本文介绍了一个名为MIND2WEB的数据集,用于开发和评估Web通用代理,可以使用自然语言输入指令,使之可以在任何复杂的网站上执行操作。
现有的用于Web代理的数据集要么使用模拟网站,要么仅涵盖有限的网站和任务集,因此不适用于通用的Web代理。
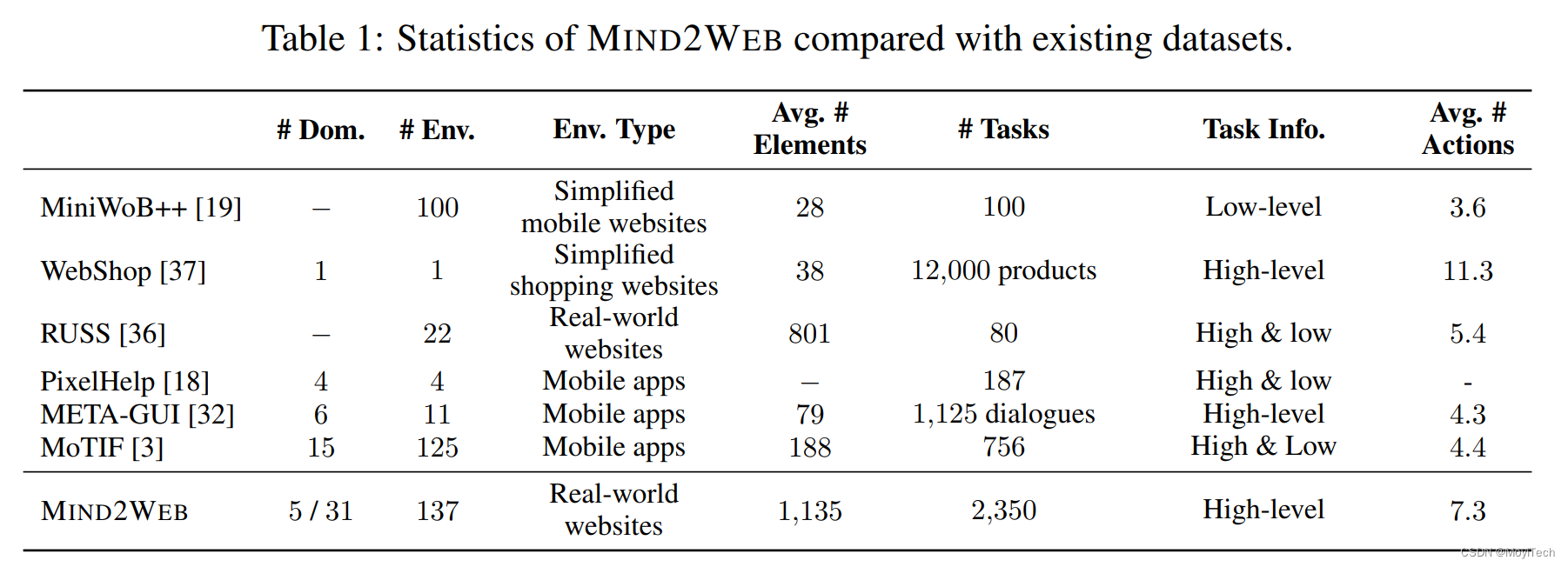
MIND2WEB数据集包含来自137个网站、跨足31个领域的超过2,000个开放式任务,以及为这些任务收集的众包行动序列。MIND2WEB为构建通用Web代理提供了三个必要的要素:
基于MIND2WEB,作者进行了首次尝试使用大型语言模型(LLMs)构建通用Web代理。
