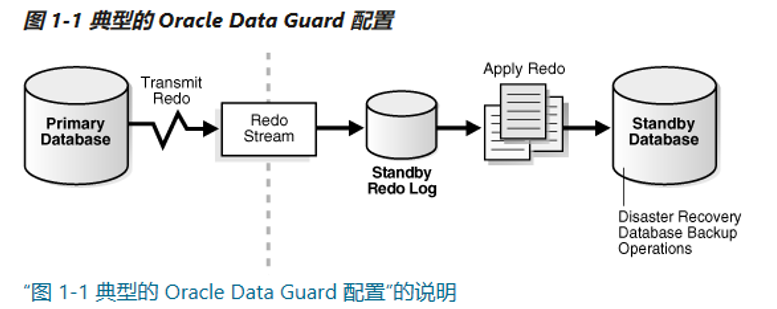
Oracle Data Guard通过从主数据库传输redo data,然后将apply redo到备用数据库,自动维护每个备用数据库。DG分为3个服务:
一是redo传输服务,根据DG的3种不同的保护模式(最大程度保护,最大可用性,最高性能),选择redo传输是采用同步还是异步,异步表示主库事务提交,不需要等待redo发送到备库;
二是,apply服务,备库有3中类型,其中物理备用数据库和逻辑备用数据库的主要差别是,主库的redo data传输到备库有,apply方式不同;同时可以是Real-Time Apply,也可以是延迟apply,其中real-time apply是在收到redo data时应用重做数据,而无需等待当前standy redo log file被存档;而延迟apply,是不影响redo data传输到备库,而是等到备库standy redo log 归档到archive redo log file后,开始延迟;因为是apply redo,所以备库是只读状态,可用于查询;如果有ADG许可,备库可在open状态apply redo,做到实时查询;
三是,role转换,分为switchover,维护性切换,不丢数据,另一种是failover,主库故障时的被动切换,可能会丢部分数据;
DG配置时需要开启归档,同时需要相同版本的数据库之间进行,不支持数据库异构;
使用Oracle GoldenGate 实时加载、分发和筛选企业内的事务,并在不同数据库之间实现零停机迁移。支持多对一,一对多等拓扑场景;
OGG的流程中,一是提取或捕获;在初始加载时,从source table中捕获当前静态数据集合;在后续同步时,提取的时data base recovery log或transaction logs,比如redo log,以保持源数据和目标数据的一致性;Extracts会存储这些操作,如果收到rollback,它会放弃该事务的操作,如果收到commit record,就会将事务保存在一系列的trail file中,并排队传输到目标系统;
二是replicat,之前捕获的数据会存放到trail file,Replicat是一个将数据传递到目标系统的过程。它读取目标数据库上的trail file,重建DML或DDL操作,并将它们应用于目标数据库。可以配置replicat进程,在应用到目标库时设置等待时间;可以将多个replicat进程对应一个或多个Extract进程(多对一或多对多),提高吞吐量;
三是设置数据传输的分发路径,distribution 路径定义了端点之间trail file的传输路径;distribution path是distribution service配置的;
Oracle RAC 环境在数据库和实例之间具有一对多关系。一个 Oracle RAC 数据库可以有多个实例;提高负载和实例冗余;通过Oracle RAC 环境提高 Oracle 数据库的性能和可用性。
在Oracle RAC中,网络分为Public IP、Private IP、Virtual IP、SCAN IP、GNS VIP及HAIP;
从Oracle 11g开始,传统安装RAC至少需要7个IP地址,每个节点两块网卡(一块公网网卡,一块私网网卡),其中public、vip和scan都在同一个网段,使用的是公网网卡;private在另一个网段,使用的是私网网卡;
在安装RAC之前,公网、私网共4个IP可以ping通,其它2个vip和1个scan ip不能ping通才是正常的。从Oracle 18c开始,scan建议至少为3个。 HAIP是用于解决私网的冗余问题;
在HAIP之前,都是通过系统层面绑定进行冗余,但不稳定,一般禁用;GNS VIP用于GNS服务从DHCP服务器动态获取的VIP和scan ip,也很少使用;
Oracle DataGuard;简称DG。是由一个Primary Database(主库)和一个或者多个Standby Database(备库)组成。由Primary Database对外提供服务;然后,如果生产数据库由于计划内或计划外停机而变得不可用,Oracle Data Guard 可以将任何备用数据库切换到生产角色,从而最大限度地减少与中断相关的停机时间。Oracle Data Guard配置中,成员通过Oracle Net连接;
Oracle Data Guard 传输服务还被其他 Oracle 功能(如 Oracle Streams 和 Oracle GoldenGate)用于将重做从源数据库高效可靠地传输到一个或多个远程目标。
主数据库可以是单实例 Oracle 数据库,也可以是 Oracle Real Application Clusters (Oracle RAC) 数据库。
Oracle Data Guard通过从主库传输redo data,然后将redo 应用到备库,来自动维护每个备库;
配置条件:
Oracle Data Guard 仅作为 Oracle Database Enterprise Edition 的一项功能提供。它不适用于 Oracle 数据库标准版。
主数据库和所有备用数据库上都必须安装相同版本的Oracle Database Enterprise Edition,使用逻辑或临时逻辑备用(TLS)数据库进行滚动数据库升级时除外。
