C源程序需要经过预处理、编译、汇编几个阶段,得到各自源文件对应的可重定位目标文件,可重定位目标文件就是各个源文件的二进制机器代码,一般是.o格式。比如:util1.c、util2.c及main.c三个C源文件,经过预处理器、编译器、汇编器的处理,就可以得到各自的目标文件util1.o,util2.o以及main.o。可重定位目标文件中的地址是从0开始的,需要链接器将若干个可重定位目标文件通过符号解析、重定位等工作,链接成为一个可执行的二进制目标文件。在Linux下,可以使用gcc -c 对源文件进行预处理、编译、汇编,得到目标文件:
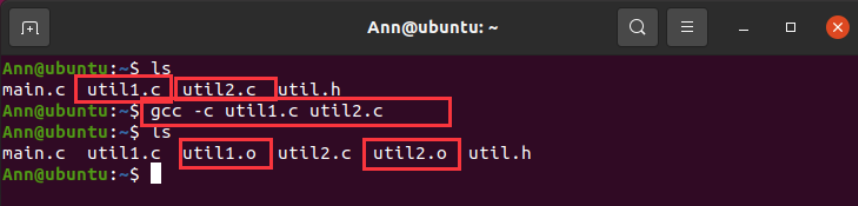
可以看到源文件util1.c及util2.c被编译成为了对应的目标文件util1.o及util2.o。在给定的例子中,util1.c和util2.c实际上分别定义了两个函数add和mult,返回两个整数的加法和乘法结果(这么做有点儿蠢,这里只是作为一个例子,讲清楚后面静态库的概念)。两个函数的定义如下:
//util1.c int add(int a,int b) { return a + b; } //util2.c int mult(int a,int b) { return a * b; }复制
util.h中包含了对这两个函数的声明。 main.c使用其中的add函数:
#include <stdio.h> #include "util.h" int main() { int a = 5; int b = 10; int c = add(a,b); printf("%d\n",c); return 0; }复制
实际上,所有的编译系统都提供一种机制,将所有相关的目标模块(即目标文件)打包成为一个单独的文件,称为静态库。在Linux中,静态库以一种被称为存档(archive)的文件格式存放在磁盘中。存档文件由后缀.a标识,.a格式的存档文件是一组连接起来的可重定位目标文件的集合,有一个头部用来描述每个成员目标文件的大小和位置。C标准定义了许多静态库,如标准IO操作scanf,printf,字符串操作strcpy等,它们在libc.a库中;一些浮点数学函数如sin,cos等,它们在libm.a库中。
当然,静态库是目标文件的集合,我们也可以将自己定义的函数编译成目标代码,加入静态库中。为了为若干目标文件创建静态库,可以使用ar rcs:

ar rcs 后面紧跟的libutil.a是创建的静态库的名字,通常以lib三个字母开头,后面的util可以自己指定,静态库以.a为后缀。util1.o 及 util2.o 是我们要加入静态库的两个目标文件。这样,就创建了一个静态库文件libutil.a。可以使用ar t来查看静态库文件中包含的目标文件:

接下来,我们在main函数中使用这个库。要在main中使用libutil.a库,需要链接通过编译main.c得到的目标文件main.o和libutil.a:
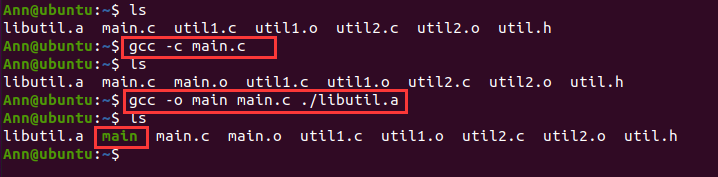
可以看到,gcc将main.c对应的目标文件与库libutil.a链接起来,得到了可执行文件main。我们执行可执行文件main,得到期望的结果:

注意,main函数中include了头文件util.h,在util.h中对libutil.a中的函数进行了声明。
那么,重点来了,为什么需要引入静态库这种东西呢?将C标准提供的所有库都放在一个可重定位目标模块中不行吗?
事实上是可以的,不过,这种设计有一个很大的缺点是系统中的每个可执行文件都要包含这个整个的大的目标模块的完全副本,这样做很浪费存储空间。比如,C标准的libc.a大约5MB,现在有一台机器装载了15个用到了C标准库的可执行文件,那么这15个可执行文件里每一个实际上都经过链接器的链接,嵌入了libc.a库中的5MB目标代码,而实际上它们可能用到5MB目标代码里的很小一部分(比如,某个目标文件可能只引用了标准库中的strcpy函数),这样,造成了严重的存储空间浪费。而静态库实际上提供了这样一种功能:相关的函数可以被编译为独立的目标模块,然后封装成一个单独的静态库文件,当链接器构造一个可执行文件时,它只“提取”静态库里被应用程序引用的目标模块(换句话说,对于程序中用不到的,链接器不会将它复制到可执行文件中去),比如例子中main.c只用到了add函数,链接器就只会将库libutil.a中的multi1模块复制到可执行文件,而不会复制multi2模块。
还有一种方法,就是把每个函数创建独立的可重定位目标文件。而这种方法对于应用程序员来说是极其不友好的,因为这种方法要求应用程序员显示地链接需要的目标模块到可执行文件中,这是一个容易出错且耗时的过程。
总结来说,静态库提供了将每一个目标模块独立地打包的功能,并且可以由链接器自动地提取被程序引用的目标模块,这减少了可执行文件在磁盘和内存中的大小,并且大大降低了程序员链接各个目标文件的压力。
注意:若目标代码引用了一个静态库,比如,假设libx.a引用了liby.a和libz.a中的模块,那么,我们必须在命令行中将libx.a放在liby.a和libz.a之前:
gcc main.c libx.a libz.a liby.a复制
这个要求是必须的。如果将libx.a 放在了它们任意一个之后,比如:
gcc main.c libz.a libx.a liby.a复制
将导致链接时错误:链接器要求如果目标代码(可重定位目标模块或静态库目标模块)引用了静态库(不包括可重定位目标模块)中的模块,那么在命令行中必须把引用者放在前面,被引用者放在后面。详细原因与链接器的工作过程有关,这里不做赘述。
博主会持续更新精心原创文章,在逻辑严瑾的同时,力求最通俗易懂地把知识写得清楚,写得明白。觉得博主写得还可以的小伙伴儿点点关注,点点赞啦~
有不足的地方,也请各路大神批评指正,感谢大家的支持~