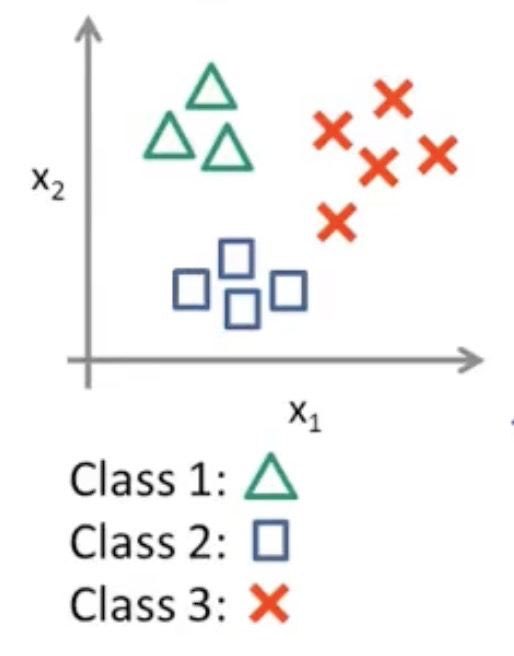
给算法一个数据集,其中包含了正确的答案,告诉算法啥是对的啥是错的
我们想要在监督学习中,对于数据集中的每个样本,我们想要算法预测,并得出正确答案
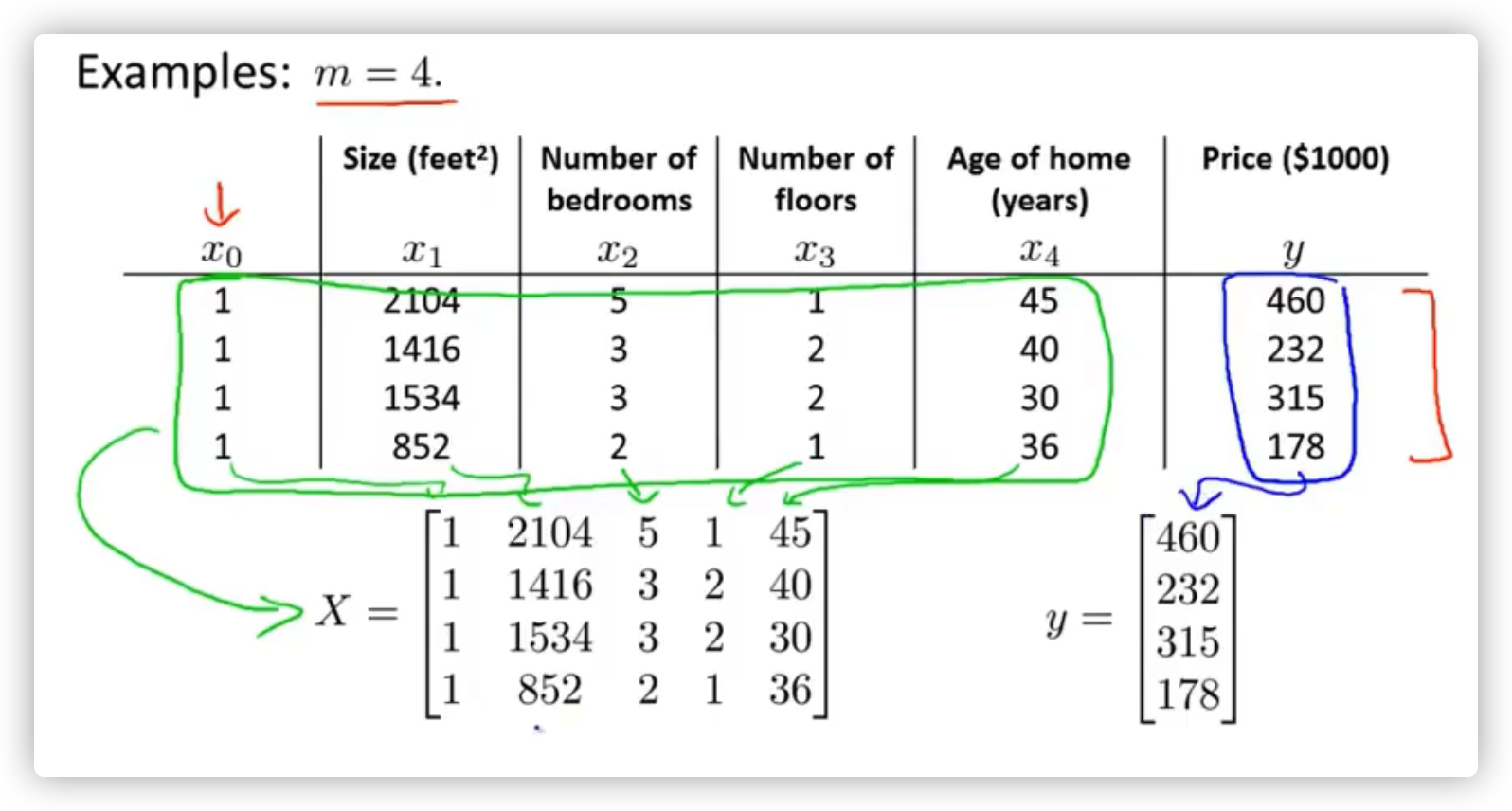
给定的数据集为一一对应的数据集,一个x对应一个y,例:一元一次方程
一个算法h(x)给定一个输入值x,能给出一个确定的输出值y,称之为单函数(元)线性回归。
经过单元代价函数的形式,很容易得出多元代价函数如下所示,其中的 \(\Theta\) 是上述中的向量,其中拥有多个参数
\(J(\Theta)=\frac{1}{2m}\sum\limits_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2\)
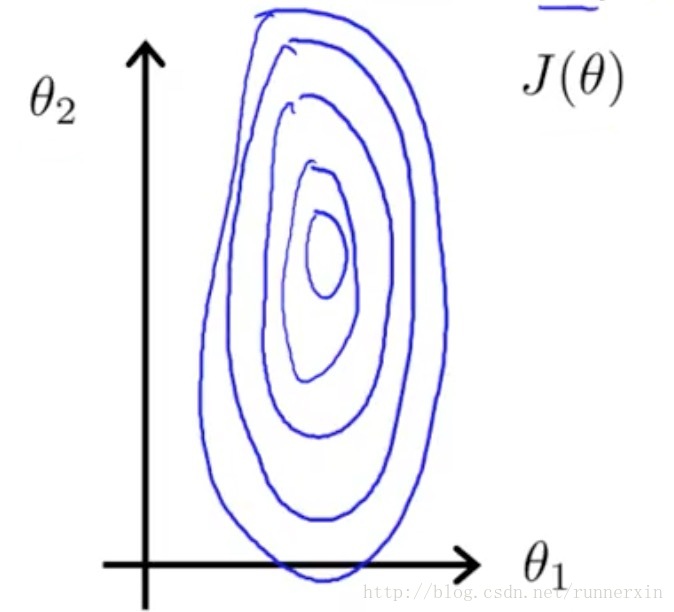
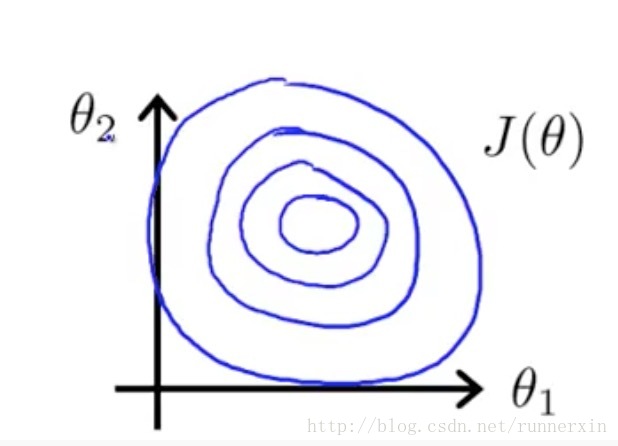
| 梯度下降法 | 正规方程 |
|---|---|
| 缺点:需要选择一个合适的 \(\alpha\) | 优点:无需选择合适的 \(\alpha\) ,一步即可得出 \(\theta\) 值 |
| 缺点:需要进行多次迭代 | 优点:无需进行多次迭代 |
