今天在跑代码的时候,使用到了wandb记录训练数据。
我在23服务器上跑的好好的,但将环境迁移到80服务器上重新开始跑时,却遇到了如下报错
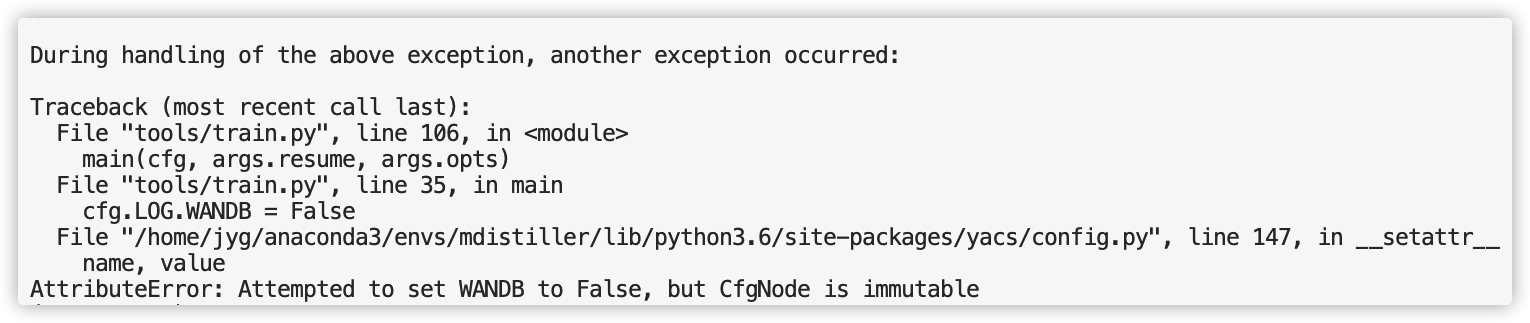
看这个报错信息是由于wandb没有apis这个属性,于是我定位到具体的报错代码

😯原来程序在import wandb时就抛出异常了。
我尝试验证是报错的原因在于程序导入wandb不成功而导致报错。
因此,我在终端打开python解释器,执行import wandb,果然出现了一模一样的报错信息

既然是wandb库的原因,一个很自然的想法便是对比27和80服务器上两个wandb库的版本号。
23服务器上wandb的版本号为0.15.11

80服务器上wandb的版本号为0.15.12

我抱着试试看的心态将80服务器上wandb的版本号更换为0.15.11,然后再次运行程序,成功!
pip install wandb==0.15.11复制
事后,我思考了一下为什么会导致版本号不同。首先我利用27上导出的yml文件在80上创建环境,即用conda env create -f mdistiller.yml
而该yml文件中wandb的版本号是正确的0.15.11
但后来我在通过该yml文件安装pytorch时中断了,因此使用pip install单独安装了pytorch。

然而pytorch安装中断会导致在pytorch之后剩下的包没有安装。所以,我使用了代码库的requirements.txt对剩下的包进行安装。
结果我看了下requirement.txt中的wandb并没有指定版本号,这就导致了安装的wandb为0.15.12版本
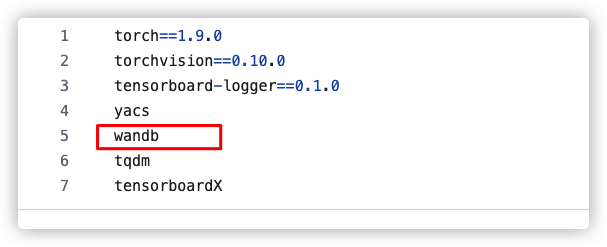
至于为什么通过yml文件在安装pytorch时会中断,我想可能是因为我当初安装pytorch时使用了pip而不是conda安装
PyCharm 提示:PEP 8: expected 2 blank lines, found 1 类或方法前需要空两行 解决方法:Ctrl+Alt+L 格式化一下就OK了。或者手动在前面敲一行