整的协议。
由于在读取时需要先判断当前连接是否有完整协议,所以读取时不能移动读指针的位置,因为万一协议不完整的话,下次读取还要从当前的读指针位置开始读取。
所以对于ringbuffer 组件我会实现一个peek方法
func (r *RingBuffer) Peek(readOffsetBack, n int) ([]byte, error)
peek方法两个参数,n代表要读取的字节数, readOffsetBack 代表读取是要在当前读位置偏移的字节数,因为在设计协议时,往往协议不是那么简单(可能是由多个固定长度的数据构成) ,比如下面这样的协议格式。

完整的协议有三段构成,每段开头都会有一个4字节的大小代表每段的长度,在判断协议是否完整时,就必须看着3段的数据是否都全部到达。 所以在判断第二段数据是否完整时,会跳过前面3个字节去判断,此时readOffsetBack 将会是3。
此外我还需要一个通过分割符获取字节的方法,因为有时候协议不是固定长度的数组了,而是通过某个分割符判断某段协议是否结束,比如换行符。
func (r *RingBuffer) PeekBytes(readOffsetBack int, delim byte) ([]byte, error)
接着,还需要提供一个更新读位置的方法,因为一旦判断是一个完整的协议后,我会将协议数据全部读取出来,此时应该要更新读指针的位置,以便下次读取新的请求。
func (r *RingBuffer) AddReadPosition(n int)
n 便是代表需要将读指针往后偏移的n个字节。
接着,我们再来看看实际上ringbuffer的实现原理是什么。
首先来看下一个ringbuffer应该有的属性
type RingBuffer struct {
buf []byte
reader io.Reader
r int // 标记下次读取开始的位置
unReadSize int // 缓冲区中未读数据大小
}
buf 用作连接读取的缓冲区,reader 代表了原链接,r代表读取ringbuffer时应该从字节数组的哪个位置开始读取,unReadSize 代表缓冲区当中还有多少数据没有读取,因为你可能一次性从reader里读取了很多数据到buf里,但是上层应用只取buf里的部分数据,剩余的未读数据就留在了buf里,等待下次被应用层继续读取。
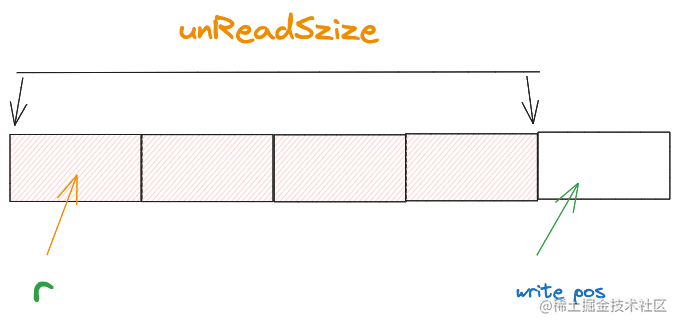
我们用一个5字节的字节数组当做缓冲区, 首先从ringbuffer读取数据时,由于ringbuffer内部没有数据,所以需要从连接中读取数据然后写到ringbuffer里。
如下图所示:
假设ringBuffer规定每次向原网络连接读取时 按4字节读取到缓冲区中(实际情况为了减少系统调用开销,这个值会更多,尽可能会一次性读取更多数据到缓冲区) write pos 指向的位置则代表从reader读取的数据应该从哪个位置开始写入到buf字节数组里。