| 优点:在特征向量特别大的时候,仍然可以很好的进行工作,例如特征向量维度大于10000的时候 | 缺点:当特征向量维度特别大的时候,则运行起来会非常慢,当有n个特征值的时候,求 \((X^TX)^{-1}\) 的时候可能需要的运行时间为n的立方次数甚至更多 |
| 时间复杂度:\(O(kn^2)\) | 时间复杂度:\(O(n^3)\) |
目的是预测离散值的输出
例如判断是否中彩票了,是用1,否用0来代表
也就是 \(y\in\left \{ 0, 1\right \}\)
其中的 0 代表负类,1代表正类,此处的负和正可以是良性肿瘤恶性肿瘤,或者上面提到的是否中彩票等
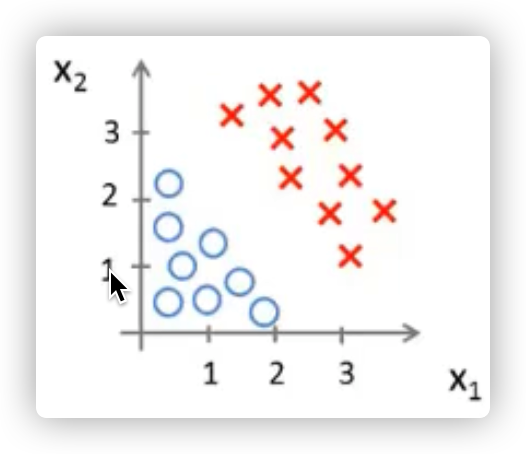
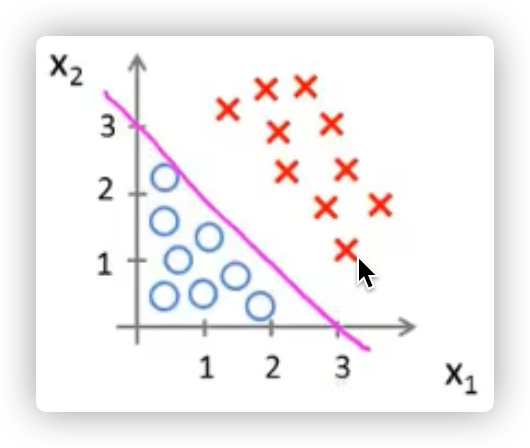
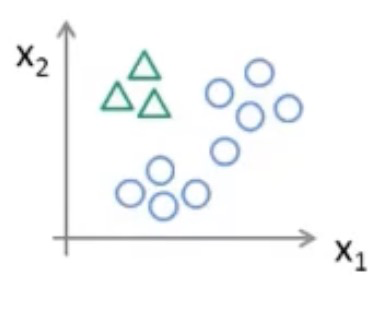
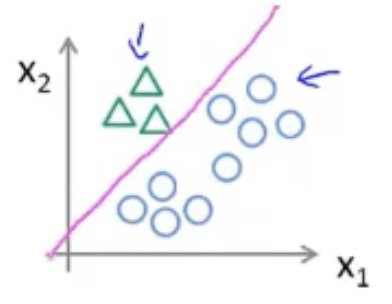
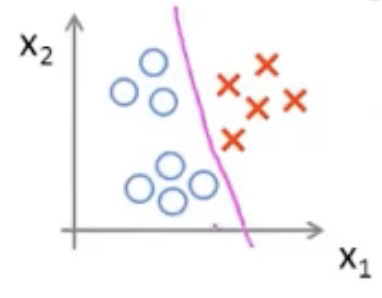
我们可以来看一下用线性回归的思想能否适用于分类问题
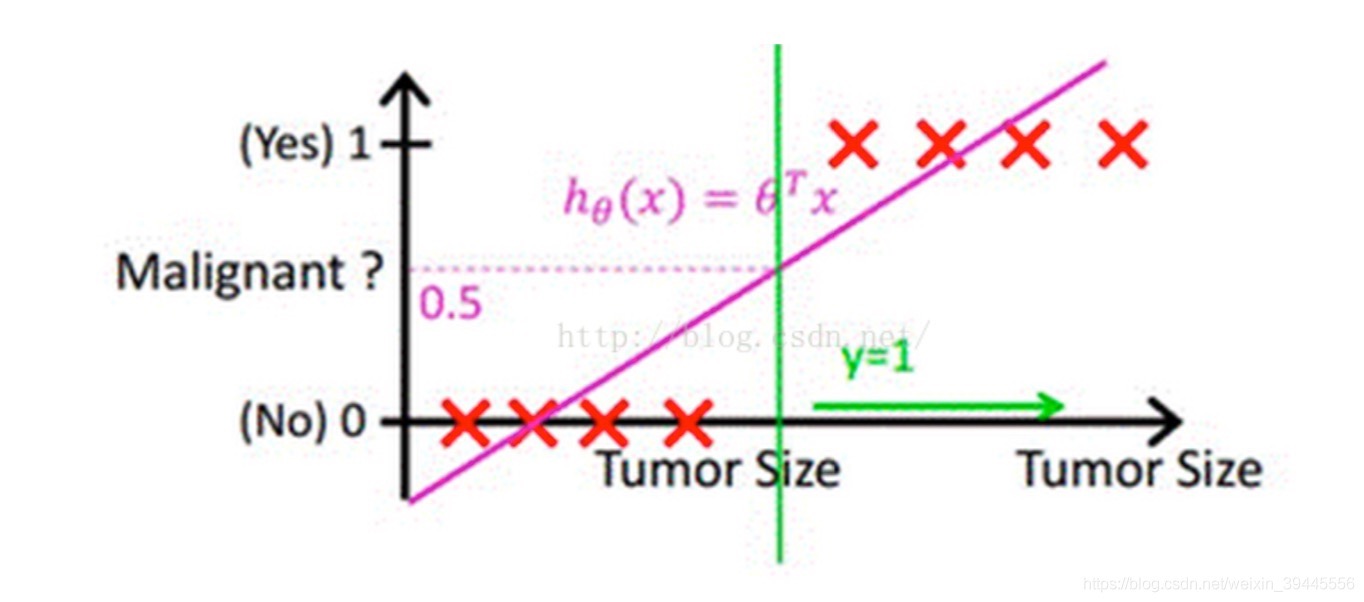
在上图中可看到,红色的x轴为肿瘤大小,粉色的线为线性回归的假设函数图像。
发现我们只需要在假设函数等于0.5处加一根竖线(绿色的线),就可以成功的将这里的回归问题转化成了分类问题,肿瘤大小在绿线左边的都是良性的,在右边的则都是恶性的