主库需要开启归档模式;
Oracle Data Guard为Oracle Data Guard配置提供了更大的灵活性,在这些配置中,主系统和备用系统可能具有不同的CPU体系结构、操作系统(例如,Windows和Linux)、操作系统二进制文件(32-bit/64位)或Oracle数据库二进制文件(32/64位)。
备用数据库可以是以下类型之一:物理备用数据库、逻辑备用数据库或快照备用数据库。如果需要,物理数据库或逻辑备用数据库可以承担主数据库的角色并接管生产处理。Oracle Data Guard 配置可以包含这些类型的备用数据库的任意组合。
备用数据库是主数据库的事务一致性副本。使用主数据库的备份副本,最多可以创建30个备用数据库,并将它们合并到Oracle Data Guard配置中。
Oracle Data Guard通过从主数据库传输redo data,然后将apply redo到备用数据库,自动维护每个备用数据库。
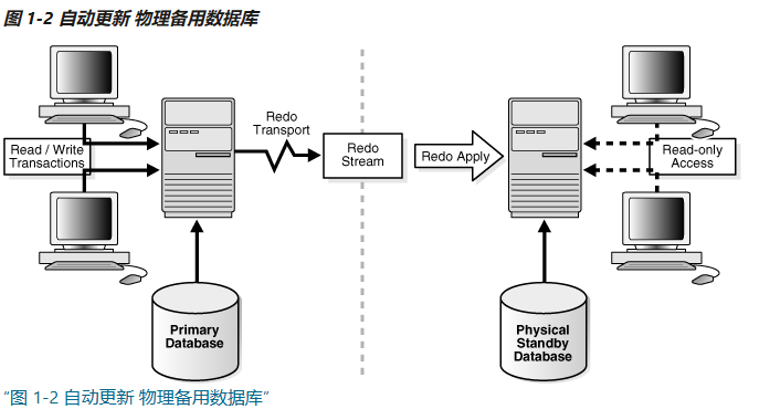
物理备用数据库是主数据库的精确block-for-block copy(块对块副本)。
物理备用通过 “Redo Apply”的过程作为精确副本进行维护,在该过程中,使用数据库恢复机制将从主数据库接收的redo data连续应用于物理备用数据库。
物理备用数据库可以打开进行只读访问,并用于分担主数据库中的查询任务。如果已购买Oracle Active Data Guard选项的许可证,则也可以在物理备用数据库open时,进行“Redo Apply”的动作,从而允许查询返回与从主数据库返回的结果相同的结果。这种功能被称为real-time query feature(实时查询功能)。
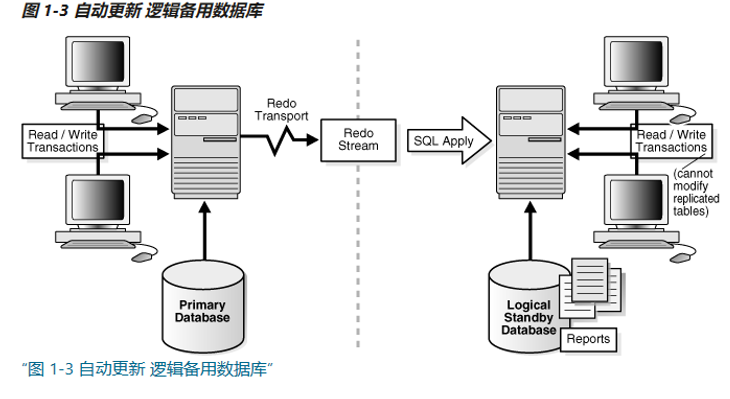
包含与生产数据库相同的逻辑信息,尽管数据的物理组织和结构可能不同。逻辑备用数据库通过 SQL Apply 与主数据库保持同步,它将从主数据库接收的redo中的data转换为 SQL 语句,然后在备用数据库上执行 SQL 语句。
逻辑备用数据库的灵活性允许您升级 Oracle 数据库 软件(补丁集和新的 Oracle 数据库版本)并执行其他 以滚动方式进行数据库维护,几乎没有停机时间。transient logical database滚动升级过程也可以与现有物理数据库一起使用 备用数据库。
Oracle Data Guard通过将日志文件中的数据转换为SQL语句,然后在逻辑备用数据库上执行SQL语句,自动将存档的redo log文件或standby redo log文件的信息应用到逻辑备用数据库。因为逻辑备用数据库是使用SQL语句更新的,所以它必须保持打开状态。尽管逻辑备用数据库是以读/写模式打开的,但其用于重新生成SQL的目标表仅可用于只读操作。在更新这些表时,它们可以同时用于其他任务,如报告、汇总和查询。
逻辑备用数据库对数据类型、表类型以及DDL和DML操作的类型有一些限制。
快照备用数据库是一种可更新的备用数据库,为主数据库提供完整的数据保护。
快照备用数据库从其主数据库接收并归档(但不应用)重做数据。在放弃快照备用数据库的所有本地更新后,当快照备用数据库转换回物理备用数据库时,将应用从主数据库接收的重做数据。
随着时间的推移,快照备用数据库与其主数据库不同,因为在接收到来自主数据库的重做数据时不会应用该数据。快照备用数据库的本地更新会导致额外的差异。但是,主数据库中的数据是完全受保护的,因为快照备用数据库可以随时转换回物理备用数据库,然后应用从主数据库接收的重做数据。
Far sync instances,远同步实例;
Oracle Data Guard远同步实例是一个远程Oracle数据Guard目标,它接受来自主数据库的redo,然后将该redo发送给Oracle Data Guards配置的其他成员。
远同步实例管理一个控制文件,将redo接收到备用standby redo logs(SRL)中,并将这些SRL归档到local archived redo logs中,但这就是与standby日志 相似之处的结束。远同步实例没有用户数据文件,无法打开进行访问,无法运行redo-apply,并且永远无法在主角色中运行,也无法转换为任何类型的备用数据库。
远同步实例是Oracle Active Data Guard远同步功能的一部分,该功能需要Oracle Active Data Protection许可证。
零数据丢失恢复一体机(恢复一体机)是一种企业级备份解决方案,它为所有 Oracle 数据库的备份提供单一存储库。
从oracle 21c开始,可以为在一个multitenant container database (CDB,可插入数据库)的一个或多个pluggable databases (PDBs,可插入数据库)提供保护;
这个配置由2个主库组成,包含必须保护的PDB的主数据库称为源数据库。将源数据库中的redo data传送到目标数据库,目标数据库也是主数据库。使用Oracle Data Guard broker为PDB配置数据保护。
