Rendezvous hashing用于解决分布式系统中的分布式哈希问题,该问题包括三部分:
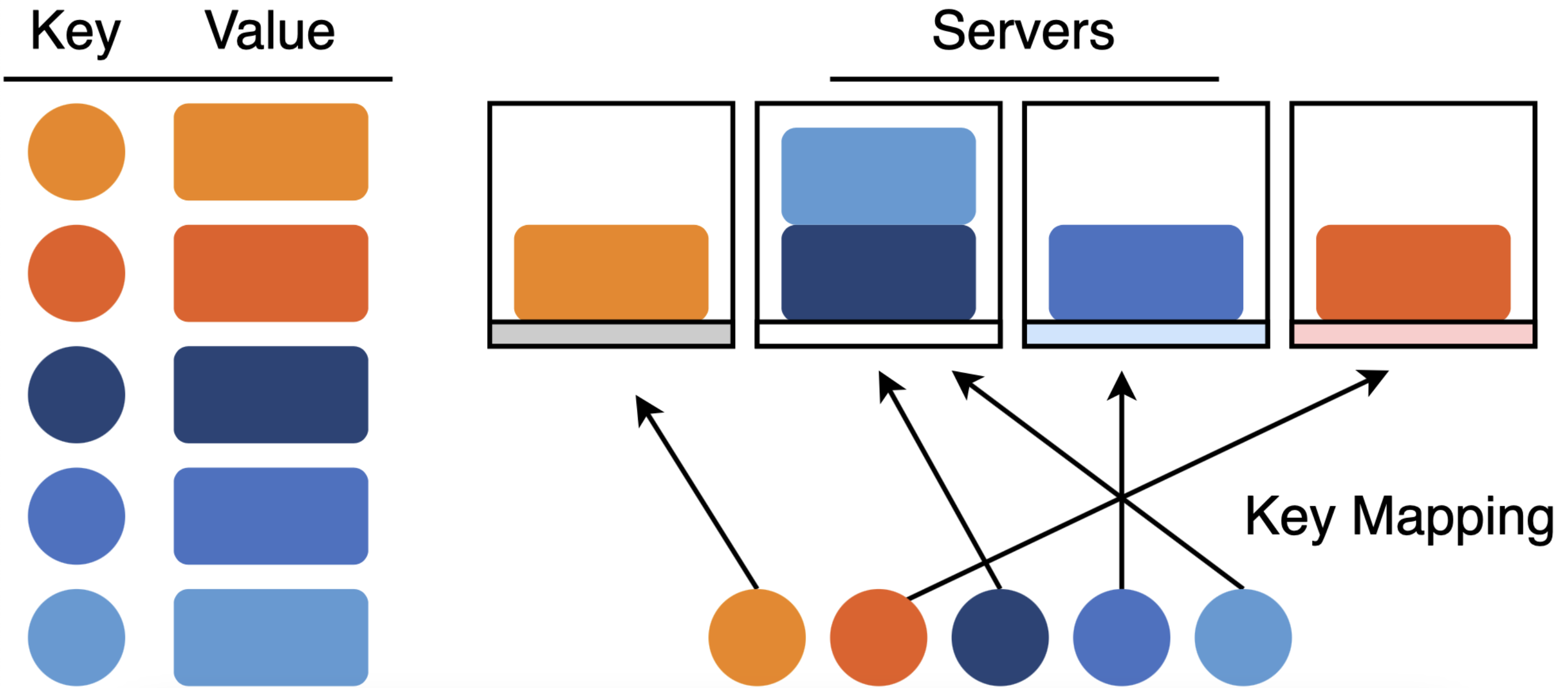
例如,在一个分布式系统中,key可能是一个文件名,value是文件数据,servers是连接网络的数据服务器,用于保存所有文件。假设给定一组动态服务器,下面需要将keys映射到服务器,并提供如下功能:
动态服务器是指在系统运行的任意时间都可能会添加或删除服务器。
Rendezvous Hashing算法的历史可以参见原文。
rendezvous hashing算法的目的是获得更好的负载均衡性能。我们希望每个服务器都能负责同等数量的key-value。一种合理的方式是和普通的哈希表一样,让每个key都随机均匀地选择一个服务器。这样做的原因是,如果只是对服务器ID进行哈希,那么当修改服务器的数量时,所有的哈希值都会发生变化。当对目标服务器的选择和服务器的数量没有直接关系时,就可以避免服务器的增删带来的影响。
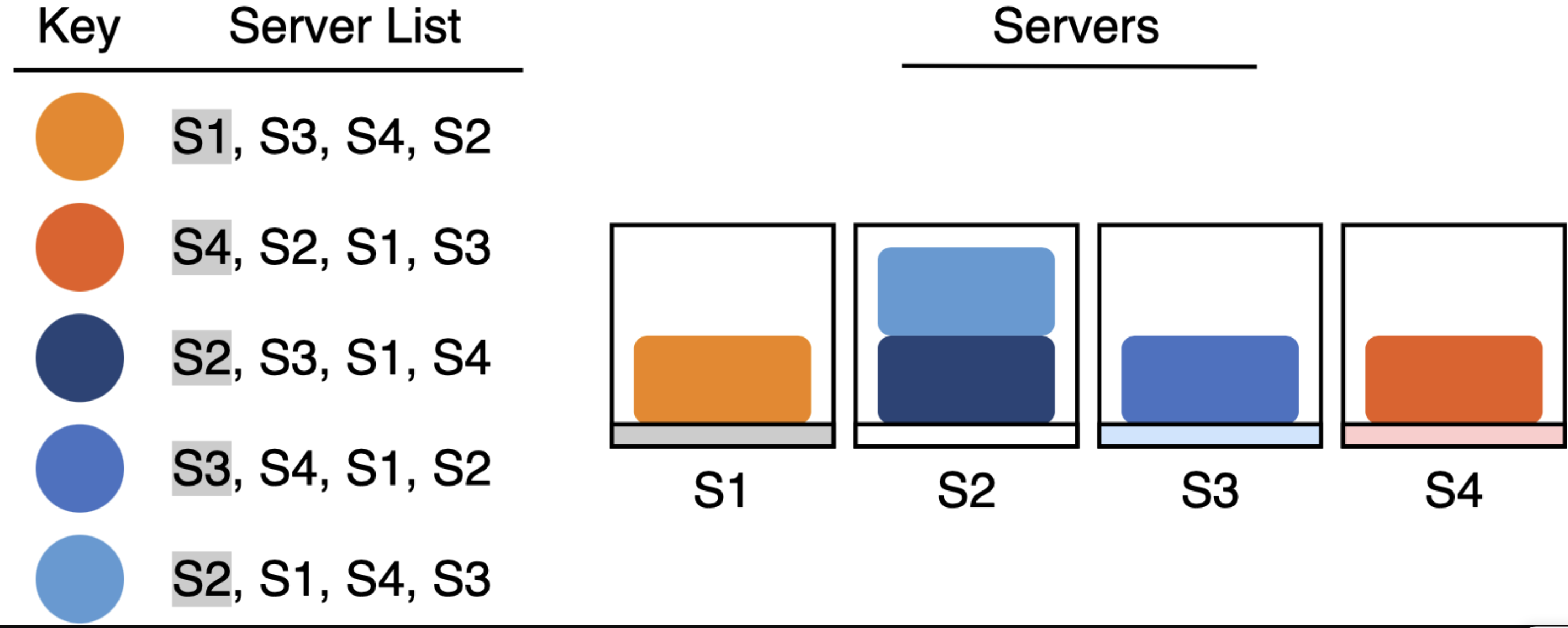