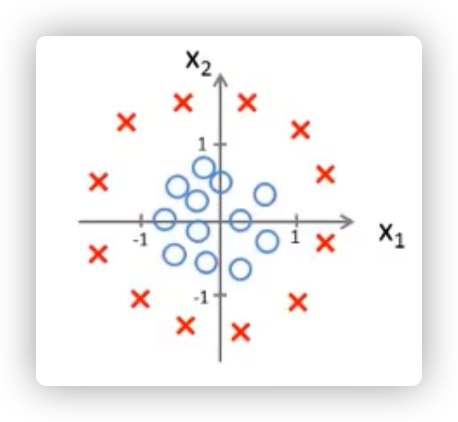
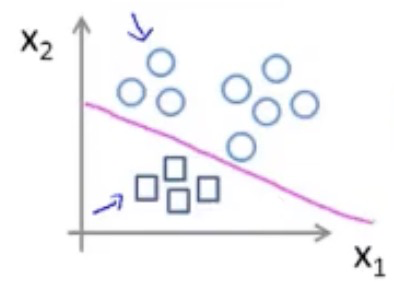
这样看样子,好像线性回归的假设函数可以直接运用到分类问题里,但是如果出现了下图情况呢
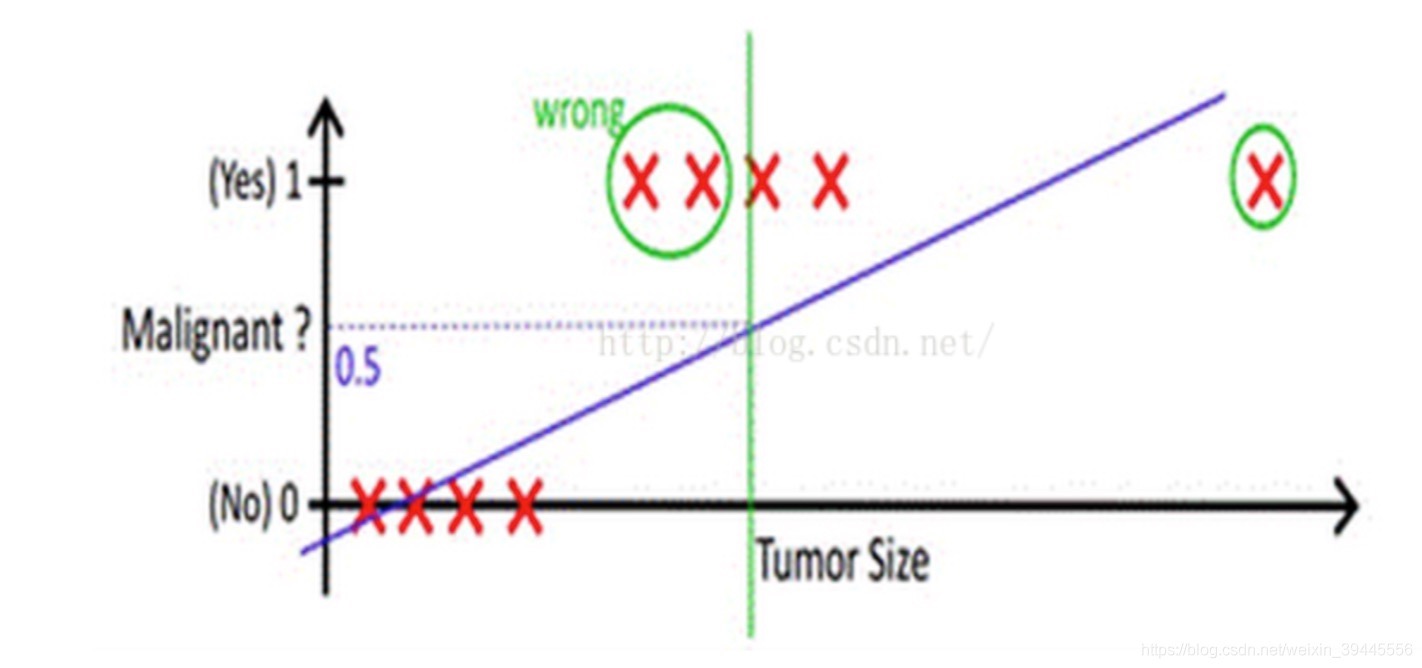
可以看到,在右方出现了一个巨大的肿瘤,导致我们的假设函数因为这个异常值的影响,预测的不再准确
究其原因是因为我们线性回归的假设函数太直了,所以我们需要找出一个不那么直的函数
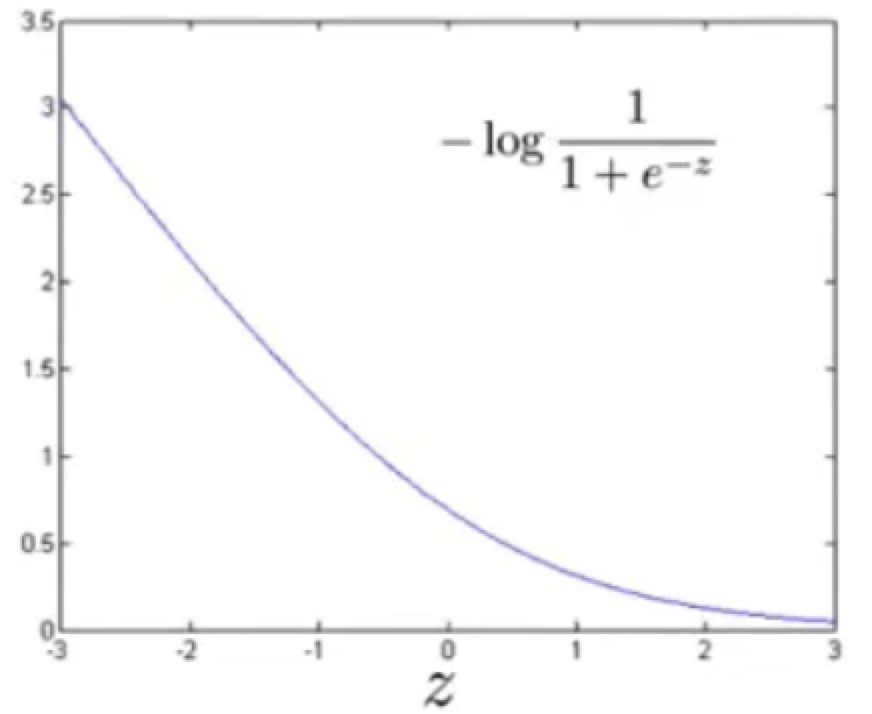
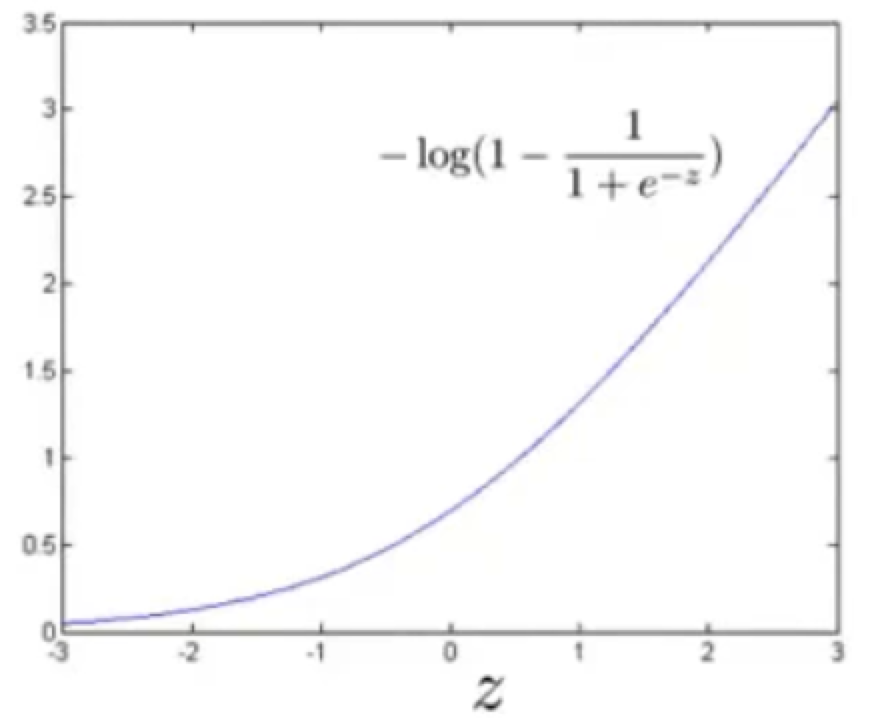
这个新函数就是 \(g(z)=\frac{1}{1+e^{-z}}\)
这个函数,叫logistic函数(逻辑),也叫Sigmoid函数
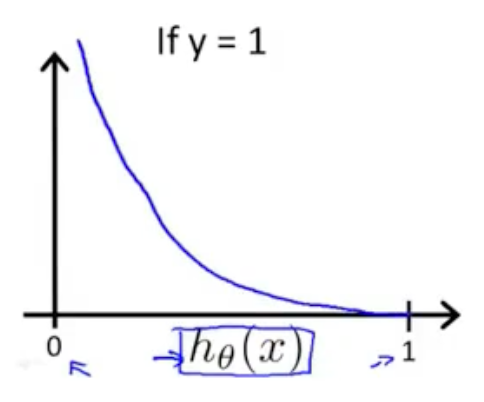
为什么选它作为假设函数,我们来看一下它的图像就知道了
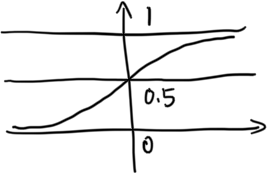
发现这个函数将输入范围(负无穷到正无穷)映射到了输出范围(0,1),很具有概率意义
啥叫很具有概率意义,就是相当于我们将中彩票的样本输入到这个函数中,假如函数输出了0.7,就表示有70%的可能中彩票,相应的,也就有30%到可能不中彩票