Oracle Data Guard 使用redo transport services(redo传输服务)和Apply Services(应用服务)来管理redo data的传输、重做数据的应用以及对数据库角色的更改。
redo传输服务,redo传输服务在Oracle data Guard配置的成员和其他数据库之间执行redo data的自动传输。
支持的redo transport destinations,有:
1)、Oracle Data Guard standby databases
2)、Oracle Data Guard primary databases
只有Oracle Data Guard broker才支持此作为目标。主数据库用作重做传输目的地,为数据库中的一个或多个可插入数据库(pluggable databases ,PDB)提供数据保护。
3)、归档日志存储库
Archive log repository,此目标类型用于archive redo log文件的临时异地存储。Archive log repository由一个Oracle数据库实例和一个物理备用控制文件组成。存档日志存储库不包含数据文件,因此无法支持角色转换。
除了复制数据文件外,用于创建Archive log repository的过程与用于创建物理备用数据库的过程相同。
4)、Oracle Streams下游捕获数据库
5)、远同步实例
6)、零数据丢失恢复设备(恢复设备)
每个redo传输目的地被单独配置为通过两种redo传输模式之一接收重做数据:
1)、同步
synchronous redo transport mode针对事务承诺同步传输redo data。在事务生成的所有redo都已成功发送到每个enable同步重做传输模式的重做传输目标后,事务才能提交。
尽管主数据库和SYNC重做传输目的地之间的距离没有限制,但事务提交延迟会随着主数据库和SYNC重做传输目标之间网络延迟的增加而增加。
此传输模式由Oracle data Guard保护模式中描述的最大程度保护和最大可用性数据保护模式使用。
注意:零数据丢失恢复设备不支持同步重做传输。
2)、异步
异步重做传输模式相对于事务承诺异步传输redo log。事务可以提交,而无需等待该事务生成的redo成功发送到任何使用异步重做传输模式的重做传输目标。
此传输模式由Oracle data Guard保护模式中所述的最高性能数据保护模式使用。
管理备用重做日志
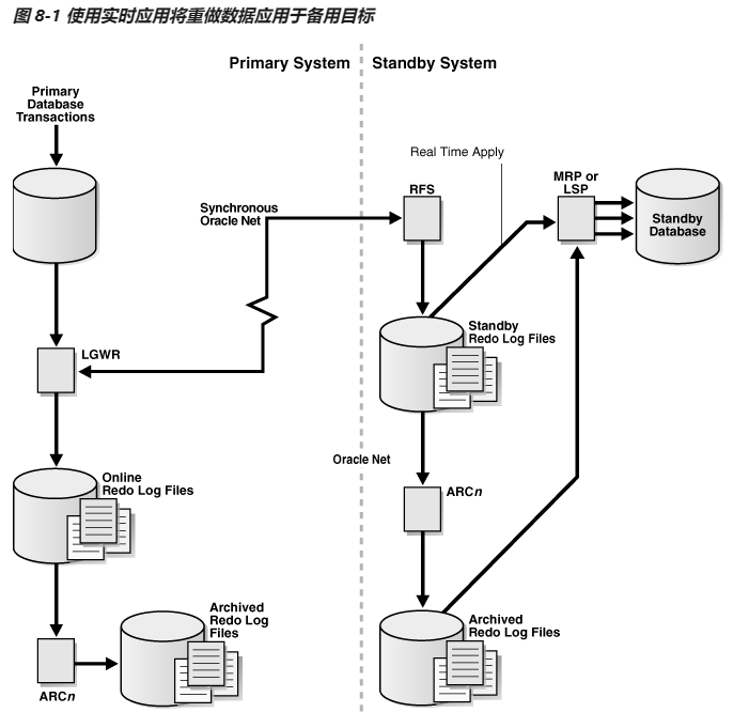
同步和异步redo传输模式要求重做传输目标具有standby redo log。standby redo log用于存储从另一个 Oracle 数据库收到的redo。standby redo log在结构上与redo log相同,并且使用用于创建和管理redo log的相同 SQL 语句进行创建和管理。
通过redo 传输接收到的redo ,有remote file server(RFS,远程文件服务器)前台进程写入当前的redo log group;当源库发生日志切换时,传入的redo将写入写一个standby redo log组,以前的standby redo log组由ARCn后台进程存档;
应用服务会自动在备用数据库上应用重做数据,以保持与主数据库的一致性。如果未配置备用重做日志文件,那么必须先在备用数据库中归档重做数据,然后再应用该数据。
physical and logical standby databases的区别是:
1)、Redo Apply (physical standby databases only)
使用介质恢复(media recovery)使主数据库和物理备用数据库保持同步。
2)、SQL Apply (logical standby databases only)
从从主数据库接收到的重做重构 SQL 语句,并对逻辑备用数据库执行 SQL 语句。
1、对于物理备用数据库,Oracle Data Guard 使用 Redo Apply 技术, 使用标准恢复在备用数据库上应用重做数据 Oracle 数据库的技术,如图 1-2 所示。
使用介质恢复(media recovery)使主数据库和物理备用数据库保持同步。
2、对于逻辑备用数据库,Oracle Data Guard 使用 SQL Apply技术,首先将收到的重做数据转换为 SQL 语句,然后在逻辑备用数据库上执行生成的 SQL 语句 数据库,如图1-3所示。
应用服务配置选项
可以立即应用重做数据,也可以指定时间延迟来应用存档的重做日志文件。
使用Real-Time Apply来立即应用重做数据
如果启用了实时应用功能,则应用服务可以在收到redo data时应用重做数据,而无需等待当前standy redo log file被存档。这样可以缩短切换和故障转移时间,因为在故障转移或切换开始时,备用重做日志文件已应用于备用数据库。它还支持对 Oracle Active Data Guard 备用数据库进行实时报告,使其与主数据库保持更紧密的同步。
指定应用存档重做日志文件的时间延迟
在某些情况下,可能希望在从主站点接收redo data和将其应用于备用数据库之间创建一个时间滞后。
