基于Langchain与ChatGLM等语言模型的本地知识库问答应用实现。项目中默认LLM模型改为THUDM/chatglm2-6b[2],默认Embedding模型改为moka-ai/m3e-base[3]。
一.项目介绍
1.实现原理
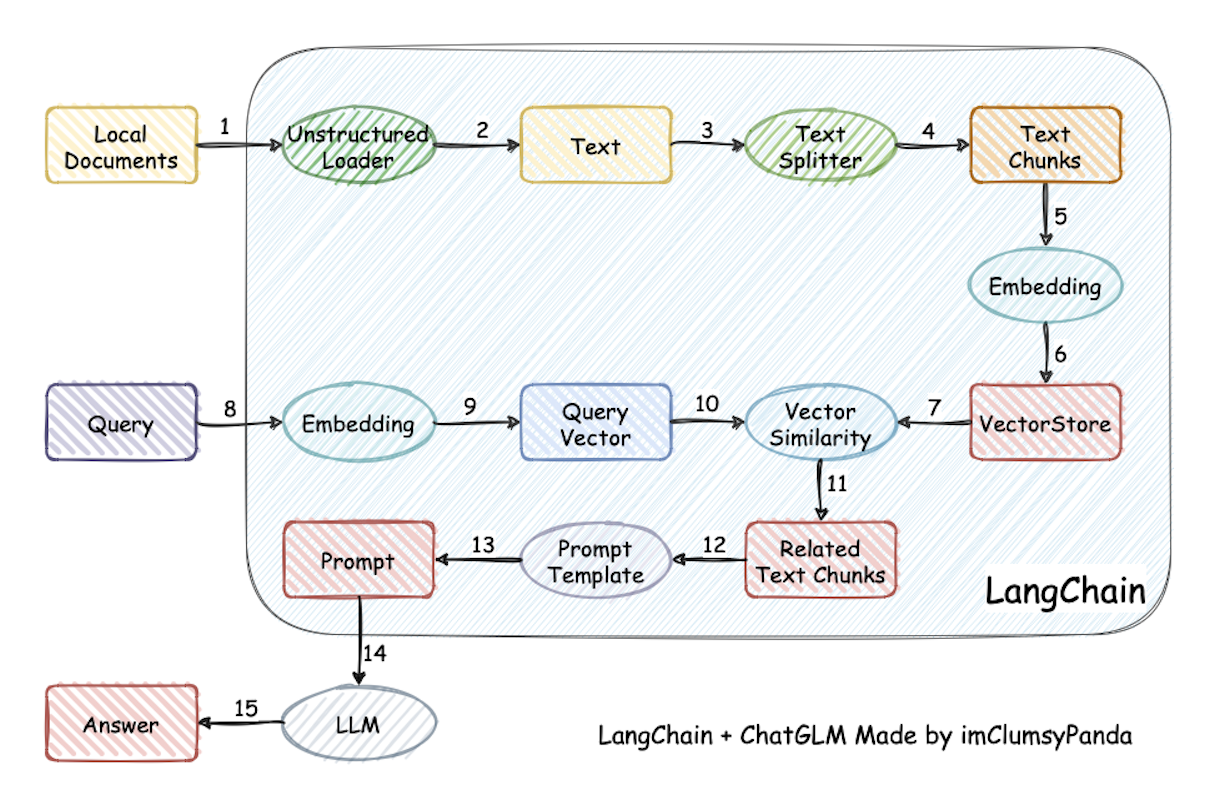
本项目实现原理如下图所示,过程包括加载文件->读取文本->文本分割->文本向量化->问句向量化->在文本向量中匹配出与问句向量最相似的topk个->匹配出的文本作为上下文和问题一起添加到prompt中->提交给LLM生成回答。
2.支持LLM模型
本地LLM模型接入基于FastChat实现,支持模型如下:
meta-llama/Llama-2-7b-chat-hf
Vicuna, Alpaca, LLaMA, Koala
BlinkDL/RWKV-4-Raven
camel-ai/CAMEL-13B-Combined-Data
databricks/dolly-v2-12b
FreedomIntelligence/phoenix-inst-chat-7b
h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b
lcw99/polyglot-ko-12.8b-chang-instruct-chat
lmsys/fastchat-t5-3b-v1.0
mosaicml/mpt-7b-chat
Neutralzz/BiLLa-7B-SFT
nomic-ai/gpt4all-13b-snoozy
NousResearch/Nous-Hermes-13b
openaccess-ai-collective/manticore-13b-chat-pyg
OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
project-baize/baize-v2-7b
Salesforce/codet5p-6b
StabilityAI/stablelm-tuned-alpha-7b
THUDM/chatglm-6b
THUDM/chatglm2-6b
tiiuae/falcon-40b
timdettmers/guanaco-33b-merged
togethercomputer/RedPajama-INCITE-7B-Chat
WizardLM/WizardLM-13B-V1.0
WizardLM/WizardCoder-15B-V1.0
baichuan-inc/baichuan-7B
internlm/internlm-chat-7b
Qwen/Qwen-7B-Chat
HuggingFaceH4/starchat-beta
FlagAlpha/Llama2-Chinese-13b-Chat and others
BAAI/AquilaChat-7B
all models of OpenOrca
Spicyboros + airoboros 2.2
VMware's OpenLLaMa OpenInstruct