那逻辑回归到假设函数参数从哪里设置呢?我们来看一下线性回归的假设函数:\(h_\theta(x)=\Theta^TX\)
线性回归的参数输入就是 \(\Theta^TX\)
而逻辑回归的假设函数则有一点不一样:\(h_\theta(x)=g(\Theta^TX)\)
其中的 \(\Theta^TX\) 我们用z来代替,再套用sigmoid函数,则 \(g(\Theta^TX)=g(z)=\frac{1}{1+e^{-z}}\)
我们再将刚刚那两个公式给组合一下,就可以得出正式的假设函数为:\(h_\theta(x)=\frac{1}{1+e^{-\Theta^TX}}\)
有了这个假设函数之后,接下来就和线性回归一样了,同样是找到一个合适的 \(\theta\) 值,来使得我们的假设函数最大程度的拟合我们给定的数据集





从例子来讲比较好
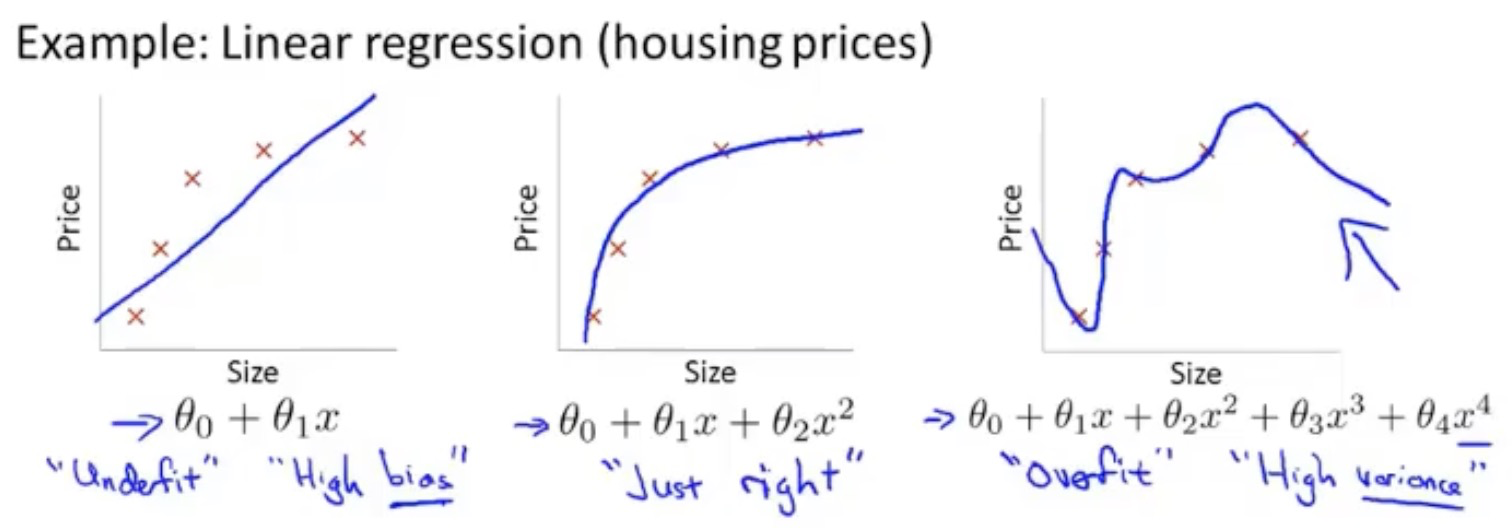
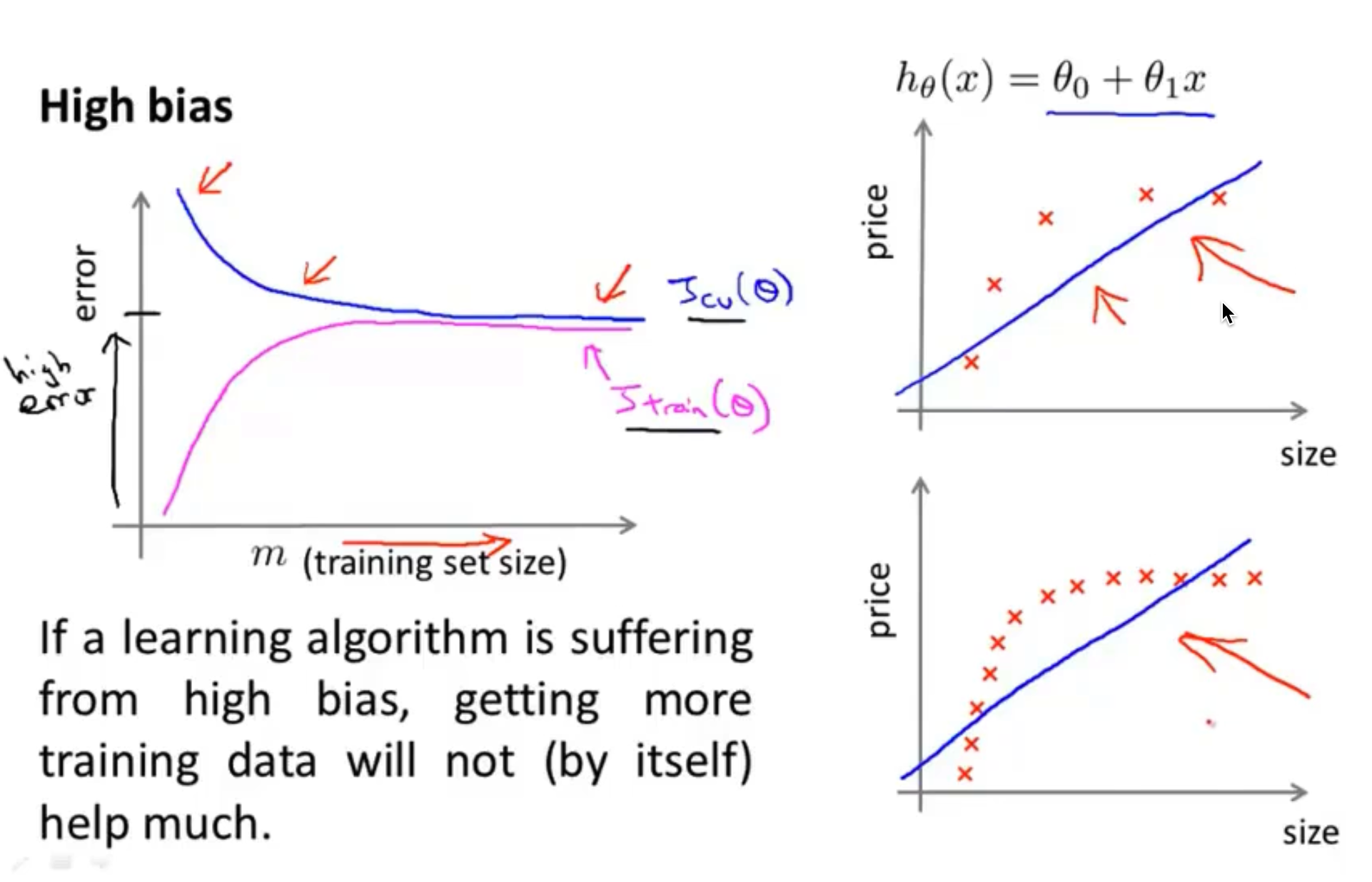
第一个属于欠拟合
第二个就拟合的比较好
第三个属于过拟合
如何优化过拟合问题
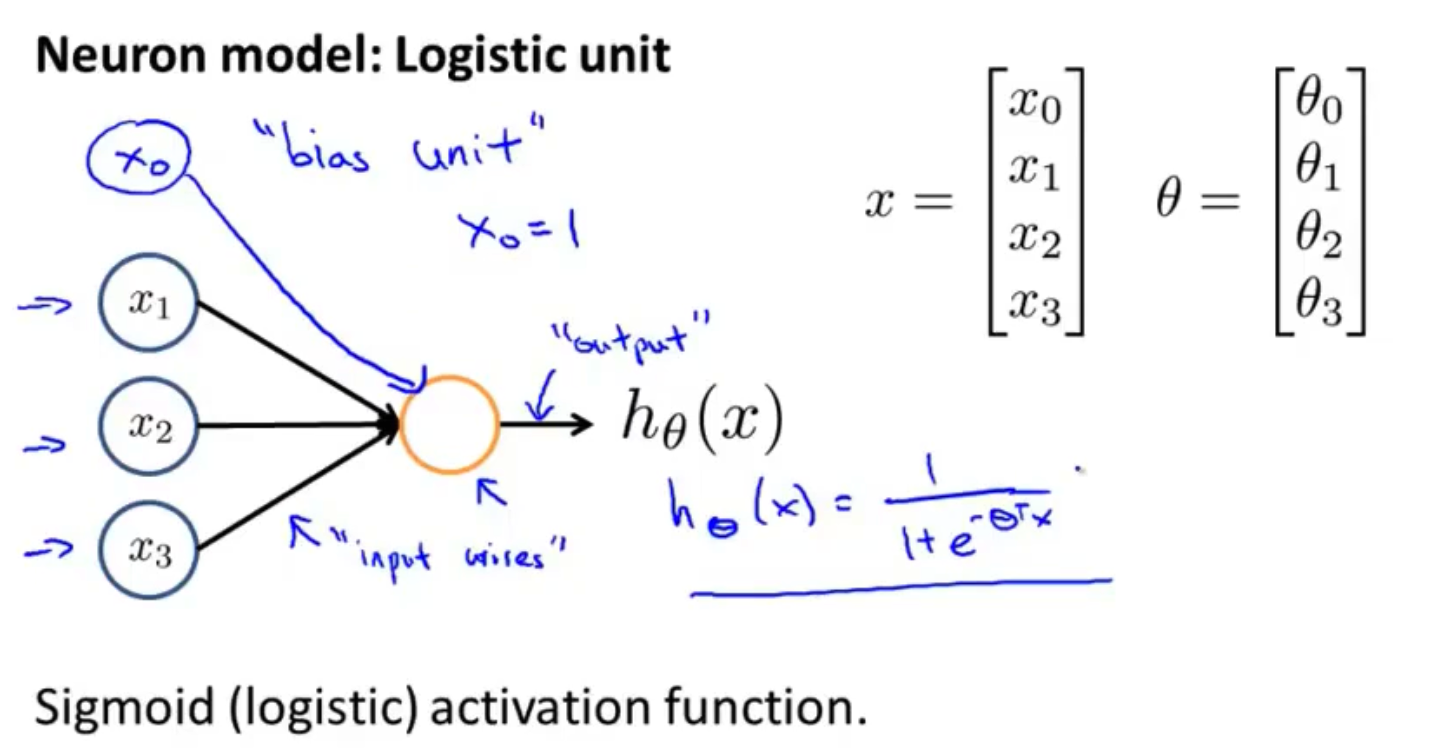
神经网络是由多个神经元所构成的,如下图所示
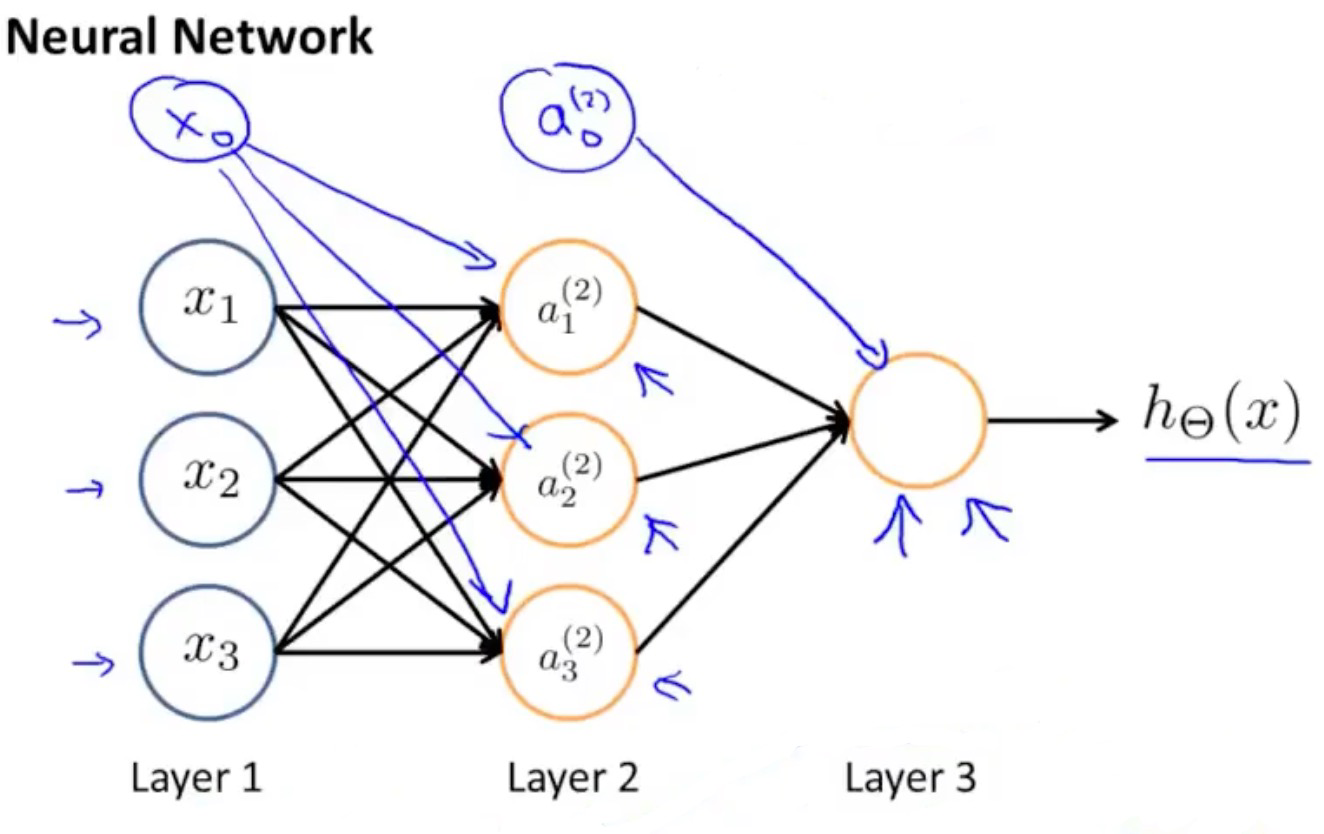
其中的层一为输入层,层二为隐藏层,层三为输出层
为什么叫隐藏层?
