大家好,我是蓝胖子,关于性能分析的视频和文章我也大大小小出了有一二十篇了,算是已经有了一个系列,之前的代码已经上传到github.com/HobbyBear/performance-analyze,接下来这段时间我将在之前内容的基础上,结合自己在公司生产上构建监控系统的经验,详细的展示如何对线上服务进行监控,内容涉及到的指标设计,软件配置,监控方案等等你都可以拿来直接复刻到你的项目里,这是一套非常适合中小企业的监控体系。
在上一节我们是讲解了如何对应用服务进行监控,这一节我将会介绍如何对mysql进行监控,在传统监控mysql(对mysql整体服务质量的监控)的情况下,建立对表级别的监控,以及长事务,复杂sql的监控,并能定位到具体代码。
监控系列的代码已经上传到github
github.com/HobbyBear/easymonitor复制
无论是前文提到的 机器监控还是应用监控,我们都提到了四大黄金指标原则,对mysql 建立监控指标,我们依然可以从这几个维度去对mysql的指标进行分析。
四大黄金指标是流量,延迟,饱和度,错误数。
对于流量而言可以体现在mysql数据库操作的qps,数据库服务器进行流量大小。对于延迟,可以体现在慢查询记录上,饱和度可以用数据库的连接数,线程数,或者磁盘空间,cpu,内存等各种硬件资源来反映数据库的饱和情况。错误数则可以用,数据库访问报错信息来反应,比如连接不足,超时等错误。
由于我们是用的云数据库,上面提到的这些监控维度以及面板在云厂商那里其实都基本覆盖了,我称这些监控面板或者维度是数据库的传统监控指标。 这些指标能够反应数据库监控状况,但对于开发来讲,去进行问题排查还远远不足的,下面我讲下如果只有此类型的监控会有什么缺点以及我的解决思路。
在使用它们对mysql进行监控时当异常发生时,不是能很好的确定是哪部分业务导致的问题。比如,当你发现数据库的qps突然升高,但是接口qps比较低的时候,如何确定数据库qps升高的原因呢? 这中间存在的问题在于mysql的数据监控指标和应用服务代码逻辑没有很好的关联性,我们要如何去建立这种关联系?
答案就是建立表级别的监控,你可以发现传统的监控指标都是对mysql整体服务质量进行的监控,而应用业务逻辑代码本质上是对表进行操作,如果建立了表级别的监控,就能将业务与数据库监控指标联系起来。比如按表级别建立单个表的qps,当发现数据库整体的qps升高时,可以发现这是由于哪张表引起的,进而定位到具体业务,查看代码逻辑看看是哪部分逻辑会操作这张表那么多次。
下面我们就来看看如何建立表级别的监控。
mysql的performance schema其实已经暴露了表级别的某些监控项,不过由于某些原因我们线上并没有开启它,并且由于直接使用performance schema暴露的监控指标不能定制化,所以我将介绍一种在应用服务端埋点的方式建立表级别的qps。我们生产上是golang的应用服务,所以我会用它来举例。
用github.com/go-sql-driver/mysql 在golang中开启一个mysql连接是这样做:
db, err = sql.Open("mysql", connStr)
复制sql.Open的第一个参数是驱动名,默认的驱动名是mysql,这个驱动是引入github.com/go-sql-driver/mysql时自动去创建的。
func init() {
sql.Register("mysql", &MySQLDriver{})
}
复制所以,我们完全可以包装默认驱动,自定义一个自己的驱动,驱动实现了open接口返回一个连接Conn的接口类型。
type Driver interface {
Open(name string) (Conn, error)
}
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}
type Stmt interface {
Close() error
NumInput() int
Exec(args []Value) (Result, error)
Query(args []Value) (Rows, error)
}
复制自定义的驱动类型在实现Open方法时,也可以自定义一个Conn连接类型,然后再实现它的查询接口,进行sql语句分析,解析表名后进行埋点统计。
完整的定义驱动代码已经上传到文章开头的github地址,总之,你需要明白,通过对默认驱动的包装,我们可以在sql执行前后做一些自定义的监控分析。我们定义了3个钩子函数,分别针对sql执行前后以及报错做了监控分析。
对于sql埋点的原理更详细的讲解可以参考go database sql接口分析及sql埋点实现
// sql执行前做监控
if ctx, err = stmt.hooks.Before(ctx, stmt.query, list...); err != nil {
return nil, err
}
// sql执行
results, err := stmt.execContext(ctx, args)
if err != nil {
// sql 报错时做监控
return results, handlerErr(ctx, stmt.hooks, err, stmt.query, list...)