可以指定一个时间间隔(以分钟为单位),以防止将损坏或错误的数据应用到备用数据库(防止逻辑村的的问题,也可以由闪回数据库替代;)。设置DELAY间隔时,不会延迟将redo data传输到备用数据库。相反,当redo data在备用目的地完全存档时,您指定的时间滞后就开始了。 (也就是delay参数是从redo log归档后开始计算)
使用切换或故障转移操作将数据库的角色从备用数据库更改为主数据库,或从主数据库更改为备用数据库。
Oracle 数据库以以下两种角色之一运行:主角色或备用数据库。
Switchover(切换)是主数据库与其备用数据库之一之间的角色转换。切换可确保不会丢失数据。这通常用于主系统的计划内维护。在切换期间,主数据库将转换为备用角色,备用数据库将转换为主角色。
Failover(故障转移)是指主数据库不可用。故障转移仅在主数据库发生故障时执行,将备用数据库更改为主要角色以响应主数据库故障。如果主数据库在发生故障之前未在最大保护模式或最大可用性模式下运行,则可能会发生一些数据丢失。如果在主数据库上启用了闪回数据库,那么一旦纠正故障原因,就可以将其恢复为新主数据库的备用数据库。
从 Oracle 数据库版本 21c 开始,可以执行切换或 多租户容器数据库 (CDB) 中的可插入数据库 (PDB) 的故障转移。 此功能仅受 Oracle Data Guard 代理支持。
在某些情况下,无论情况如何,企业都无法承受丢失数据的后果。在其他情况下,在不太可能发生多次故障的情况下,数据库的可用性可能比任何潜在的数据丢失更重要。最后,某些应用程序始终需要最大的数据库性能,因此如果任何组件发生故障,可以容忍少量数据丢失。以下是可用于每种情况的保护模式的简要说明:
所有三种保护模式都需要特定的重做传输选项 用于将重做数据发送到至少一个备用数据库。
此模式下确保当主库故障时,没有数据丢失;在事务提交之前,必须将恢复事务所需的redo data写入至少一个同步主库的online redo log和备用数据库上的standby redo log; 为了确保数据不会丢失,如果主数据库无法将其重做流写入至少一个同步的备用数据库,则主数据库将shut down,而不是继续处理事务。
此保护模式可在不影响主数据库可用性的情况下提供最高级别的数据保护。
使用Oracle Data Guard,只有在内存中接收到恢复这些事务所需的所有redo data或将这些数据写入至少一个同步备用数据库上的standby redo log(取决于配置)后,事务才会commit。
如果主数据库无法将其重做流写入至少一个同步备用数据库,则它会像处于最高性能模式一样运行,以保持主数据库的可用性,直到它能够再次将其重做数据流写入同步备用数据库。
这种保护模式确保了零数据丢失,除非出现某些双重故障,例如备用数据库发生故障后主数据库发生故障。
这是默认的保护模式。它提供了最高级别的数据保护,而不会影响主数据库的性能。这是通过允许事务在这些事务生成的所有redo data写入online log后立即提交来实现的。
Redo data也会写入一个或多个备用数据库,但这是相对于事务承诺异步完成的,因此主数据库性能不会受到向备用数据库写入重做数据延迟的影响。
与最大可用性模式相比,此保护模式提供的数据保护略少,并且对主数据库性能的影响最小。
在 Primary Database 产生的 Redo 日志;传送到 Standby Database;是通过 LGWR 或者 ARCH 进程完成。这个很好理解。默认情况下是由 ARCH 进程。有参数 *.LOG_ARCHIVE_DEST_2 控制的。使用 ARCH 进程; Primary Database 和 Standby Database 存在数据延迟。若 Primary Database 出现异常;容易造成部分数据丢失。为了避免数据丢失,必须要使用 LGWR 进程,需要用到 Standby Redolog。而LGWR 又分SYNC(同步)和ASYNC(异步)两种方式。
SYNC方式:对网络要求比较高;必须等待写入本地日志文件操作和通过LNSn进程的网络传送都成功,Primary Database 上的事务才能提交成功。使用LGWR SYNC方式时,可以同时使用NET_TIMEOUT参数,这个参数单位是秒,代表如果多长时间内网络发送没有响应,LGWR 进程会抛出错误。因此对 Primary Database 性能有影响。
客户端故障转移
高可用性体系结构需要database和database client的快速故障转移功能。客户端故障转移包括故障通知、过时连接清理以及与新主数据库的透明重新连接。
Oracle 数据库提供了将数据库故障转移与故障转移过程集成的功能,这些故障转移过程可在数据库故障转移后的几秒钟内自动将客户端重定向到新的主数据库。
应用程序连续性
应用程序连续性是Oracle数据库的一项功能,在发生可恢复的错误导致数据库会话不可用后,它可以快速、无中断地重播针对数据库的请求。
Oracle Data Guard切换到physical standby databases时支持应用程序连续性。它还支持在最大可用性数据保护模式下快速启动故障切换到物理备用。要使用“应用程序连续性”,主数据库和备用数据库必须获得Oracle Real Application Clusters(Oracle RAC)或Oracle Active Data Guard的许可。