writePos = (r + unReadSize) % len(buf)
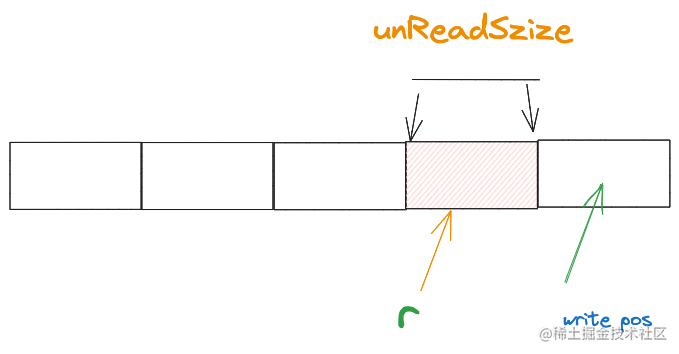
接着,上层应用只读取了3个字节,缓冲区中的读指针r和未读空间就会变成下面这样
如果此时上层应用还想再读取3个字节,那么ringbuffer就必须再向reader读取字节填充到缓冲区上,我们假设这次向reader索取3个字节。缓冲区的空间就会变成下面这样
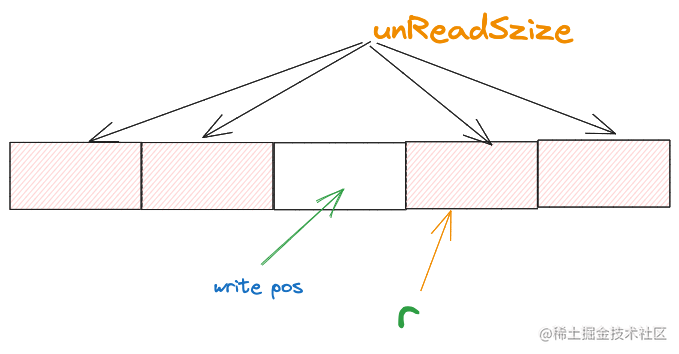
此时已经复用了首次向reader读取数据时占据的缓冲空间了。
当填充上字节后,应用层继续读取3个字节,那么ringBuffer会变成这样
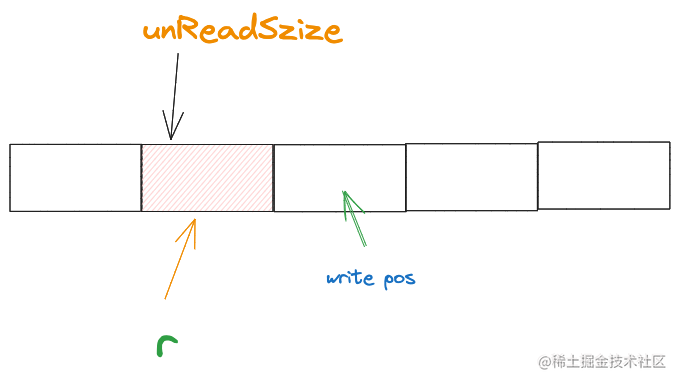
读指针又指向了数组的开头了,可以得出读指针的计算公式
r = (r + n)% len(buf)
有了前面的演示后,再来看代码就比较容易了。用peek 方法举例进行分析,
func (r *RingBuffer) Peek(readOffsetBack, n int) ([]byte, error) {
// 由于目前实现的ringBuffer还不具备自动扩容,所以不支持读取的字节数大于缓冲区的长度
if n > len(r.buf) {
return nil, fmt.Errorf("the unReadSize is over range the buffer len")
}
peek:
if n <= r.UnReadSize()-readOffsetBack {
// 说明缓冲区中的未读字节数有足够长的n个字节,从buf缓冲区直接读取
readPos := (r.r + readOffsetBack) % len(r.buf)
return r.dataByPos(readPos, (r.r+readOffsetBack+n-1)%len(r.buf)), nil
}
// 说明缓冲区中未读字节数不够n个字节那么长,还需要从reader里读取数据到缓冲区中
err := r.fill()
if err != nil {
return nil, err
}
goto peek
}
peek方法的大致逻辑是首先判断要读取的n个字节能不能从缓冲区buf里直接读取,如果能则直接返回,如果不能,则需要从reader里继续读取数据,直到buf缓冲区数据够n个字节那么长。
dataByPos 方法是根据传入的元素位置,从buf中读取在这个位置区间内的数据。
// dataByPos 返回索引值在start和end之间的数据,闭区间
func (r *RingBuffer) dataByPos(start int, end int) []byte {
// 因为环形缓冲区原因,所以末位置索引值有可能小于开始位置索引
if end < start {
return append(r.buf[start:], r.buf[:end+1]...)