由于真实世界网站的原始HTML通常元素过多无法直接输入LLM,本文的方案为:先通过小型LM进行筛选,再输入到LLM中,可以显著提升模型的效果和效率。
该数据集旨在使代理通过一系列操作完成特定任务
执行方式:逐步预测、执行,
input:当前网页、历史操作,output:接下来的操作 (有RNN的意思)
数据通过亚马逊众包平台(Amazon Mechanical Turk)收集,主要分为三个阶段:
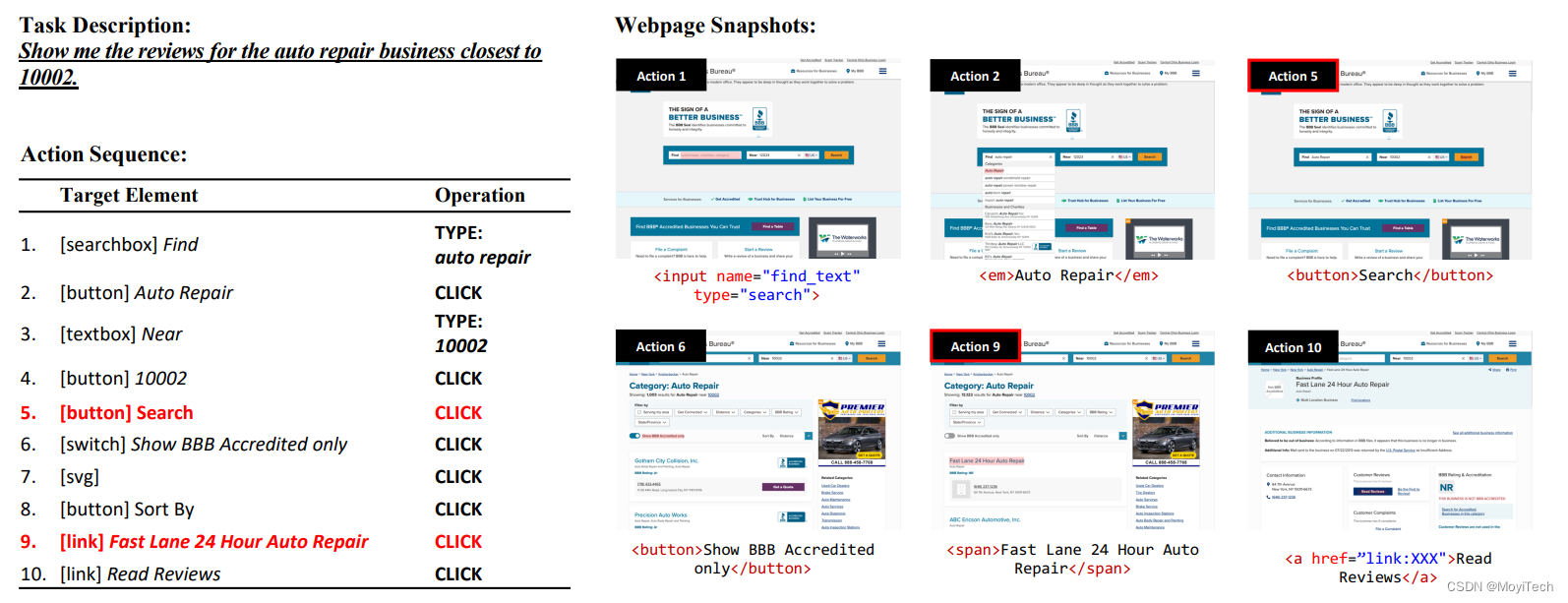
故这种数据集(Mind2Web)对于代理模型的训练及应用来说提出了很大的挑战。
为了使用Mind2Web数据集,引入了MindAct框架
由于原始HTML过大,直接输入到LLM中消耗资源过大,MindAct将此分为二阶段过程(如图三)