Oracle 数据库提供了多种独特的技术,可补充 Oracle Data Guard,帮助保持业务关键型系统运行,与单独使用任何一种解决方案相比,具有更高级别的可用性和数据保护。
1、oracle rac
2、oracle rac one node
3、闪回数据库
Flashback Database,Flashback数据库功能可从逻辑数据损坏和用户错误中快速恢复。通过允许您及时返回,可以再次访问可能被错误更改或删除的以前版本的业务信息。此功能:
1)、无需恢复备份并将更改前滚到出现错误或损坏时为止。相反,Flashback Database可以将Oracle数据库回滚到以前的时间点,而无需恢复数据文件。
2)、提供延迟应用重做的替代方案,以防止用户错误或逻辑损坏。因此,备用数据库可以与主数据库更紧密地同步,从而减少故障切换和切换时间。
3)、避免了在故障切换后完全重新创建原始主数据库的需要。发生故障的主数据库可以闪回到故障切换前的某个时间点,并转换为新主数据库的备用数据库。
4、RMAN
RMAN 是一个 Oracle 实用程序,可简化数据库文件的备份、还原和恢复。Oracle Data Guard与RMAN集成良好,使能够:
1)、使用Recovery Manager DUPLICATE命令从主数据库的备份中创建备用数据库。
2)、在物理备用数据库而不是生产数据库上进行备份,从而减轻生产数据库的负载,并能够高效使用备用站点上的系统资源。此外,可以在物理备用数据库应用重做时进行备份。
3)、通过在执行备份后自动删除用于输入的已存档重做日志文件,帮助管理已存档的重做日志文件。
Oracle GoldenGate是一款应用程序,它提供实时数据集成、数据复制、事务性更改数据捕获、数据转换、高可用性解决方案,以及运营和分析企业系统之间的验证。
使用Oracle GoldenGate,可以通过安全或非安全配置跨企业中的多个系统移动已提交的事务。它支持广泛的数据库和数据源,提供相同类型之间或异构数据库之间的复制。例如,可以在Oracle自治数据库实例和Oracle数据库实例之间进行复制,或者在设置为源和目标的两个Oracle数据库实例间进行复制,也可以在MySQL数据库和Oracle数据库示例之间进行双向复制。此外,还可以与Oracle GoldenGate for Big Data一起复制到Java消息队列、平面文件和大数据。
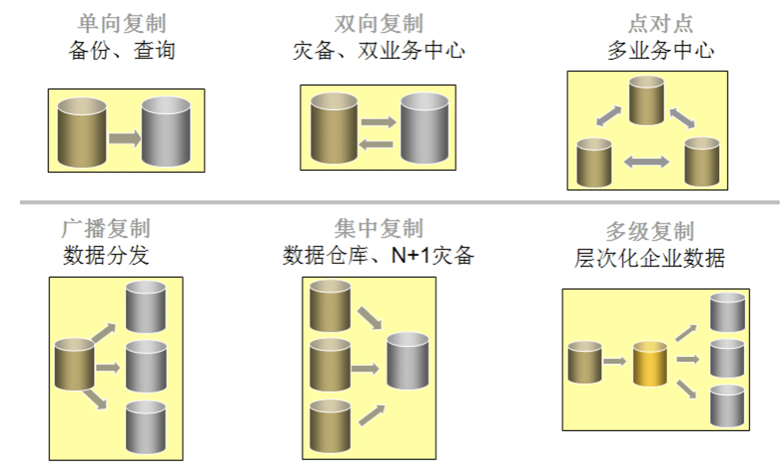
单向复制:由一个源数据库复制到一个目的数据库,一般用于高可用性和容灾,为生产机保持一个活动的备份数据库,从而在发生灾难的时候迅速切换,减少数据丢失和系统宕机时间;
双向复制:利用GoldenGate TDM可以实现两个数据库之间数据的双向复制,任何一方的数据变化都会被传递到另一端,可以利用此模式开展双业务中心;
广播复制:由一个数据库向多个数据库复制,利用GoldenGate TDM的数据过滤功能可以实现数据的有选择分发;
集中复制:由多个数据库向一个数据库复制,可以将分布的、跨平台或异构的多个数据库集中到一个数据库。此种模式广泛应用于n+1模式的容灾,通过将多个系统数据库集中到一起,可以充分利用备份中心的设施,大幅减少投资;另外也用于跨平台多系统的数据集成,为这些提供系统提供一个统一视图便于查询和统计数据。
多层复制:由A数据库向B复制,同时又由B向C复制,可以在以上几种模式基础上无限制扩展。
由此可见,GoldenGate TDM的复制模式非常灵活,用户可以根据自己的需求选择特定的复制方式,并根据系统扩展对复制进行扩展。
Oracle GoldenGate 可以针对以下目的进行配置:
1)、从一个数据库静态提取数据记录,并将这些记录加载到另一个数据库或数据源。
2)、持续提取和复制事务性数据操作语言 (DML) 操作和数据定义语言 (DDL) 更改(对于受支持的数据库),以保持源数据和目标数据的一致性。
3)、从支持的数据库源中提取数据,并使用 Oracle GoldenGate for Big Data复制到大数据和文件目标。
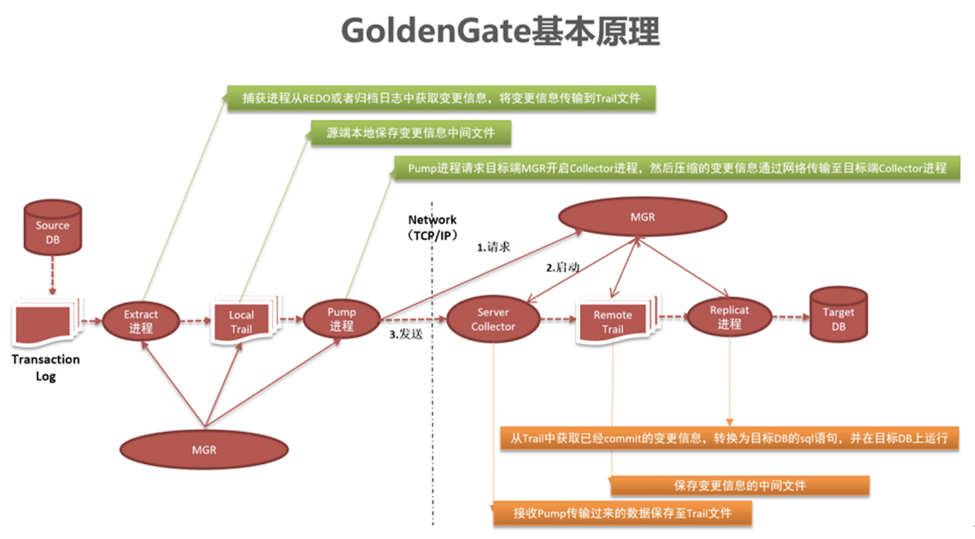
Oracle GoldenGate 数据复制过程如下:
l 利用抽取进程(Extract Process)在源端数据库中读取Online Redo Log或者Archive Log,然后进行解析,只提取其中数据的变化信息,比如DML操作——增、删、改操作
l 将抽取的信息转换为GoldenGate自定义的中间格式存放在队列文件(trail file)中
l 再利用传输进程将队列文件(trail file)通过TCP/IP传送到目标系统。
l 目标端有一个进程叫Server Collector,这个进程接受了从源端传输过来的数据变化信息
l 把信息缓存到GoldenGate 队列文件(trail file)当中,等待目标端的复制进程读取数据。
l GoldenGate 复制进程(replicat process)从队列文件(trail file)中读取数据变化信息,并创建对应的SQL语句,通过数据库的本地接口执行,提交到目标端数据库,提交成功后更新自己的检查点,记录已经完成复制的位置,数据的复制过程最终完成。
1、Extract(提取)