既然隐藏层的值在训练集看不到,可以通过以下计算出隐藏层的值
如果只有一层的神经网络,就有点类似于分类任务里的逻辑回归,如图所示
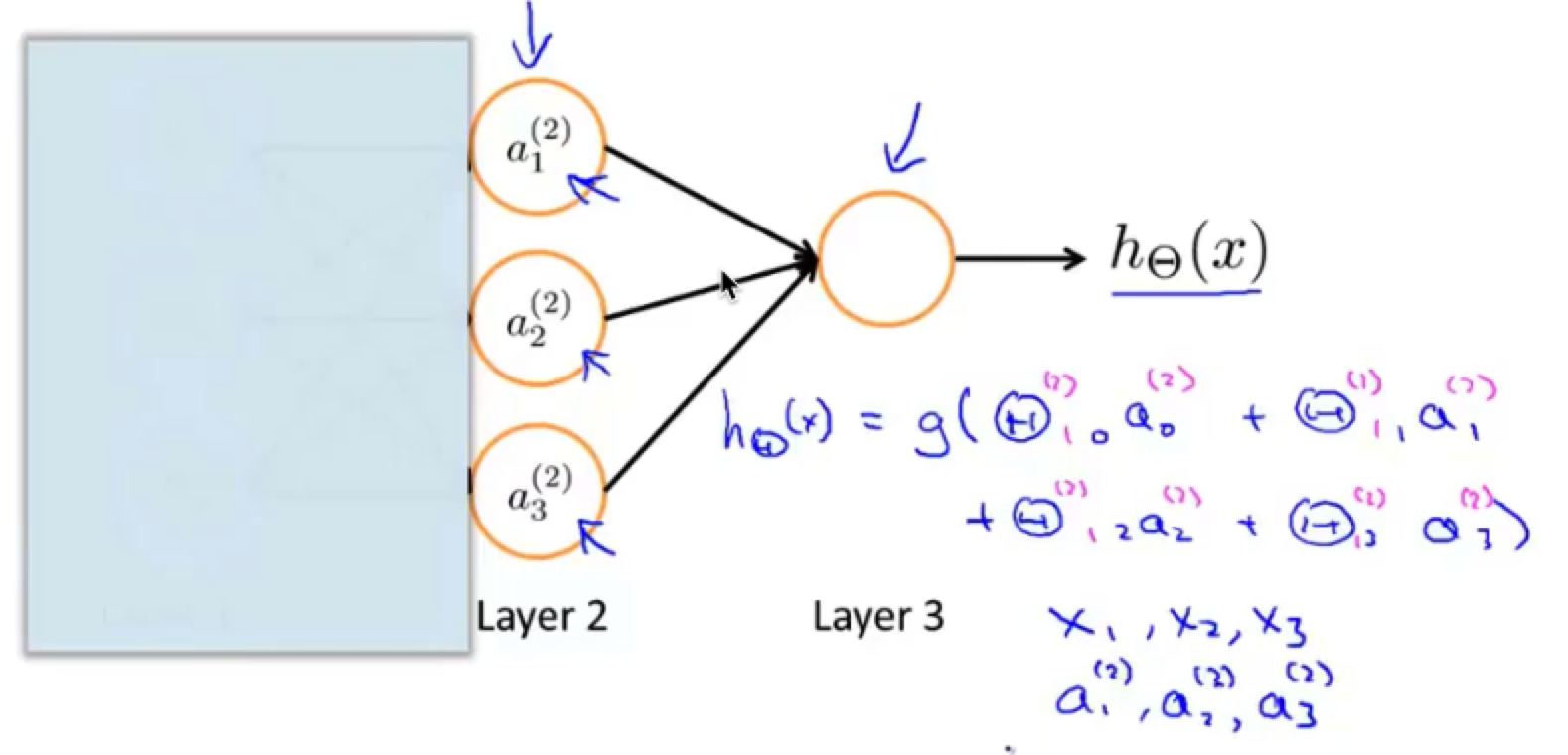
因为输入值就是我们的a1 - a3,没有隐藏层,所以也就只有一个计算层,也就是最后的输出h(x)
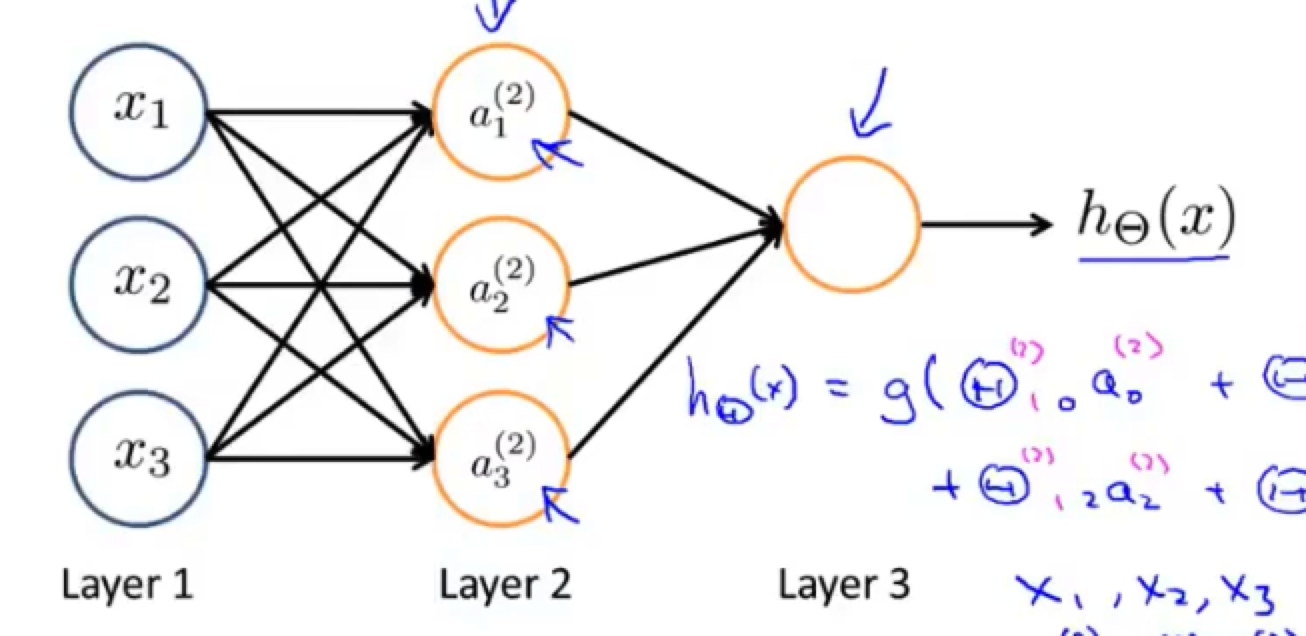
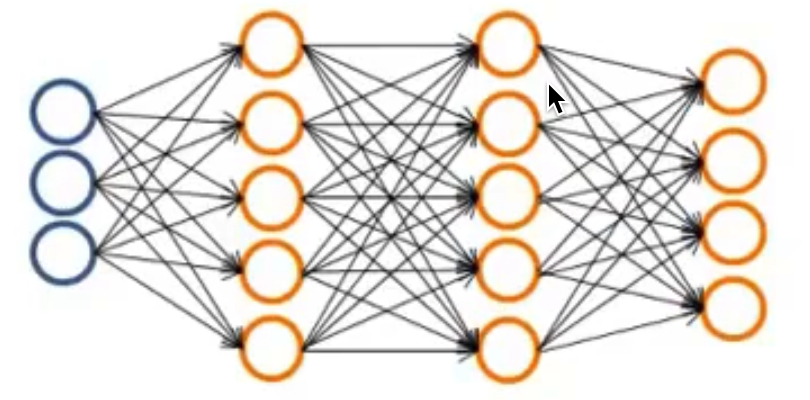
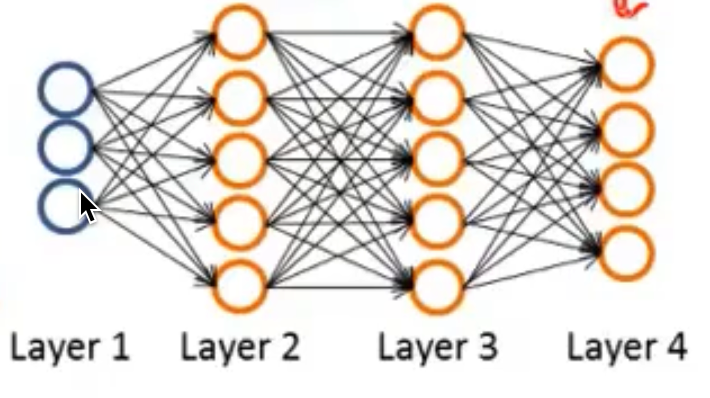
而超过了两层的神经网络则就和逻辑回归不太一样了,因为他有了两个计算层,也就是上图的层2和层3
我们最终输出的层3是由隐藏层2计算得来的,而隐藏层又是由输入层1计算而来的
也就是说,逻辑回归的特征值是从训练集中直接获得的,而这里的神经网络,则是先从训练集中获取特征值,然后再对原始特征值进行学习,从而得到一个更好的特征值,再用该特征值当参数来进行预测
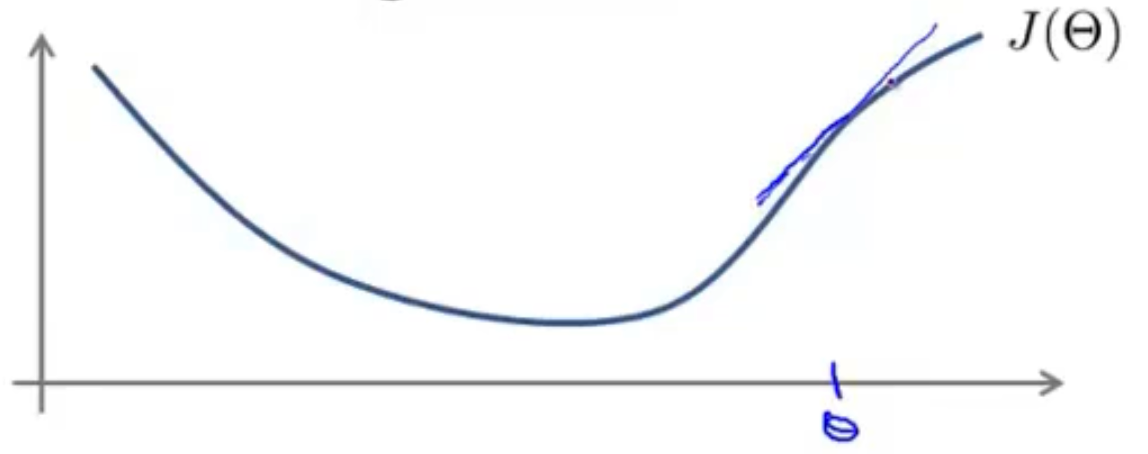
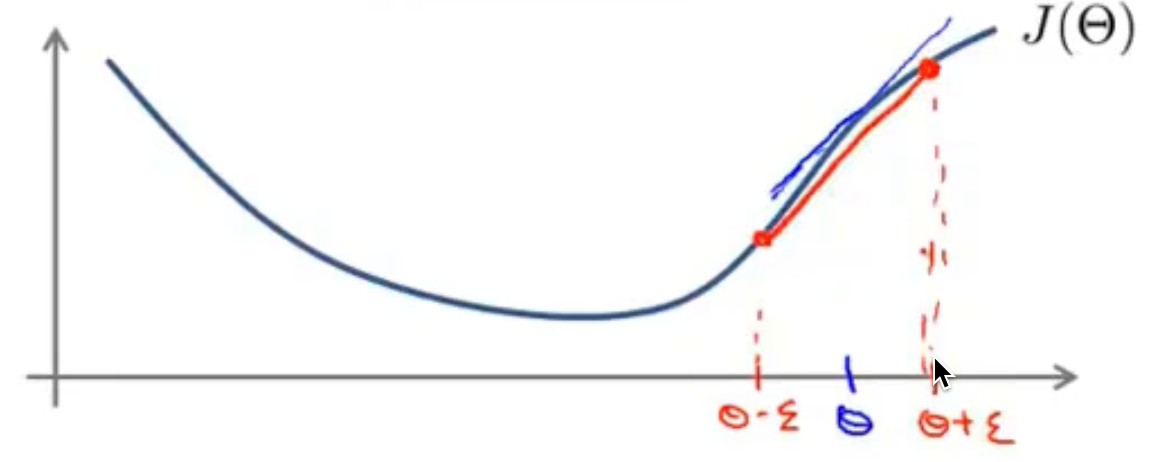
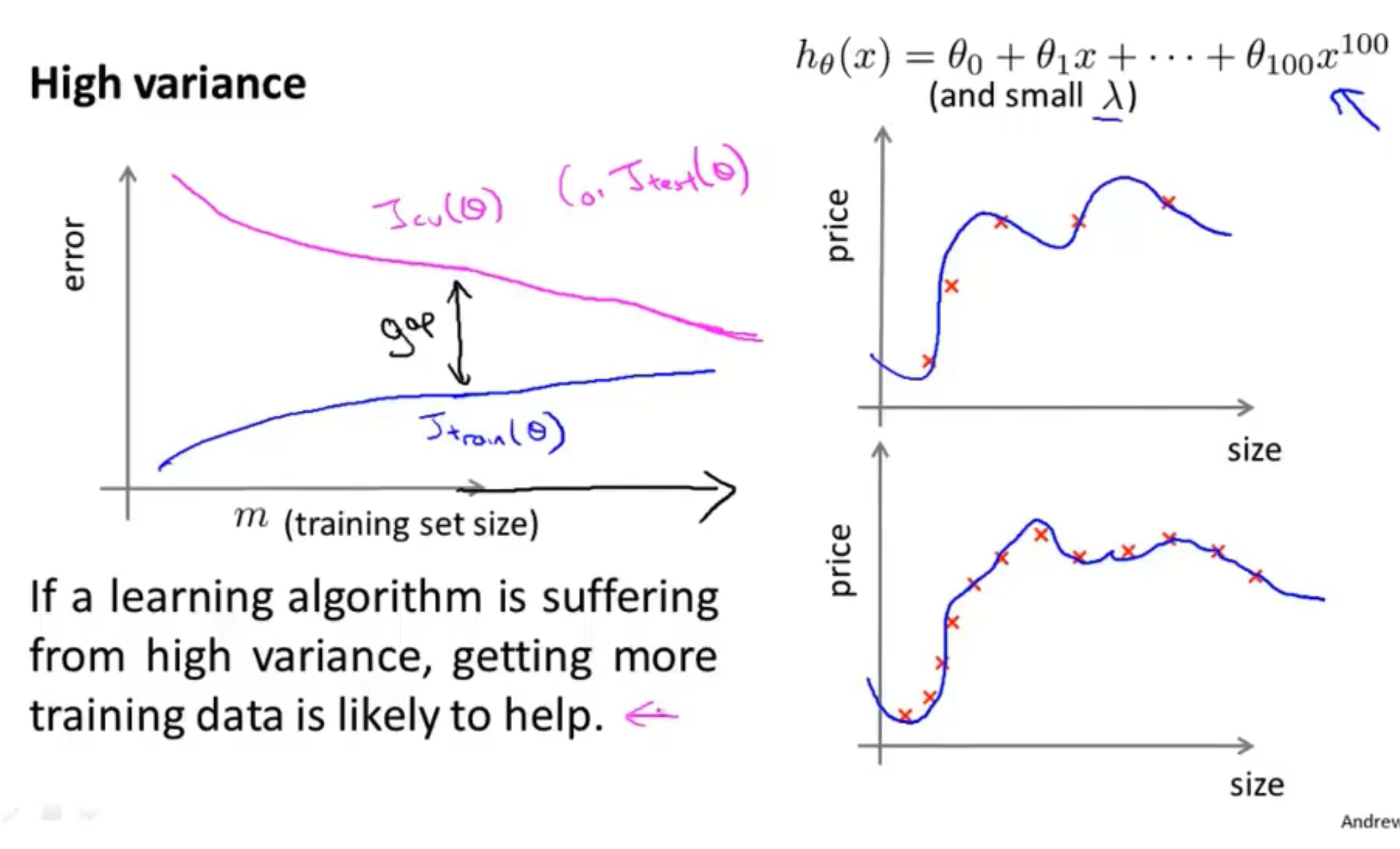
当遇到高方差时,也就是过拟合,当我们的训练量很少的时候,我们的图像肯定拟合的很好,而当训练集逐步增多时,我们的训练误差肯定会越来越大,因为此时的图像越来越难拟合了,而我们的交叉验证集误差再训练集少的情况下,误差会很大,因为训练集太少了,泛化能力会很差,而随着训练集的增多,函数的泛化能力随之也会越来越好,那么交叉验证集的误差也会越来越小