Small LM 用于筛选;LLM用于预测

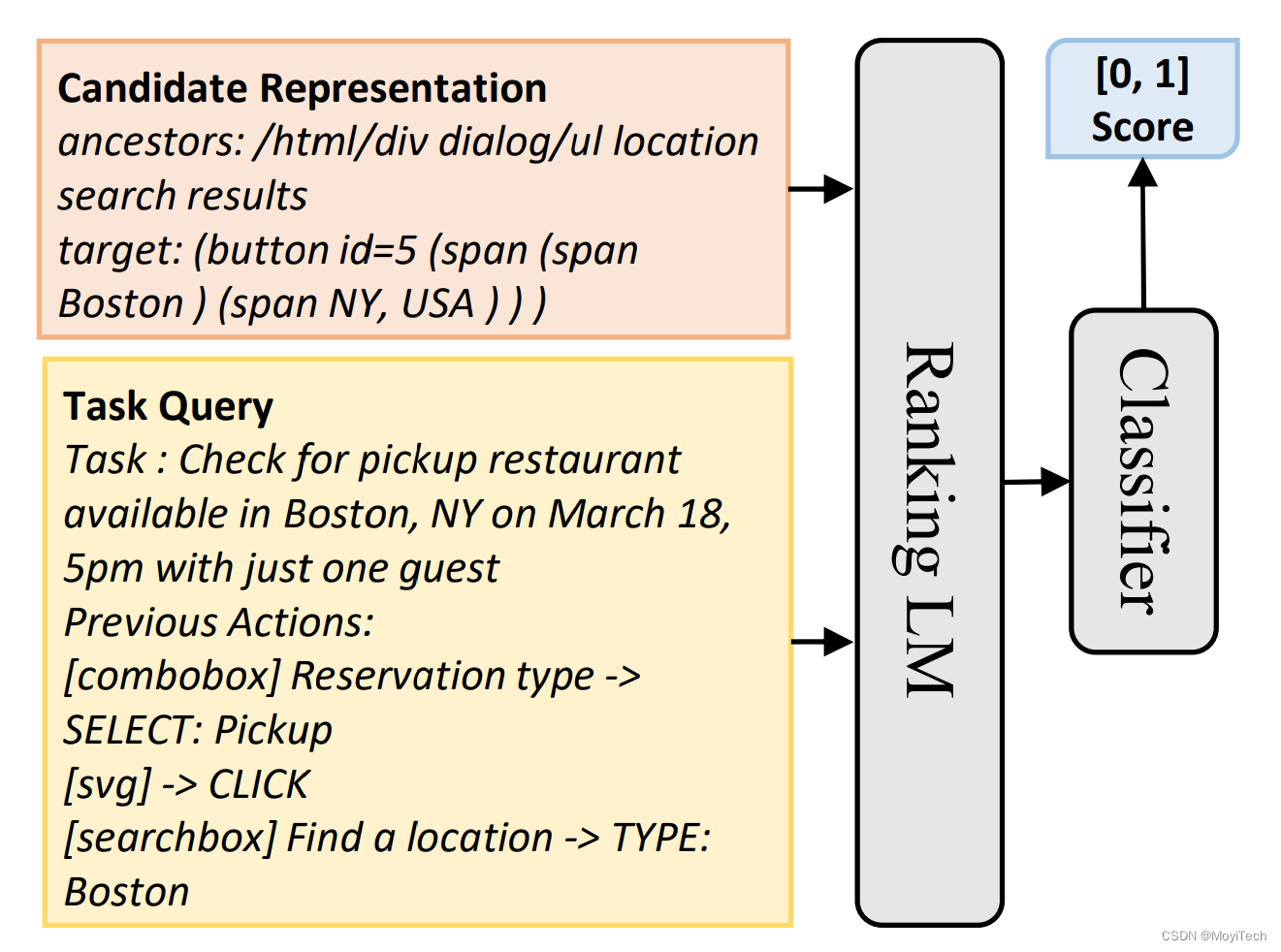
feature: Task Description + Previous Actions
target: Top-k Elements
LLM用于判别 比 生成更有效率
故LM被训练为从一系列选项中进行选择,而不是生成完整的目标元素
Divide the top-k candidates into multiple clusters of five options.
If more than one option is selected after a round,
Form new groups with the selected ones.