Extract进程被配置为在需要捕获提交的数据库事务的源端点上运行。这个过程是Oracle GoldenGate的提取或数据捕获机制。
可以配置提取过程以从以下类型的数据源捕获数据:
1)、源表(Source tables):此源类型用于初始加载。
2)、Database recovery logs or transaction logs,数据库恢复日志或事务日志:从日志中捕获时,实际方法因数据库类型而异。这种源类型的一个示例是Oracle redo logs。
初始加载:设置OGG初始加载时,Extracts进程会直接从srouce object捕获当前静态数据集合;
更改同步:设置OGG来保持源数据和另一组数据同步时,Extracts进程会在初始同步之后,捕获DML和DDL操作;Extracts会存储这些操作,如果收到rollback,它会放弃该事务的操作,如果收到commit record,就会将事务保存在一系列的trai file中,并排队传输到目标系统;每个事务操作都是按照它们提交到数据库的顺序(commit顺序)写入trail file;这种设计确保了速度和数据的完整性。
2、replicata(复制副本)
Replicat过程将trail files(跟踪文件)中的更新应用到目标数据库。它读取目标数据库上的trail files,重建DML或DDL操作,并将它们应用于目标数据库。
Replicat进程使用动态SQL编译一次SQL语句,然后使用不同的绑定变量执行多次。可以配置Replicat进程,使其在将复制的操作应用于目标数据库之前等待特定的时间。
例如,为了防止错误SQL的传播,控制数据在不同时区的到达,或者为其他计划事件的发生留出时间,可能需要延迟。
对于Oracle GoldenGate的两个常见用例,Replicat的功能如下:
1)、初始加载:为初始加载设置Oracle GoldenGate时,Replicat进程会将静态数据副本应用于目标对象,或将数据路由到高速大容量加载实用程序。
2)、更改同步:当设置Oracle GoldenGate以保持目标数据库与源数据库同步时,Replicat进程会根据数据库类型,使用本机数据库接口或ODBC将源操作应用于目标对象。
可以将多个Replicat进程与一个或多个Extract进程并行配置,以提高吞吐量。为了保持数据的完整性,每组进程处理一组不同的对象。要区分复制副本进程,可以创建具有唯一组名的复制副本组。
3)、数据传输的分发路径
分发路径或DISTPATH定义了端点之间的跟踪文件路径。分发路径是从分发服务配置的。请参阅分发服务了解更多信息。
目标发起的分发路径,也称为接收器路径或RECVPATH,定义了在具有安全目标端点的环境中从接收器服务到分发服务的跟踪路径。
Trail file是Oracle GoldenGate用于存储捕获的更改,形成的一系列文件;用来对database的更改进行连续提取和复制;
在local system,叫做local trail;在remote system,叫做remote trail;
Trail运行extract和replication活动彼此独立放生;比如可以连续提取更改,并存储到trail file中,在目标应用需要时再复制到目标端;
也允许异构的环境中使用trail,数据以一致的格式存储再trail file中,这样replicat可以读取trail file,应用到所有可支持的数据库。
大多数Oracle GoldenGate功能都是通过参数文件中指定的参数来控制的。参数文件是由关联的Oracle GoldenGate进程读取的纯文本文件。
包括;Global runtime parameters,Object-specific parameter(特定参数文件)
当使用database checkpoints时,Oracle GoldenGate会使用Oracle GoldenGate命令在数据库中创建一个具有用户定义名称的检查点表。这些检查点表是为Extract和Replicat进程创建的。对于Extract,在数据源处设置了读取和写入检查点。对于Replicat,检查点是在跟踪文件中设置的。定位中断的位置,下次启动从中断的位置开始恢复。
检查点不仅可以真实地标记 Extract进程捕获的要进行同步的数据变化以及 Replicat进程应用到 target数据库的数据变化,防止进程进行冗余的数据处理,还可以提供容错机制,防止在系统、网络或 Oracle GoldenGate进程需要重启时发生数据丢失。
对于复杂的同步配置,检查点可以确保多个 Extract或Replicat进程从同一组 trail文件中进行读取操作。检查点和进程间的回执机制共同防止了网络间的信息丢失。
以下是个人对于oracle Actiive DataGuard和 GoldenGate的一些理解,限于使用场景和经验的不同,可能不会非常的全面,如有其它不同的想法,欢迎讨论调整补充。
首先从容灾方向来看,个人认为ADG产品更加倾向于结构和数据层面的容灾,是为了保证整个数据库(实例)系统的完整性而设计的,主要目的是为了高可用性(HA);可以说,dataguard是一套数据库系统体系内的容灾解决方案,ADG是在容灾的基础上,加入了可查询的功能,从而能够将一些报表类的业务压力从主库上分离出去,其根本上,还是在一套数据库范围内变相的增加该数据库系统的处理能力。OGG产品,对数据同步的能力支持的更多,它的同步是表级的,不支持在源或目标端的数据聚合操作,如sum,average,count等的数据复制,另外OGG对于DDL复制支持的限制较大,作为容灾,在稳定性和配置上都不如ADG。