任何EleutherAI的pythia模型,比如pythia-6.9b
在以上模型基础上训练的任何Peft适配器
说明:在线LLM模型目前已支持:ChatGPT、智谱AI、MiniMax、讯飞星火和百度千帆。
3.支持Embedding模型
本项目支持调用HuggingFace中的Embedding模型:
moka-ai/m3e-small
moka-ai/m3e-base
moka-ai/m3e-large
BAAI/bge-small-zh
BAAI/bge-base-zh
BAAI/bge-large-zh
BAAI/bge-large-zh-noinstruct
sensenova/piccolo-base-zh
sensenova/piccolo-large-zh
shibing624/text2vec-base-chinese-sentence
shibing624/text2vec-base-chinese-paraphrase
shibing624/text2vec-base-multilingual
shibing624/text2vec-base-chinese
shibing624/text2vec-bge-large-chinese
GanymedeNil/text2vec-large-chinese
nghuyong/ernie-3.0-nano-zh
nghuyong/ernie-3.0-base-zh
OpenAI/text-embedding-ada-002
4.安装FastChat
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip3 install -e ".[model_worker,webui]"
二.设置配置项
1.LLM模型配置
配置Langchain-Chatchat/configs/model_config.py文件中的llm_model_dict参数:
llm_model_dict = {
"chatglm2-6b": {
"local_model_path": "L:/20230713_HuggingFaceModel/chatglm2-6b",
"api_base_url": "http://localhost:8888/v1", # URL需要与运行fastchat服务端的server_config.FSCHAT_OPENAI_API一致
"api_key": "EMPTY"
},
......
}
2.Embedding模型配置
配置Langchain-Chatchat/configs/model_config.py文件中的embedding_model_dict参数:
embedding_model_dict = {
......
"text2vec": "L:/20230713_HuggingFaceModel/text2vec-large-chinese",
"m3e-base": "L:/20230620_LLM模型/20230918_通用/20230918_ChatGLM/m3e-base",
......
