在DBS-集群列表-更多-连接查询-死锁中,看到9月22日有数据库死锁日志,后排查发现是因为mysql的优化-index merge(索引合并)导致数据库死锁。
index merge(索引合并):该数据库查询优化的一种技术,在mysql 5.1之后进行引入,它可以在多个索引上进行查询,并将结果合并返回。
在排查问题之前,首先讲一下mysql数据库的锁机制:
1 加锁的基本单位是 next-key lock(记录锁+间隙锁),当记录锁或者间隙锁能够解决幻读的问题,就会退化为记录锁(行锁),间隙锁。
2 加锁是将锁加在了索引之上,而不是数据之上。
3 对于当前读,索引进行加锁,当前读语句包括了(select ... from. ... for update,select...from ..... lock in share mode,update...,delete....)。
4 加锁根据唯一性索引、非唯一性索引进行了区分,根据查询条件分为了等值查询、范围查询,根据是否能够查到数据又分为了记录存在和不存在的情况。
本次死锁问题使用的索引是非唯一性索引的等值查询中记录存在的情况,因此本文仅仅详细介绍这种情况,其它情况可以查看最下面的参考文档1:
加锁情况是:会依次扫描,首先扫描到条件匹配的数据,加一个next-key lock,然后接下来扫描到第一个记录不匹配的数据,增加一个间隙锁,最后对查到记录的主键增加一个记录锁,
针对以上情况加了三种锁,加锁的目的是为了防止幻读的发生。
针对二级索引的锁进行分析:
表结构:
CREATE TABLE `jdi_roster_apply_detail` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`apply_id` varchar(100) NOT NULL COMMENT '申请单号',
`status` tinyint(10) NOT NULL COMMENT '状态',
PRIMARY KEY (`id`),
KEY `idx_status` (`status`),
KEY `idx_apply_id` (`apply_id`)
) ENGINE=InnoDB AUTO_INCREMENT=984483 DEFAULT CHARSET=utf8 COMMENT='黑白名单申请单明细'
复制表数据:
| id | apply_id | status |
|---|---|---|
| 959651 | 1695369220522068998 | 1 |
| 960738 | 1695369227576173690 | 1 |
| 961319 | 1695373047673903326 | 1 |
| 961365 | 1695373122447865228 | 1 |
通过 idx_apply_id建立的b+树:
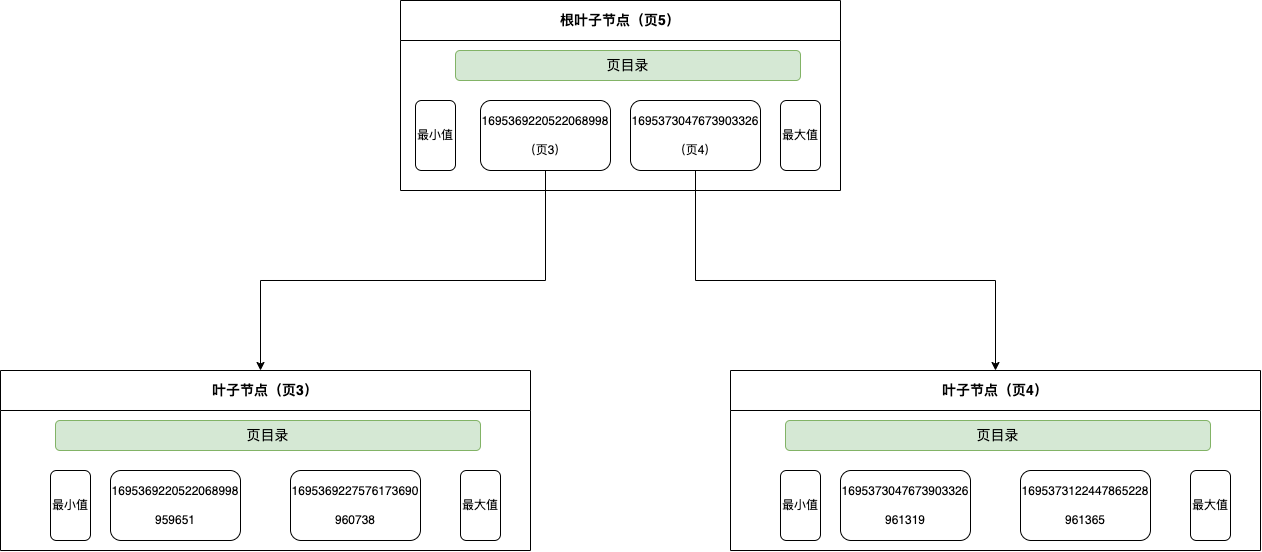
因为索引是二级索引,所以叶子节点存储的数据是主键值。
执行sql:
select * from jdi_roster_apply_detail where apply_id='1695369227576173690' for update
复制执行数据扫描过程
1 查到符合条件的记录,增加next-key 锁,因此锁是(1695369220522068998,1695369227576173690]
2 找到第一个不符合记录的数据增加间隙锁,因此锁是 (1695369227576173690,1695373047673903326)
3 对符合条件的主键索引增加记录锁,因此对 id=960738,增加记录锁。
针对三种锁解决的幻读:
1 如果没有第一条的next-key锁, 另一个事务增加一个apply_id=1695369227576173690, id<960738 时,该事务在进行查询时,会多一条记录,因此会造成幻读。
2 如果没有第二条的 间隙锁,另一个事务增加一个apply_id=1695369227576173690, id>960738是,该事务在进行查询时,会多一条记录,因此会造成幻读。
3 如果没有第三条的记录锁,另一条事务删除一条 id=960738的记录,该事务进行查询时,会少一条数据,因此会造成幻读。
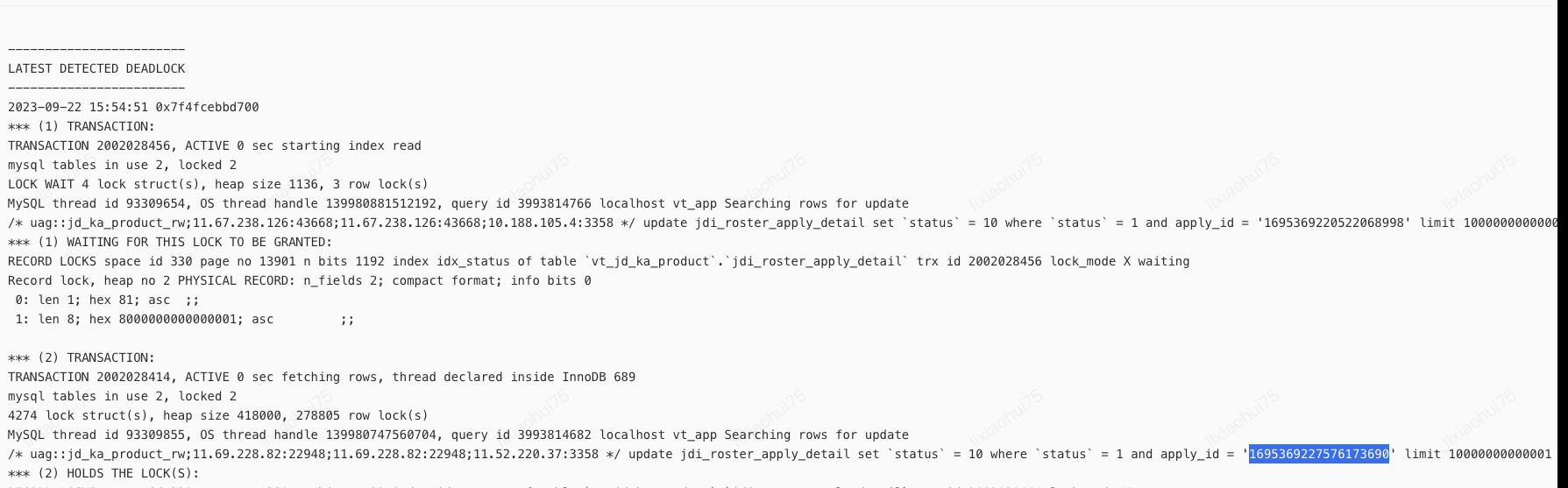
以上日志两个事务分别执行了update语句:
#事务1