从使用场景角度来看,ADG支持一对多的同步,但仅限于一套数据库系统内,无法满足多套数据库之间的有效关联。而OGG产品因为其同步方式的灵活性,可以完美的实在多个数据库之间的互动,OGG支持单向复制、双向复制、点对点复制、数据分发、数据集中、多级复制等多种使用场景,针对表的复制还支持单表到单表、单表到多表、多表到多表、多表到单表、表过滤等多种复制方式,而且OGG可以最大限度的支持异构(操作系统,数据库版本,数据库产品),从而满足复杂业务系统的要求。
从维护和稳定性角度来看,ADG产品维护起来简单,极少出现错误;OGG产品在维护起来操作较为复杂;而且,ADG产品的debug属于oracle体系,在问题处理上,oracle的支持的更好,OGG产品是被oracle收购的,所以在debug方面,对于问题定位和分析都不同于oracle。
下面是一个简单的对比表格;
|
|
Oracle DataGuard |
Oracle GoldenGate |
|
原理 |
复制归档日志或在线日志; (这个存疑,官方文档中提到的是redo data) |
抽取在线日志中的数据变化,转换为GGS自定义的数据格式存放在本地队列或远端队列中; |
|
稳定性 |
作为灾备的稳定性极高 |
稳定性不如DataGuard |
|
维护 |
维护简单,极少出现问题 |
命令行方式,维护较复杂 |
|
对象支持 |
完全支持 |
部分对象需手工创建于维护 |
|
备份端可用性 |
备份端处于恢复或只读状态 |
两端数据库是活动的,备份端可以提供实时的数据查询及报表业务等,从而提高系统整体的业务处理能力,充分利用备份端的计算能力,提升系统整体业务处理性能。可以实现两端数据的同时写入 |
|
接管时间 |
接管时间很短 |
可实现立即接管 |
|
复制方式 |
可以实现实时复制 |
GoldenGate可以提供秒一级的大量数据实时捕捉和投递,异步复制方式,无法实现同步复制 |
|
资源占用 |
复制通过数据库的LGWR进程或ARCN进程完成,占用数据库少量资源 |
业务高峰时在数据抽取转换时消耗系统资源较多,低峰时占用较小 |
|
异构数据库支持 |
单一数据库解决方案,仅运行在Oracle数据库上,源端和目标端操作系统要求较严格,版本号可以不同 |
可以在不同类型和版本的数据库之间进行数据复制。如ORACLE,DB2,SYBASE,SQLSERVER,INFORMIX、Teradata等。适用于不同操作系统如windows、linux、unix、aix等 |
|
带宽占用 |
使用OracleNet传输日志,可通过高级压缩选项进行压缩,压缩比在2-3倍 |
利用TCP/IP传输数据变化,集成数据压缩,提供理论可达到9:1压缩比的数据压缩特性 |
|
拓扑结构 |
可以实现一对多模式 |
可以实现一对一、一对多、多对一、双向复制等多种拓扑结构 |
Oracle RAC使用Oracle Clusterware作为基础架构来绑定多个服务器,使它们像单个系统一样运行。
Oracle Clusterware还管理如Virtual Internet Protocol (VIP) addresses, databases, listeners, services等等;
Oracle Clusterware与Oracle自动存储管理(Oracle ASM)(两者共同构成Oracle Grid Infrastructure)使您能够创建一个群集存储池,供非群集数据库和Oracle RAC数据库的任何组合使用。
在Oracle RAC中,分为Public IP、Private IP、Virtual IP、SCAN IP、GNS VIP及HAIP;
从Oracle 11g开始,安装RAC至少需要7个IP地址,每个节点两块网卡(一块公网网卡,一块私网网卡),其中public、vip和scan都在同一个网段,使用的是公网网卡,private在另一个网段,使用的是私网网卡;
在安装RAC之前,公网、私网共4个IP可以ping通,其它3个IP不能ping通才是正常的。
从Oracle 18c开始,scan建议至少为3个。在安装RAC时,其IP地址的规划类似于下表所示:
各个IP作用:
|
IP类型 |
解释 |
|
Public ip |
Public IP称为公网IP,它是网卡上的真实IP。每个节点在安装Oracle软件之前都需要事先配置Public IP。Oracle通过Public IP对外提供网络服务。 tnsnames.ora文件中写入对应两个节点的Public IP、端口号以及通信协议。 |
|
Private IP |
Private IP称为私网IP或心跳IP,在安装前配置; 私网通信是非常重要的,因为节点和节点之间的通信绝大部分都是要通过私网来实现的。私网通信基本上可以分为两种:第一种是集群层面之间的通信;第二种是数据库实例之间的通信。第一种通信(例如:节点间的网络心跳)的主要特点是持续存在、实时性要求高,但是数据量比较小,所以通过TCP/IP协议传递就可以了。第二种通信是缓存融合(Cache Fusion)造成的实例之间的数据传输,其特点是数据量很大,而且速度要求非常高,TCP/IP协议此时已经不能满足要求了,所以需要使用UDP或者RDS,同时Oracle也一直建议用户对集群的私网进行高可用性和负载均衡的配置。