所以当遇到高方差时,通过增加训练集的个数,可以有效提高我们的泛化能力,如下图所示
假设当我们训练好了逻辑回归模型,然后将其放入测试集中测试,发现其拥有99%的正确率,也就相当于只有1%的误差,这样看起来这个数值已经非常不错了,但是如果测试集本身就只有0.5%的正类呢?那这样的话这个模型看上去就没有那么好了
我们甚至可以直接用一个预测函数预测测试集内所有样本均为负类,这么简单的预测函数的正确率却能达到99.5%
def predict(X):
return y = 0
复制像上述所说的类就是偏斜类,当正例和反例之间的样本数相差较大时,我们把这种数据集叫偏斜类
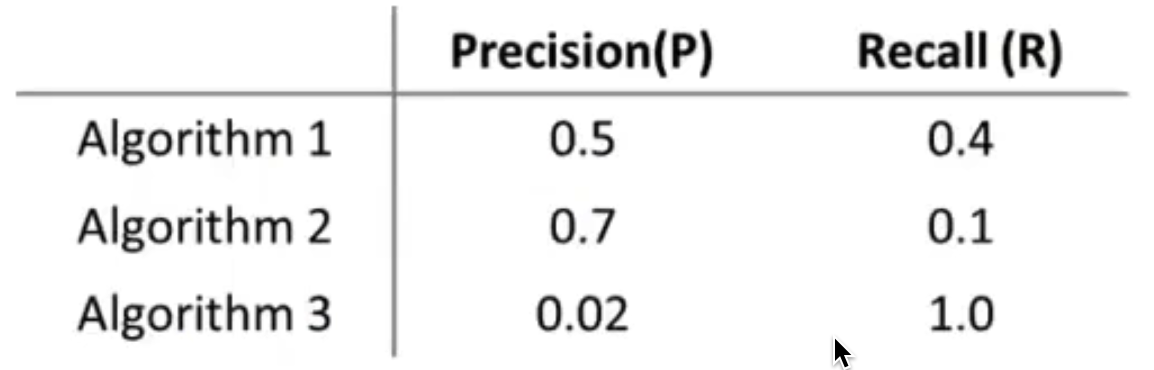
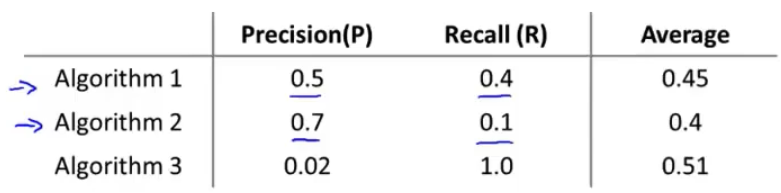
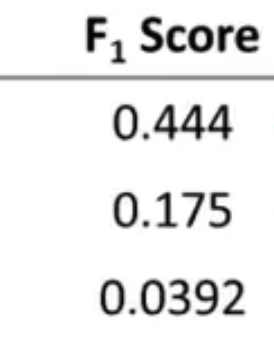
假设有一个事件B,他是由事件A引起的,那么P(A)就是我们的先验概率
即在事件B发生之前,我们对事件A的概率的一个最初的判断
好,现在我们已知道事件B的概率,想知道事件A的概率,也就是条件概率P(A|B)
即在事件B发生后,我们重新对A的概率进行评估,这就是后验概率
举个例子
我们现在已经知道了贝叶斯公式:\(P\left(A_{i} \mid B\right)=P\left(A_{i}\right)\frac{ P\left(B \mid A_{i}\right)}{P(B)}\)
我们将\(\frac{ P\left(B \mid A_{i}\right)}{P(B)}\)部分叫做概率因子
于是我们可以得到如下几个推断:
我们有一个判断程序员是不是大佬的训练集,其中有十个样本,每个样本有三个特征