}
// sql执行后做监控
if _, err := stmt.hooks.After(ctx, stmt.query, list...); err != nil {
return nil, err
}
复制在sql执行前,通过SqlMonitor.parseTable对sql语句的分析,解析出当前sql涉及的表名,以及操作类型,是insert,select,delete,还是update,并且如果sql涉及到了多张表,那么会对其打上MultiTable的标签(这在下面讲sql审计时会提到),sql执行前的钩子函数如下所示:
func (h *HookDb) Before(ctx context.Context, query string, args ...interface{}) (context.Context, error) {
ctx = context.WithValue(ctx, ctxKeyBeginTime, time.Now())
// 得到sql涉及的表名,以及这条sql是属于什么crud的哪种类型
tables, op, err := SqlMonitor.parseTable(query)
if err != nil || op == Unknown {
log.WithError(err).WithField(ctxKeySql, query).WithField("op", op).Error("parse sql fail")
}
if len(tables) >= 2 {
ctx = context.WithValue(ctx, ctxKeyMultiTable, 1)
}
if len(tables) >= 1 {
ctx = context.WithValue(ctx, ctxKeyTbName, tables[0])
}
if op != Unknown {
ctx = context.WithValue(ctx, ctxKeyOp, op)
}
return ctx, nil
}
复制分析出了表名并且记录上了sql的执行时长,我们可以利用prometheus的histogram 类型的指标建立表维度的p99延迟分位数,并且能够知道表级别的qps数量,如下,我们可以在sql执行后的钩子函数里完成统计,MetricMonitor.RecordClientHandlerSeconds封装了这个逻辑。
func (h *HookDb) After(ctx context.Context, query string, args ...interface{}) (context.Context, error) {
// ....
if tbnameInf := ctx.Value(ctxKeyTbName); tbnameInf != nil && len(tbnameInf.(string)) != 0 {
tableName = tbnameInf.(string)
MetricMonitor.RecordClientHandlerSeconds(TypeMySQL, string(ctx.Value(ctxKeyOp).(SqlOp)), tbnameInf.(string), h.dbName, now.Sub(beginTime).Seconds())
// .....
}
复制我们可以利用这个指标在grafana上完成表级别的监控面板。
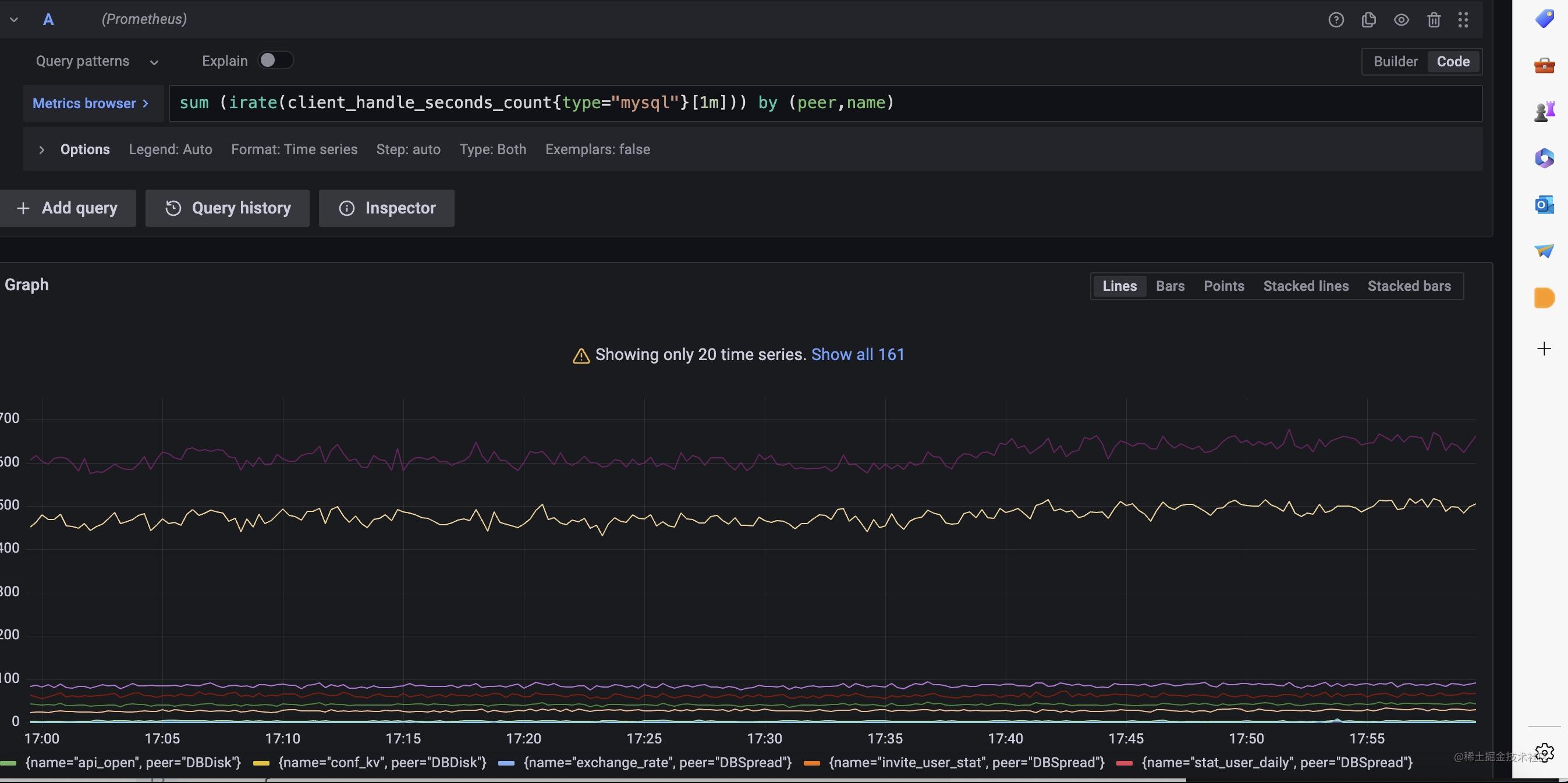
对于数据库还有要需要注意的地方,那就是长事务和复杂sql,慢sql的监控,往往出现上述情况时,就容易出现数据库的性能问题。现在我们来看看如何监控它们。
首先,来看下长事务的监控,我们可以为连接类型实现BeginTx方法,对原始driver.ConnBeginTx 事务类型进行包装,让事务携带上开始时间。
func (conn *Conn) BeginTx(ctx context.Context, opts driver.TxOptions) (driver.Tx, error) {
tx, err := conn.Conn.(driver.ConnBeginTx).BeginTx(ctx, opts)
if err != nil {
return tx, err
}
return &DriveTx{tx: tx, start: time.Now()}, nil
}
复制接着,在提交事务的时候,判断时间是不是超过某个8s,超过了则记录一条错误日志,并把堆栈信息也打印出来,这样方便定位是哪段逻辑产生的长事务。由于我们的错误等级的日志会被收集起来自动报警,这样就完成了长事务的实时监控报警。
func (d *DriveTx) Commit() error {
err := d.tx.Commit()
d.cost = time.Now().Sub(d.start).Milliseconds()
if d.cost > 8000 {
data := log.Fields{
Cost: d.cost,
MetricType: "longTx",
Stack: fmt.Sprintf("%+v", getStack()),