对于Oracle 10g和11gR1版本的集群,Oracle并不提供私网的高可用性和负载均衡特性,而是建议用户在操作系统层面配置(例如Linux bonding、AIX etherchannel等),从而开启操作系统层面的多网卡绑定技术实现IP Failover。从Oracle 11.2.0.2版本开始推出的HAIP技术提供了私网的高可用性和负载均衡特性,从而替代了操作系统层面的网卡绑定技术,功能更强大更兼容,但是HAIP的bug较多,在云平台上安装rac,一般会禁用掉HAIP。
|
|
Virtual IP(VIP) |
VIP是在Public IP所在的网卡上由Oracle集群软件虚拟出来的一个IP,需要和Public IP设置在同一个子网网段中。在oracle rac安装之前,只需要定义好即可,无需事先配置; 在正常情况下,VIP和Public IP的功能是一模一样的。后台进程PMON对每个节点的VIP所在的监听器注册实例信息,本地监听器中会看到两个地址host,一个是Public IP,一个是VIP。当节点故障时,Oracle集群软件会把VIP自动飘逸到其它节点上,但是本地监听器却没有飘逸到其它节点上。客户端tnsnames.ora文件中host选项不再需要配置Public IP而选择配置VIP,这样做的好处是在双节点RAC架构中当第一个节点故障时,第二个节点会有两个VIP,客户端连接第一个VIP失败后会立即连接第二个VIP对应的实例,整个切换过程是非常短暂的,用户完全感受不到RAC架构中有节点故障。 但是并非真正意义上的透明,用户还是可以知道整个RAC架构是由多少个节点组成,所以,Oracle 11g RAC中推出了SCAN IP的新概念,可以实现对用户连接的透明性,用户不再需要知道整个RAC架构中是由多少个节点组成的。
|
|
SCAN IP |
使用pulic neworker,从Oracle 11gR2 RAC开始引入SCAN(Single Client Access Name,集群的单客户端访问名称)IP的概念,相当于在客户端和数据库之间增加一层虚拟的网络服务层,即是SCAN IP和SCAP IP LISTENER。 在客户端的tnsnames.ora配置文件中,只需要配置SCAN IP,然后用户即可访问数据库,并且实现了负载均衡的功能。客户端通过SCAN IP、SCAN IP LISTENER来负载均衡地连接到RAC数据库。同之前各版本的RAC相比,使用SCAN IP的好处就是,当后台RAC数据库添加、删除节点时,客户端配置信息无需修改。 SCAN提供一个域名来访问RAC,域名可以解析1个到3个(注意,最多3个)SCAN IP,可以通过DNS、GNS或/etc/hosts文件来解析实现。需要注意的是,SCAN IP、VIP和Public IP必须属于同一子网。 |
|
GNS VIP |
GNS VIP是Oracle 11g RAC新特性。在传统RAC架构中,Public IP、Private IP、Virtual IP、SCAN IP都是预先配好的。如果开启了GNS服务只需要预先配置Public IP、Private IP即可,Virtual IP、SCAN IP都是由GNS服务从DHCP服务器动态获取的。配置GNS服务需要事先配置DNS和DHCP服务,GNS VIP可以绑定在任意一个节点的Public网卡上来实现GNS服务,如果没有配置GNS服务就不需要配置GNS VIP。配置起来相对传统架构来说复杂一些,所以,在Oracle 11g RAC架构中很少会看到GNS VIP。12c Flex Cluster架构必须配置GNS VIP。
|
|
HAIP |
在Oracle 11.2.0.2之前,私网的冗余一般是通过在OS上做网卡绑定(如Bond等)来实现的,从Oracle 11.2.0.2版本开始推出HAIP(Highly Available IP)技术替代了操作系统层面的网卡绑定技术,功能更强大、更兼容。HAIP通过其提供的独特的169.254.*网段的IP地址实现集群内部链接的高可用及负载均衡。所以,在11.2.0.2或更高版本安装RAC的时候需要注意169.254.*的IP地址不能被占用。有了HAIP技术则可以不再需要借助任何第三方的冗余技术来实现私网网卡的冗余。
资源ora.cluster_interconnect.haip将会启动一个到四个本地HAIP地址附在Private网络适配器上(私网网卡)。通过HAIP完成Oracle RAC和ASM等内部通讯。如果某一个私有网卡物理损坏,那么该网卡上的HAIP地址会漂移到其它的可用的私有网络上。 HAIP的个数取决于GRID激活的私网网卡的个数。如果只有1块私网网卡,那么GRID将会创建1个HAIP。如果有两块私网网卡,那么GRID将会创建两个HAIP。若超过两块私网网卡则GRID创建4个HAIP。GRID最多支持4块私网网卡,而集群实际上使用的HAIP地址数则取决于集群中最先启动的节点中激活的私网网卡数目。如果选中更多的私网网卡作为Oracle的私有网络,那么多余4个的不能被激活。
|