数据库现有数据其中两列: s - 开始时间, e - 结束时间. 在新插入数据s', e'之前需要判断两个时间之间是否有重合
因为使用mybatis-plus的缘故, 结论都使用s或e在符号前面.
比如yyyy-MM-dd HH:mm:ss格式的数据, 多用于判断预约时间和每日排班冲突.
对于冲突的情况使用列举法有
s' < e' < s < e: 新时间段在已有时间左边, 不包含, 情况1s' < s < e' < e: 新时间段和已有时间左边有交集, 情况2s < s' < e' < e: 新时间段在已有时间内, 被包含关系, 也即在已有时间段内部, 情况3s < s' < e < e': 新时间段和已有时间右边有交集, 情况4s' < s < e < e': 新时间和已有时间是是包含关系, 也即新时间段在已有时间段外部, 情况5s < e < s' < e': 新时间段在已有时间右边, 不包含, 情况6s < e' 并且 e > s'时候两个时间端肯定有交集, 也即冲突.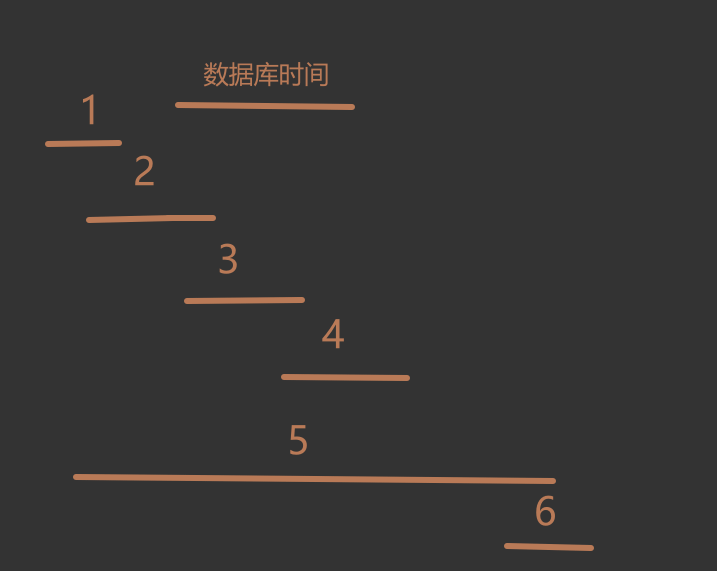
比如HH:mm:ss格式的, 多用于固定早中晚班定义 / 营业时间等周期性活动的时间冲突判断.
s < e' 并且 e > s'即可s' - 24 和 0 - e'
同理拆分成s - 24 和 0 - e.
对于s > e情况下, 虽然sql可以使用start_time > end_time, 但是在mybatis-plus中写不出来
所以在保存时候添加一列is_greater代表是否当条数据跨天:
// 保存跨天时候的结束时间, 将结束时间变成24:00:00
// 传过来的结束时间赋值给nextDayEndTime, 也即finalNextDayEndTime
String finalNextDayEndTime = nextDayEndTime;
List<BaseTimeConfig> existList = configService.lambdaQuery()
.and(p -> p
// 按照开始小于结束判断(数据也是开始小于结束)
.and(q -> q.eq(BaseTimeConfig::getIsGreater, 0)
.and(q1 -> q1
.lt(BaseTimeConfig::getStartTime, endTime)
.gt(BaseTimeConfig::getEndTime, startTime))
// 开始大于结束时间时候(), 计算拆分出来的第二天也即0点 - endTime(复制给了nextDayEndTime)
// 需要((开始小于结束 和 开始大于结束拆分出第一天) or (开始大于结束拆分出第二天))满足其一即可
// 拆分出来的第二天是0开始, 结束时间肯定肯定比0大, 所以判断开始时间比nextDayEndTime小即可
.or(!"".equals(finalNextDayEndTime), q1 -> q1.lt(BaseTimeConfig::getStartTime, finalNextDayEndTime)))
// 按照开始小于结束判断(数据是开始大于结束的, 判断结束时间大于传入的开始时间即可,
// 因为数据库开始时间应该算0, 0肯定比传入的开始时间小于)
.or(q -> q.eq(BaseTimeConfig::getIsGreater, 1)
.and(q1 -> q1
// 后半截
.and(q2 -> q2.gt(BaseTimeConfig::getEndTime, startTime))
// 前半截
.or(q2 -> q2.lt(BaseLightTimeConfig1::getStartTime, baseLightTimeConfig.getEndTime())))
// 传入跨天的话, 数据库中跨天的都冲突
.or(!"".equals(finalNextDayEndTime), q2 -> q2.ne(BaseLightTimeConfig1::getId, 0))))
.ne(baseTimeConfig.getId() != null && baseTimeConfig.getId() > 0,
BaseTimeConfig::getId, baseTimeConfig.getId())
.isNull(BaseTimeConfig::getDeletedAt)
.list();
复制总体思路清晰, 逐步分析得到, 但不巧妙
在保存s和e时候, 如果是跨天的拆分成s,24,0,e; 不跨天的话使用s,e,s,e, 对应字段s,e,s1,e1
对于s'和e'来说也是同上, 拆分出s',e',s1',e1'
分别比较s,e和s',e' 与 s1,e1和s1',e1', 两个条件使用或者连接, 也即: ((s < e' 并且 e > s') 或者 (s1 < e1' 并且 e1 > s1'))
((s < 24 并且 24 > s') 或者 (0 < e1' 并且 e1 > 0))((s < e' 并且 24 > s') 或者 (0 < e' 并且 e1 > s'))(s < e') 或者 (e1 > s')即可((s < 24 并且 e > s') 或者 (s < e1' 并且 e > 0))(s < e1') 或者 (e > s')即可((s < e' 并且 e > s') 或者 (s < e' 并且 e > s'))s < e' 并且 e > s'即可// s', e'
String startTime = "22:00:00", endTime = "24:00:00";
// s1', e1'
String startTime1 = "00:00:00", endTime1 = "03:00:00";
// ((s < e' 并且 e > s') || (s1 < e1' 并且 e1 > s1'))
configService.lambdaQuery()
.and(q -> q
.lt(BaseTimeConfig1::getS, endTime)
.gt(BaseTimeConfig1::getE, startTime))
.or(q -> q
.lt(BaseTimeConfig1::getS1, endTime1)
.gt(BaseTimeConfig1::getE1, startTime1))
.list();
复制分两段存, 跨天时候24截取. 不跨天时候存两遍