特征的选取范围如下
| 数学 | 英语 | 代码能力 | 是否大佬 |
|---|---|---|---|
| 好 | 好 | 强 | 是 |
| 不好 | 好 | 一般 | 不是 |
| 不好 | 不好 | 弱 | 不是 |
| 好 | 好 | 一般 | 是 |
| 不好 | 好 | 强 | 是 |
| 好 | 不好 | 一般 | 不是 |
| 好 | 好 | 弱 | 是 |
| 不好 | 不好 | 强 | 不是 |
| 好 | 不好 | 强 | 是 |
| 不好 | 好 | 弱 | 不是 |
现在给出一个特征为(数学好,英语不好,代码能力弱)样本,根据这个训练集,我们来判断这个样本是否是大佬
我们掏出贝叶斯公式:\(P\left(A_{i} \mid B\right)=P\left(A_{i}\right)\frac{ P\left(B \mid A_{i}\right)}{P(B)}\),将其转换一下:\(P\left(类别_{i} \mid 特征\right)=P\left(类别_{i}\right)\frac{ P\left(特征 \mid 类别_{i}\right)}{P(特征)}\)
根据这个公式,我们就可以计算是不是大佬的概率了
于是,是大佬的概率为:
不是大佬的概率为:
其中的\(P(数学好\ 英语不好\ 代码弱)\)为全概率公式,等价于:
然后我们分别计算一下上面的概率,对比一下就知道该样本是不是大佬了
于是\(P\left(是 \mid 数学好\ 英语不好\ 代码弱\right)=\frac{\frac{1}{2}\frac{4}{5}\frac{1}{5}\frac{1}{5}}{\frac{1}{2}\frac{4}{5}\frac{1}{5}\frac{1}{5}+\frac{1}{2}\frac{1}{5}\frac{3}{5}\frac{2}{5}}=0.4\)