}
3.知识库初始化与迁移
首次运行项目,需要初始化或重建知识库,如下所示:
python3 init_database.py --recreate-vs
三.启动API服务和Web UI
一键启动所有Fastchat服务、API服务、WebUI服务:
1.启动命令
python3 startup.py -a
2.FastAPI docs界面
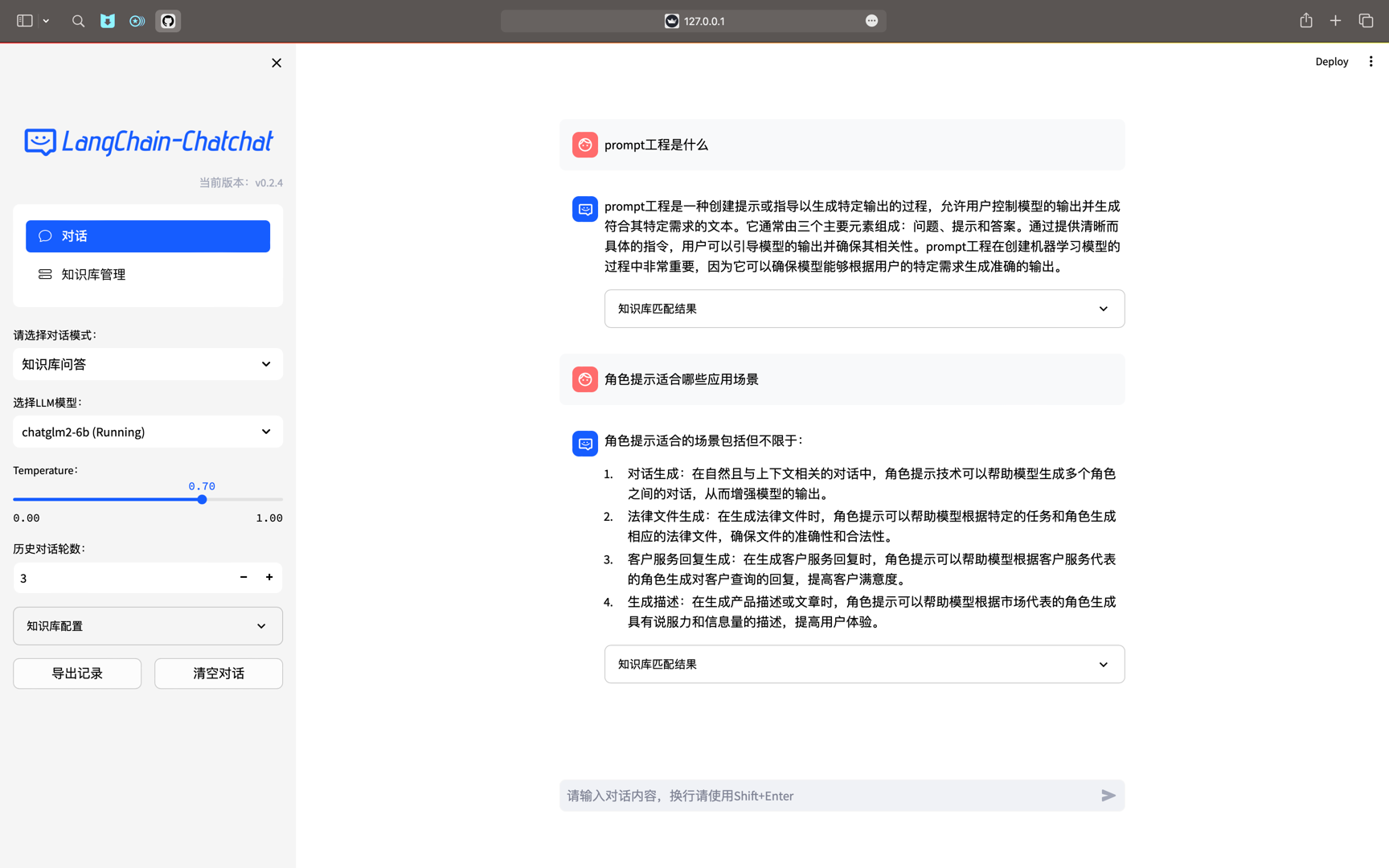
3.Web UI对话界面
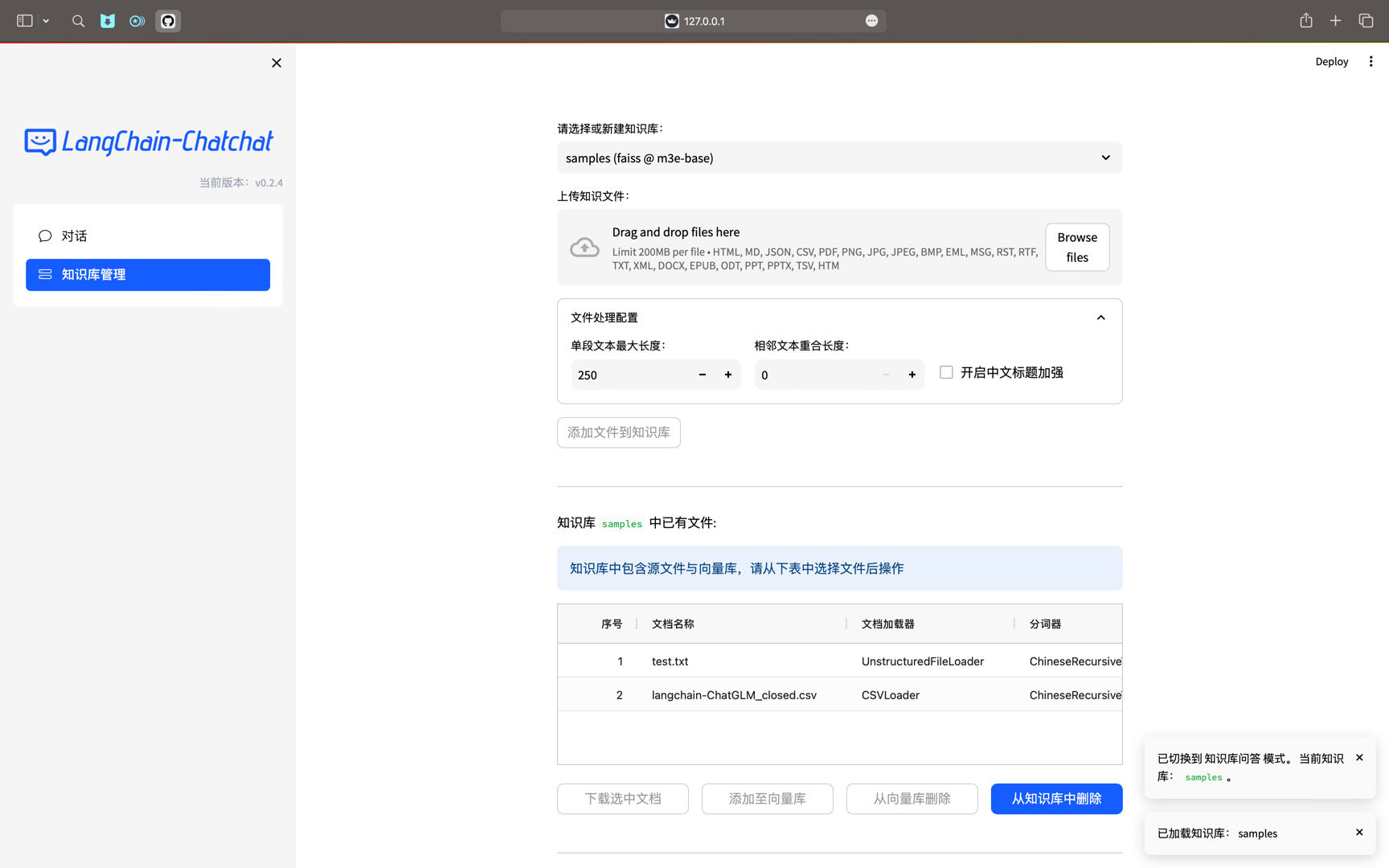
4.Web UI知识库管理页面
参考文献:
[1]Langchain-Chatchat:https://github.com/chatchat-space/Langchain-Chatchat
[2]https://huggingface.co/THUDM/chatglm2-6b
[3]https://huggingface.co/moka-ai/m3e-base
[4]https://github.com/lm-sys/FastChat
[5]https://github.com/chatchat-space/Langchain-Chatchat/issues
路由链(RouterChain)是由LLM根据输入的Prompt去选择具体的某个链。路由链中一般会存在多个Prompt,Prompt结合LLM决定下一步选择哪个链。