Rendezvous hashing提供了一种聪明的解决方式。相比于选择一个特定的服务器,它会为每个key生成一个随机有序的服务器列表,并选择列表中的第一个作为目标服务器。为了保证查找成功,我们需要保证每个key-value对都由key选择的第一台服务器保管。
如果选择的第一台服务器下线时,只需要将key转移到列表中的第二台服务器即可(作为新的第一台服务器)。可以看出,这种情况下只需要转移下线的服务器上的keys即可,无需变动其他服务器的keys。如下面例子,当删除S2服务器时,S2中的数据会转移到新的第一台服务器:即S1和S3,其他服务器的数据无需变动(S2不是它们的第一台服务器)。
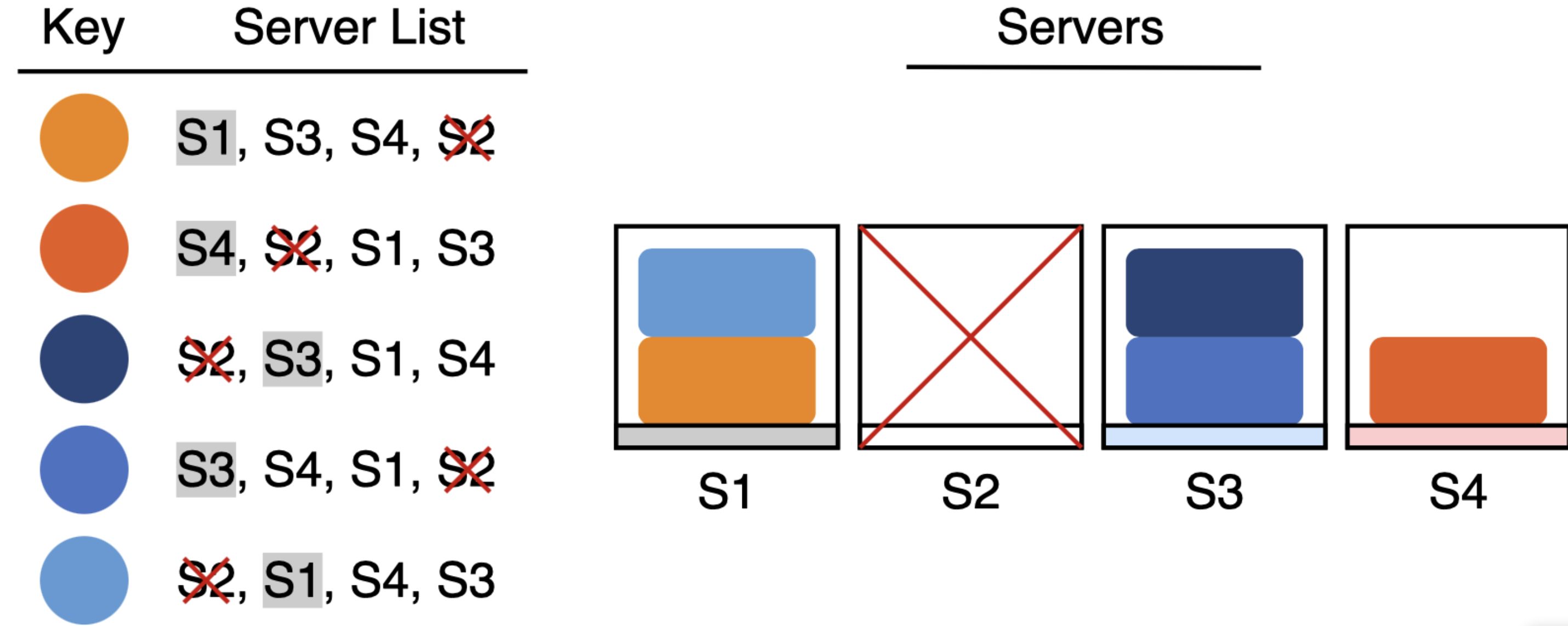
从上面例子可以看出,使用rendezvous hashing时,需要确保每个key都能有其特定的服务器优先列表,这样才能保证数据分布均匀。那如何为每个key生成随机排列的服务器列表呢?
可以使用常见的哈希技术来解决该问题。首先,对每个服务器进行哈希来生成一组整数哈希值,然后基于该哈希值对服务器进行排序,这样就得到了一个随机排列的服务器列表。为了保证每个key都能得到唯一的排列,需要在哈希函数中引入key。方式是将key和各个服务器(或服务器ID)作为哈希种子来生成哈希值。