This process repeats until a single element is selected, or all
options are rejected by the model
test result:
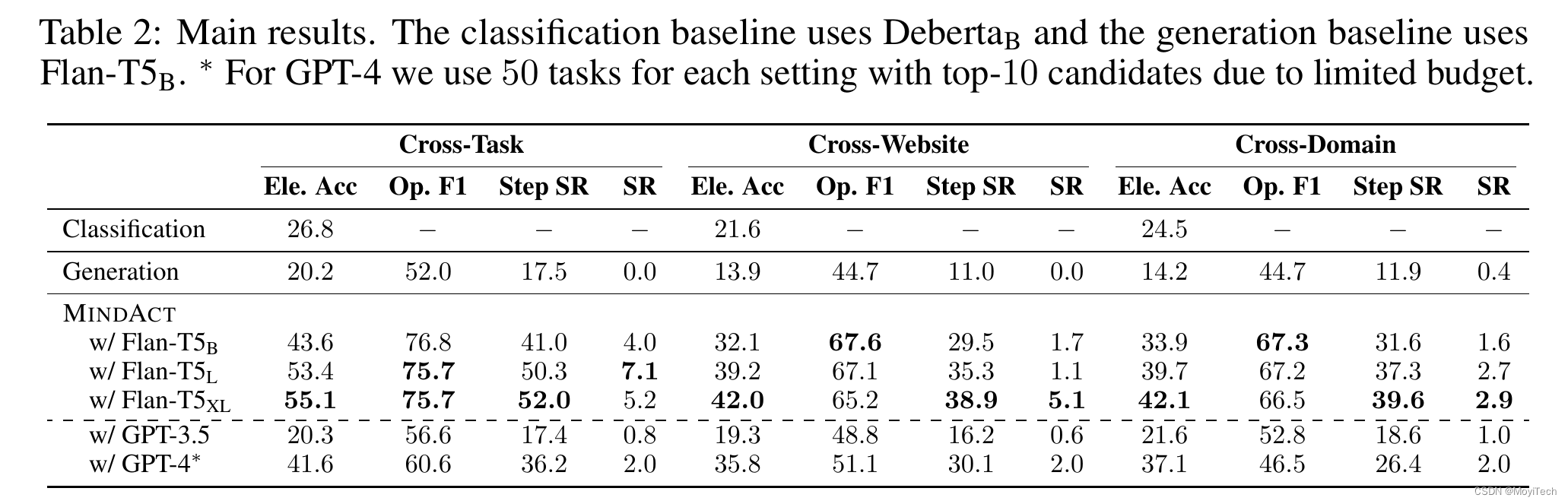
baseline1: Classfication,仅使用Debertab进行 元素 预测
baseline2: Generation,使用Flan-T5直接进行 元素+操作 的预测
Test-Cross-Domain:使用不同的域名进行预测
Test-Cross-Website:使用同域的网站预测
TestCross-Task:使用相同的网站预测
分别使用Element Accuracy、Operation F1、Step Success Rate、Success Rate对数据进行评估
使用了微调的DeBERTa 作为Small LM,用于第一步的候选生成(For efficiency, use the base version DeBERTaB with 86M parameters.)
分别获得了88.9% / 85.3% / 85.7% 的recall
取k=50,即top-50用于下一步预测。
使用Flan-T5作为生成模型
尽管是大模型(220M for Flan-T5),但在元素选择方面表现先不佳
使用上述MindAct中使用的multi-choice QA formulation方法很有效
The best model achieves 52.0% step success rate under Cross-Task setting, and 38.9% / 39.6% when generalizing to unseen websites(Cross-Website) and domains(Cross-Domain).
However, the overall task success rate remains low for all models, as the agent often commits at least one error step in most cases.
分别使用MINDACT的方法在GPT-3.5和GPT-4进行了测试,结果如下:
GPT-3.5表现不好,在元素选择正确率上仅有20%
GPT-4要稍好一些,与微调过的Flan-T5不相上下,表明用大语言模型在此有很大的潜力
但GPT-4运行成本很高,使用较小规模的模型是一个很好的发展方向