}
return r.buf[start : end+1]
}
fill() 方法则是从reader中读取数据到buf里。
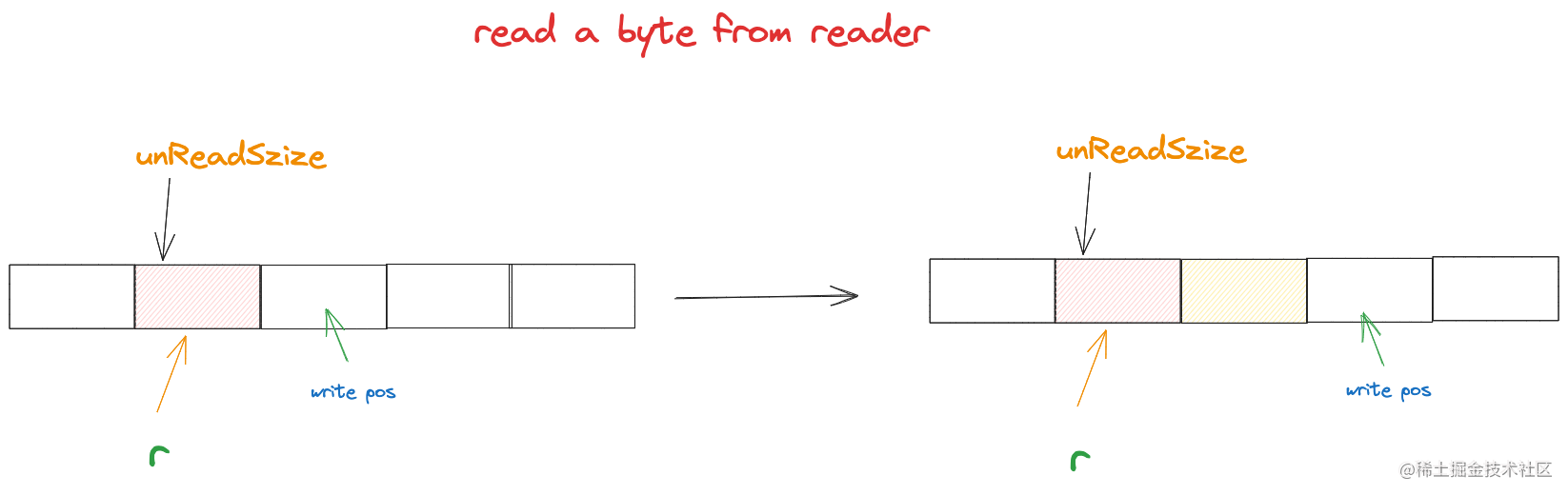
当从reader读取完数据后,如果 end := r.r + r.unReadSize + readBytes end指向了未读空间的末尾,如果没有超过buf的长度,那么将数据复制到buf里的逻辑很简单,直接在当前write pos的位置追加读取到的字节就行。
// 此时writePos 没有超过 len(buf)
writePos = (r + unReadSize)
当未读空间本来就重新覆盖了buf头部,和上面类似,这种情况也是直接在write pos 位置追加数据即可。
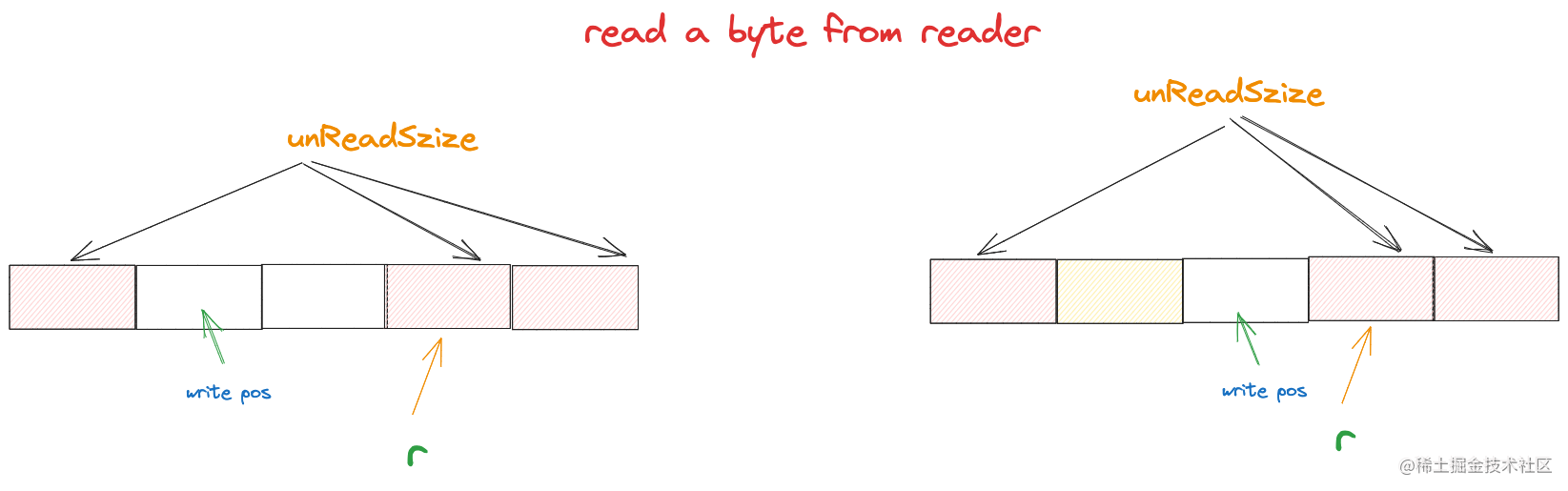

这种情况需要将读取的数据一部分覆盖到buf的末尾
writePos := (r.r + r.unReadSize) % len(r.buf)
n := copy(r.buf[writePos:], buf[:readBytes])
一部分覆盖到buf的头部
end := r.r + r.unReadSize + readBytes
copy(r.buf[:end%len(r.buf)], buf[len(r.buf)-writePos:])
现在再来看fill的源码就比较容易理解了。
func (r *RingBuffer) fill() error {
if r.unReadSize == len(r.buf) {
// 当未读数据填满buf后 ,就应该等待上层应用把未读数据读取一部分再来填充缓冲区
return fmt.Errorf("the unReadSize is over range the buffer len")
}
// batchFetchBytes 为每次向reader里读取多少个字节,如果此时buf的剩余空间比batchFetchBytes小,则应该只向reader读取剩余空间的字节数
readLen := int(math.Min(float64(r.batchFetchBytes), float64(len(r.buf)-r.unReadSize)))
buf := make([]byte, readLen)
readBytes, err := r.reader.Read(buf)
if readBytes > 0 {
// 查看读取readBytes个字节后,未读空间有没有超过buf末尾指针,如果超过了,在复制数据时需要特殊处理
end := r.r + r.unReadSize + readBytes
if end < len(r.buf) {
// 没有超过末尾指针,直接将数据copy到writePos后面
copy(r.buf[r.r+r.unReadSize:], buf[:readBytes])
} else {
// 超过了末尾指针,有两种情况,看下图分析
writePos := (r.r + r.unReadSize) % len(r.buf)
n := copy(r.buf[writePos:], buf[:readBytes])
if n < readBytes {
copy(r.buf[:end%len(r.buf)], buf[len(r.buf)-writePos:])
}
}
r.unReadSize += readBytes
return nil
}
if err != nil {
return err
}
return nil
}