update jdi_roster_apply_detail set `status` = 10 where `status` = 1 and apply_id = '1695369220522068998'
#事务2
update jdi_roster_apply_detail set `status` = 10 where `status` = 1 and apply_id = '1695369227576173690'
复制这个sql是用于将某个申请单id待审批的数据改为已审批。
因为在泰山里不能执行update语句 ,因此执行了select语句查看用的索引情况:
explain select * from jdi_roster_apply_detail where `status` = 1 and apply_id = '1695369220522068998'
复制执行的结果:

通过结果可以看出两个update语句都使用了两个索引,分别是idx_status,idx_apply_id,然后将查到的结果进行合并,因此在模拟的过程中,可以将其拆成两个查询语句。
| 事务1 | 事务2 | 锁的范围 |
|---|---|---|
| begin | begin | |
| select * from jdi_roster_apply_detail where apply_id = '1695369220522068998' for update | idx_apply_id所以锁住了(-∞,1695369220522068998],(1695369220522068998,1695369227576173690) 主键id索引锁住了 id=959651 | |
| select * from jdi_roster_apply_detail where apply_id = '1695369227576173690' for update | idx_apply_id所以锁住了(1695369220522068998,1695369227576173690],(1695369227576173690,1695373047673903326) 主键id索引锁住了 id=960738 | |
| select * from jdi_roster_apply_detail where status = 1 for update | 会对idx_status上加next-key锁和间隙锁,但是在对主键959651,960738,961319,961365进行加记录锁时,其中事务2 对960738已经加了记录锁,所以该事务1进行了阻塞。 | |
| select * from jdi_roster_apply_detail where status = 1 for update | 会对idx_status上加next-key锁和间隙锁,但是在对主键959651,960738,961319,961365进行加记录锁时,其中事务1对959651已经加了记录锁,所以该事务2进行了阻塞。 | |
| deadlock |
两个事务分别想要两个主键id的记录锁,造成相互等待,形成了死锁。
以上是先执行idx_apply_id的索引查询再执行idx_status索引查询,如果先执行idx_status索引查询,再执行idx_apply_id的索引查询,也会因为主键的记录锁造成死锁。
1 利用force index(idx_apply_id)强制走某个索引,这样InnoDB就会忽略index merge,避免多个索引同时加锁的情况。
2 禁用Index Merge,用命令禁用Index Merge:SET GLOBAL optimizer_switch='index_merge=off,index_merge_union=off,index_merge_sort_union=off,index_merge_intersection=off';
3 Index Merge同时使用了2个独立索引,因此新建一个包含这两个索引所有字段的联合索引,这样InnoDB就只会走这个单独的联合索引。
第三种方案相较于第一种查询性能更好,相对于第二种仅仅作用于该表,影响范围小,因此本次也是采用了该方案。
该死锁问题是因为优化器使用了合并索引问题导致的,最终通过新建一个联合索引来解决这个问题。
参考文档:
1 https://www.xiaolincoding.com/mysql/lock/how_to_lock.html
作者:京东工业 李小辉
来源:京东云开发者社区 转载请注明来源