}
log.WithFields(data).Errorf("mysqlongTxlog ")
}
return err
}
复制接着,我们看下sql审计如何做,mysql可以打开sql审计的配置项,不过打开后将会采集所有执行的sql语句,这样会导致sql太多,我们往往只用关心那些影响性能的sql或者让数据产生变化的sql。
代码如下,我们在sql完成执行后,通过sql的执行时长,对慢sql进行告警出来,并且对涉及到两个表的sql进行日志打印,也会对修改数据的sql语句(insert,update,delete)进行记录,这对我们排查业务数据会很有帮助。
func (h *HookDb) After(ctx context.Context, query string, args ...interface{}) (context.Context, error) {
beginTime := time.Now()
if begin := ctx.Value(ctxKeyBeginTime); begin != nil {
beginTime = begin.(time.Time)
}
now := time.Now()
tableName := ""
if tbnameInf := ctx.Value(ctxKeyTbName); tbnameInf != nil && len(tbnameInf.(string)) != 0 {
tableName = tbnameInf.(string)
MetricMonitor.RecordClientHandlerSeconds(TypeMySQL, string(ctx.Value(ctxKeyOp).(SqlOp)), tbnameInf.(string), h.dbName, now.Sub(beginTime).Seconds())
}
// 对慢sql进行实时监控,超过1s则认为是慢sql
slowquery := false
if now.Sub(beginTime).Seconds() >= 1 {
slowquery = true
data := log.Fields{
Cost: now.Sub(beginTime).Milliseconds(),
"query": truncateKey(1024, query),
"args": truncateKey(1024, fmt.Sprintf("%v", args)),
MetricType: "slowLog",
"app": h.app,
"dbName": h.dbName,
"tableName": tableName,
"op": ctx.Value(ctxKeyOp),
}
log.WithFields(data).Errorf("mysqlslowlog")
}
op := ctx.Value(ctxKeyOp).(SqlOp)
multitable := ctx.Value(ctxKeyMultiTable)
if !slowquery && (multitable != nil && multitable.(int) == 1) && op == Select {
// 对复杂sql进行监控,如果不是慢sql,但是sql涉及到两个表也会日志进行记录
data := log.Fields{
Cost: now.Sub(beginTime).Milliseconds(),
"query": truncateKey(1024, query),
"args": truncateKey(1024, fmt.Sprintf("%v", args)),
MetricType: "multiTables",
"app": h.app,
"dbName": h.dbName,
"tableName": tableName,
"op": ctx.Value(ctxKeyOp),
}
log.WithFields(data).Warnf("mysqlmultitableslog")
}
// 对修改数据的sql进行日志记录
if op != Select && op != Unknown {
data := log.Fields{
Cost: now.Sub(beginTime).Milliseconds(),
"query": truncateKey(1024, query),
"args": truncateKey(1024, fmt.Sprintf("%v", args)),
MetricType: "oplog",
"app": h.app,
"dbName": h.dbName,
"tableName": tableName,
"op": ctx.Value(ctxKeyOp),
}
log.WithFields(data).Infof("mysqloplog")
}
return ctx, nil
}
复制这一节我们完成了对mysql的监控,不过这个监控指标是在传统数据库监控项基础上建立的,目的是为了让监控指标更加容易反映到业务上,方便问题定位,在下一节我将会演示如何对redis进行监控,与mysql监控类似,我们也需要从业务维度思考对redis的监控。