本文译自Why I encountered Go memory fragmentation? How did I resolve it?,作者通过分析golang的堆管理方式,解决了内存碎片的问题。
我们的团队正在搭建运行一个兼容Prometheus的内存时序数据库,该数据库有一个数据结构,称为"chunk"。每个chunk对应一个唯一键值标签对的4个小时的数据点,如:
{host="host1", env="production"}
复制可以将一个数据点认为是一个时间戳加数值的组合,一个chunk包含了4个小时的数据点。数据库同一时间只会保存每个(唯一标签对的)指标的8个chunk,且每4小时会对老的chunk进行清除。由于它是一个内存数据库,因此使用快照恢复逻辑来防止数据丢失。
通过观察内存使用发现,在数据库启动32~36小时之后,内存使用一直在增加:

一开始怀疑是内存泄露问题,因此通过每小时采集heap profile来对比内存使用差异,但此时并没有发现任何异常。一开始怀疑可能是chunks没有完全释放,如果长期持有未使用的对象,可能会导致该问题,但通过pprof并没有找到相关线索。
为什么使用的内存在增加,但总的堆使用却保持不变?
通过如下go memstats指标发现可能出现了内存碎片:
go_memstats_heap_inuse_bytes{…} - go_memstats_heap_alloc_bytes{…}复制

指标结果显示,堆申请的字节数要少于使用的字节数。这意味着有很多申请的空间没有被有效地利用。通常在chunks过期前的4小时内,该值会增加,但之后会逐步降低。然而在出问题的节点上,该值并没有降低。
我怀疑它可以为非重启节点使用过期的空间来处理新摄取的数据,但是由于内存碎片而不能为重启过的节点使用过期的空间(即使用恢复逻辑读取快照)。
之后我将怀疑点转向了快照的恢复逻辑。快照实际上由chunks的字节构成,并放在文件中。在处理过程中会并行写chunk,因此chunk的顺序是随机的,这样可以提高写性能,而读操作则是从文件头按顺序读取的。因此可以想象,每4个小时,当某些零散chunk过期时,就会导致大量内存碎片。

下面是尝试的解决方式,即在将chunk写入文件之前会按照chunk的时间戳进行排序,这样就可以按照时间顺序来申请字节(恢复期间会从头部读取字节并分配内存),下面是修复后的申请方式:

经验证发现,问题并没有解决,且写操作性能严重降级。
至此需要理解Go是如何进行堆管理的。参考golang-memory-allocation。

简单地说,Go运行时管理着大量mspans,每个mspans包含特定数目的连续8KB内存页,不同msapns有着不同的size class(大小),size class决定了mspan中的对象的大小,用于适应不同大小的对象,降低内存浪费。
假设要申请100字节的对象,则需要选择112字节的size class(参见列表)。
通常每个chunk都有一个用于内部数据的字节数组,其创建方式为:
make([]byte, 0, 128)
复制Go中slice的大小并不是固定不变的,当slice的容量小于1024时会以2的倍数增加,当容量大于1024时,新slice的容量会变为原来的1.25倍。(本文对这部分描述有误,此处纠正),在本场景中,大部分size-classes是固定的:

而目前恢复使用的chunk的为:
make([]byte, 0, actual chunk byte size)
复制这意味着摄取时采用的chunk size classes与恢复是采用的chunk size classes完全不同!恢复时使用未对齐mspan的实际chunk大小来保存数据,导致过期内存重复利用率不高,也导致mspan中出现了大量内存碎片:
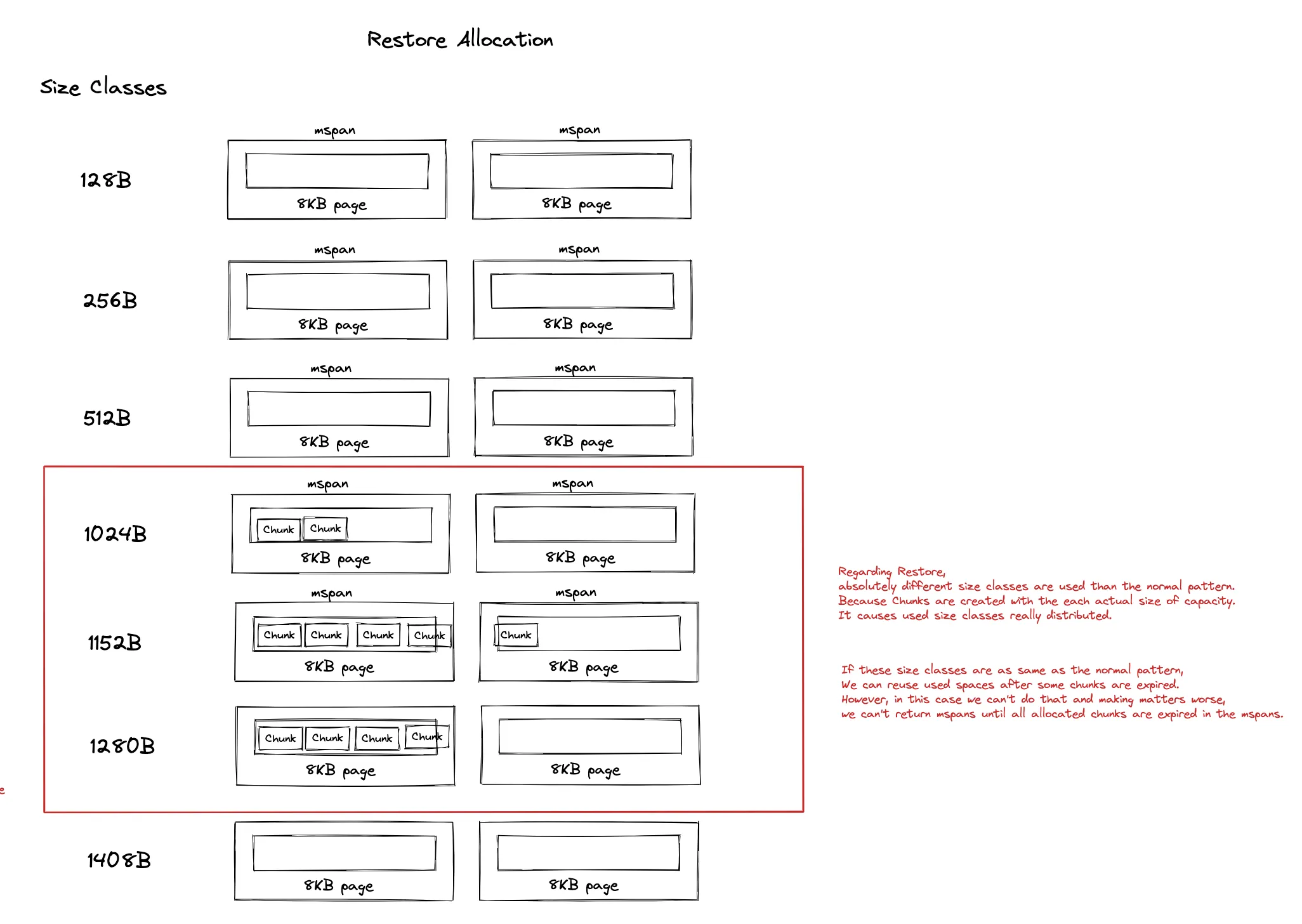
最后作者,通过如下方式解决了该问题:
通过如上两种方式解决了该问题:

这里解释一下文中涉及的mstat的2个指标,更多参见Exploring Prometheus Go client metrics:
- go_memstats_heap_alloc_bytes:为对象申请的堆内存,单位字节。该指标计算了所有GC没有释放的所有堆对象(可达的对象和不可达的对象)
- go_memstats_heap_inuse_bytes: in-use span中的字节数。go_memstats_heap_inuse_bytes-go_memstats_heap_alloc_bytes表示那些已申请但没有使用的堆内存。