同理可得\(P\left(不是 \mid 数学好\ 英语不好\ 代码弱\right)=0.6\)
因为0.6>0.4,所以朴素贝叶斯算法预测该人不是大佬
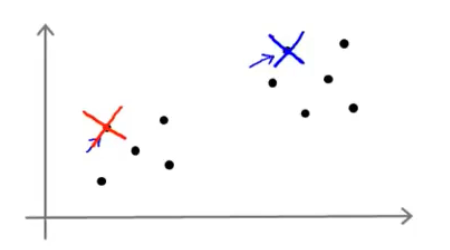
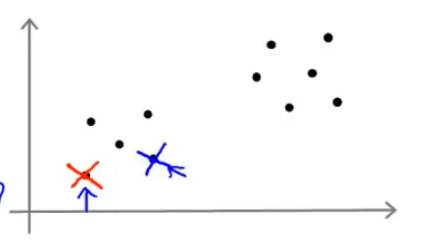
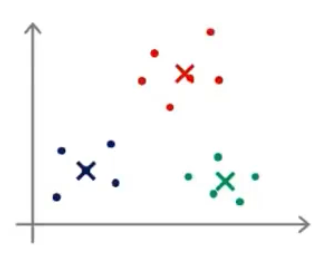
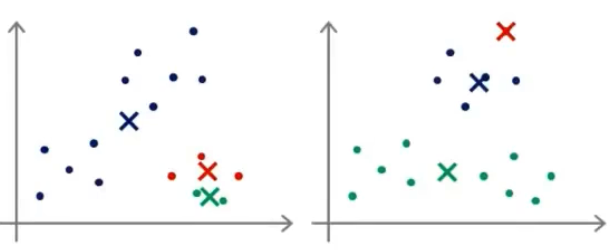
我们先想好要将整个数据集分为几个簇,若为K个簇,则分配K个聚类中心,将每个聚类中心随机分配一个数值,每个聚类中心的每次迭代都将比较所有样本和自己的距离,将离自己近的样本划分为自己的类别,然后计算自己类别下的所有样本的均值赋值给自己,再更新位置,最终碰到更新不动了,则划分完成,如下列步骤所示
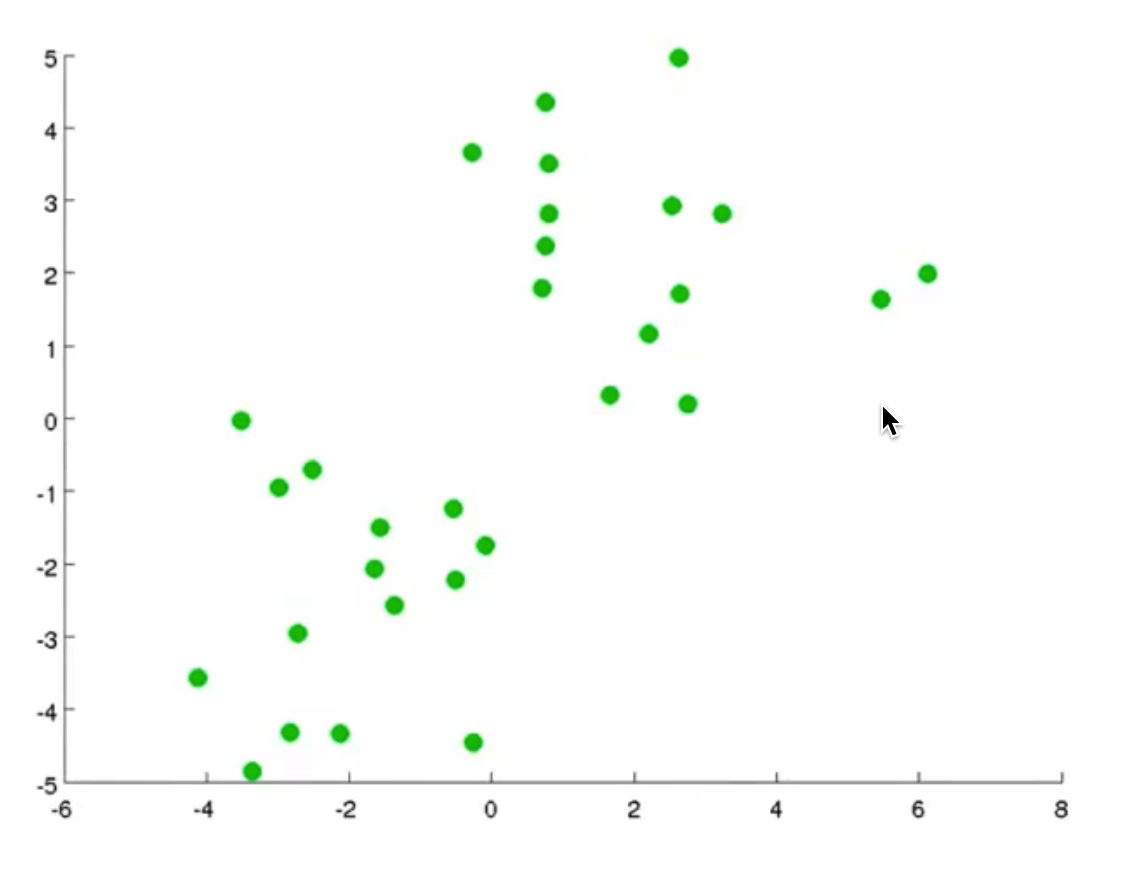
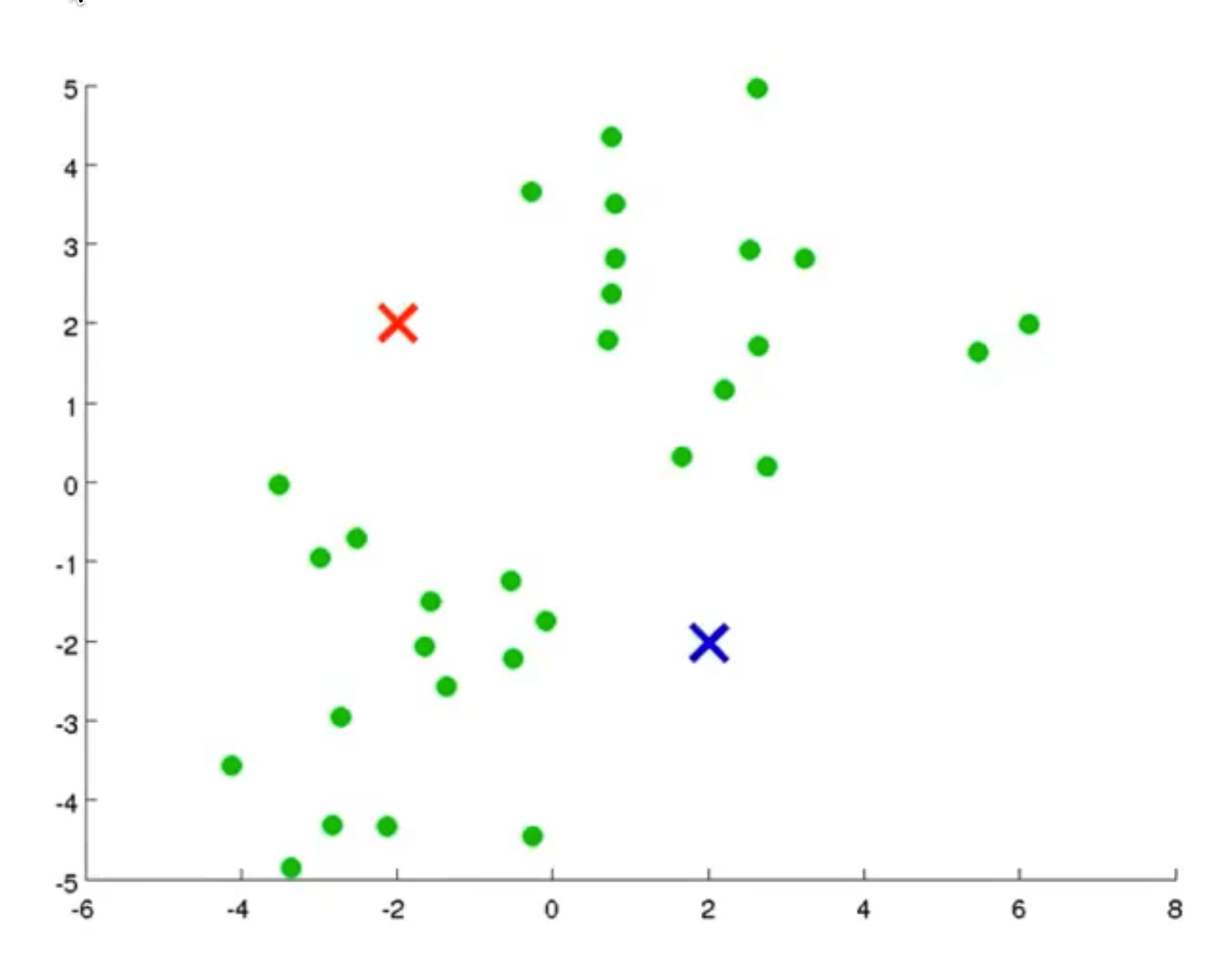
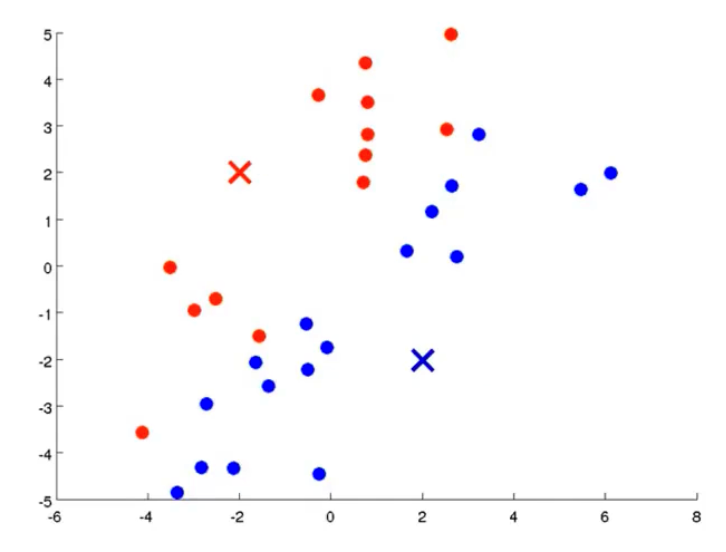
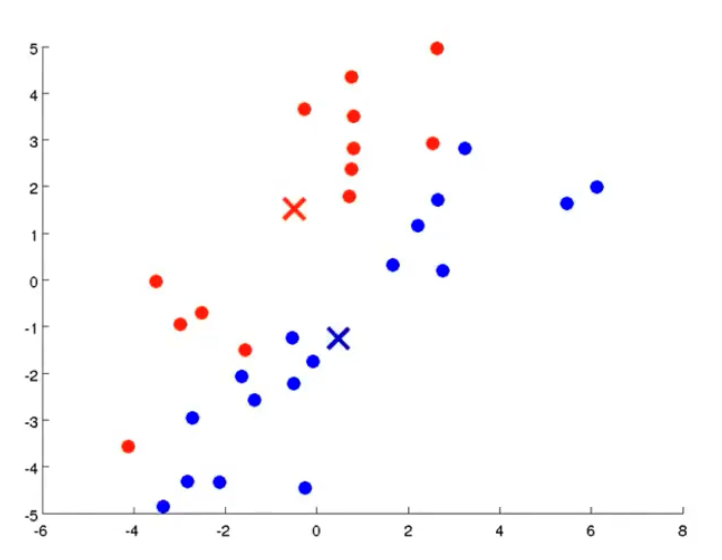

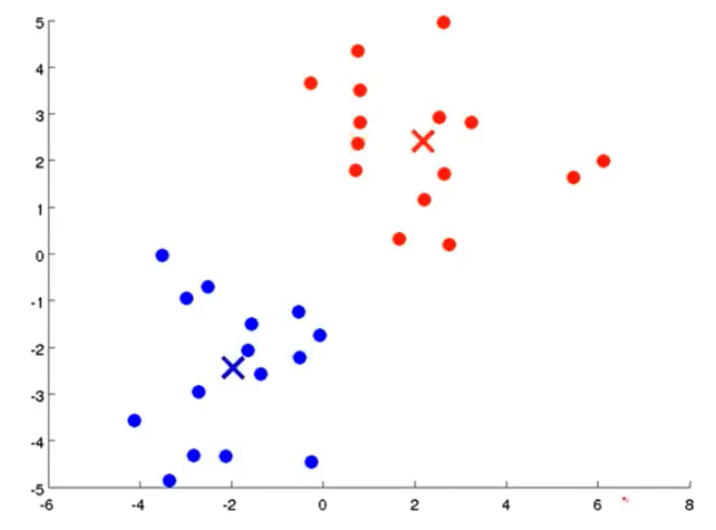
从上示图例可以清楚的看见两个聚类中心所移动的走向及其步骤的
本文介绍了注意力机制的基本原理,并使用 Python 和 TensorFlow/Keras 实现了一个简单的注意力机制模型应用于文本分类任务。