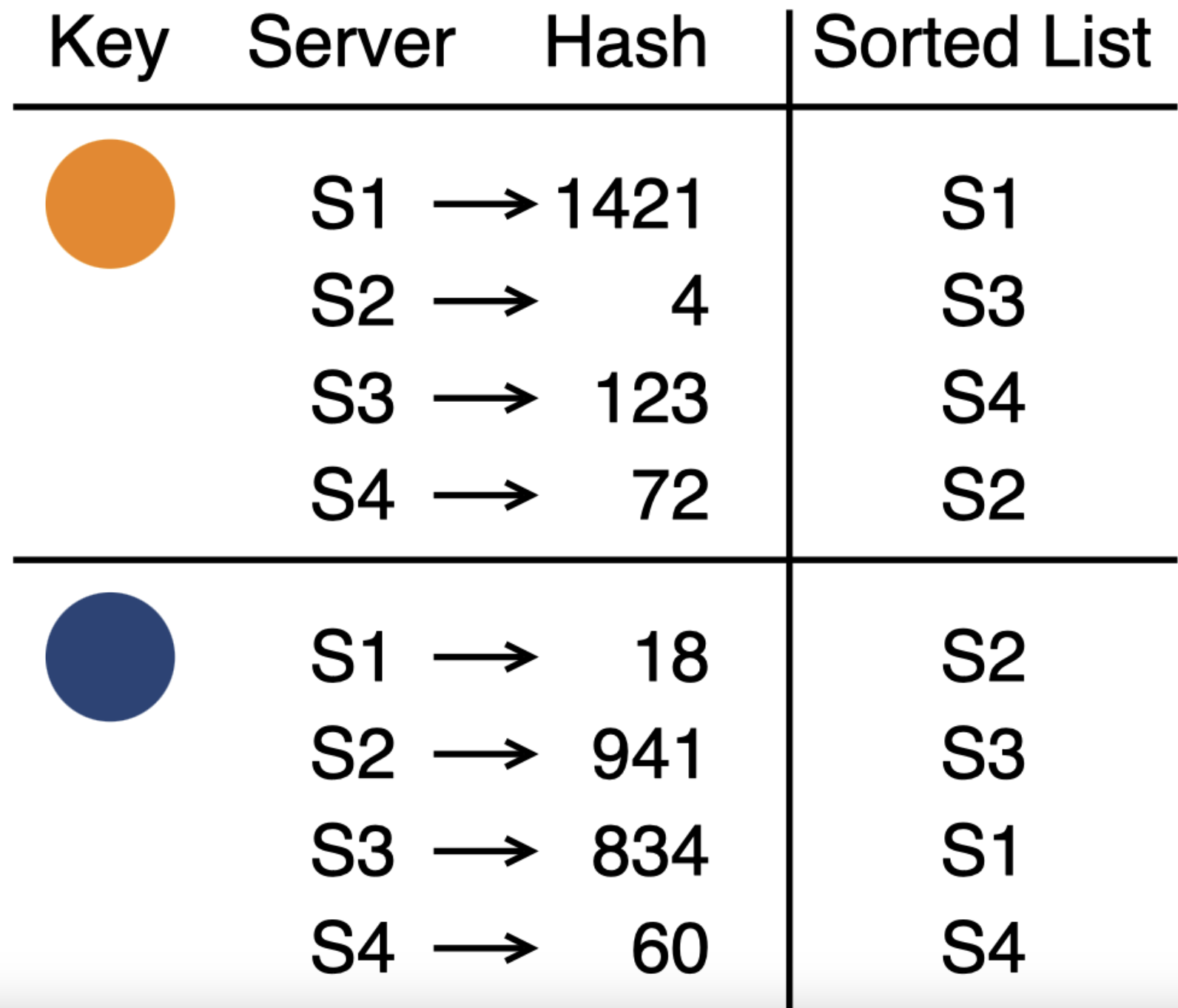
最终的rendezvous hashing算法为:
级联故障转移:当一台服务器故障后,很多负载均衡算法会将所有负载转移到某一台服务器上,如果该故障转移的服务器无法处理新的负载,就会导致级联故障。在Rendezvous Hashing中,由于每个key都有不同的第二选择服务器,因此Rendezvous hashing可以避免该问题。使用好的哈希函数可以将负载从故障服务器均匀分布到剩余的服务器上。
基于权重的服务器:在一些场景下,我们期望基于负载均衡而非均匀随机key来分配负载。例如,需要给具有较大容量的服务器分配更多的负载。相比基于哈希值的排序,我们可以选择基于 $$ {w_i \over ln h_i(x)} $$进行排序,其中x为key, \(w_i\)为服务器i的权重, \(h_i(x)\)为哈希值(通常为[0,1])。更多细节,参见这里。
更少的内存:由于可以本地计算所有的哈希函数值,因此只需要一组服务器ID列表来对应管理key-value的服务器。在实际使用中,一致性哈希之类的算法要求更多的内存(但计算量也更少)。
添加服务器:在添加服务器时,由于新的服务器可能会成为系统中已存在的key的第一选择,因此很难维护"第一选择"不变性。为了维护该不变性,我们需要校验系统中服务器管理的所有keys,这会给分布式存储和pub/sub系统带来严重的问题,但着对缓存系统来说并不是一个问题。在缓存系统中,缓存服务器会共享一个中央数据存储库。当用户请求缓存系统时,如果缓存不存在,则从中央库中获取数据并缓存起来,等待下次使用。
当给缓存添加服务器时,系统会最终达成"第一选择"不变性。如果添加的服务器成为一个已存在的key的第一选择,则只会在第一次请求时会导致缓存miss。在新服务器负责该key之后,老的服务器将不会再接收到该key的请求,老数据最终会通过LRU之类的方式清理掉。
请求时间:如果有N台服务器,由于需要校验所有的key-server组合,因此查找算法为O(N)。而一致性哈希为O(logN),当N足够大时,其查询速度也更快。
Rendezvous hashing适于在中小型分布式缓存中做分布式负载均衡。如果一个系统无法满足"第一选择"不变性,则需要谨慎选择rendezvous hashing。