堆叠面积图和面积图都是用于展示数据随时间变化趋势的统计图表,但它们的特点有所不同。
面积图的特点在于它能够直观地展示数量之间的关系,而且不需要标注数据点,可以轻松地观察数据的变化趋势。而堆叠面积图则更适合展示多个数据系列之间的变化趋势,它们一层层的堆叠起来,每个数据系列的起始点是上一个数据系列的结束点,多数据列的展示更加直观和易于理解。
堆叠面积图观察几个数据系列随时间的变化情况时,既能看到各数据系列的走势,又能看到整体的规模,
但是,过多的系列,也会导致难以分辨。
此外,堆叠面积图展示的数据一般会有时间上的关联,当数据没有时间上的关联时,建议适用堆叠柱状图。
堆叠面积图是一种用于展示数据分类、分组和数据关联性的图表,主要由以下几个元素组成:
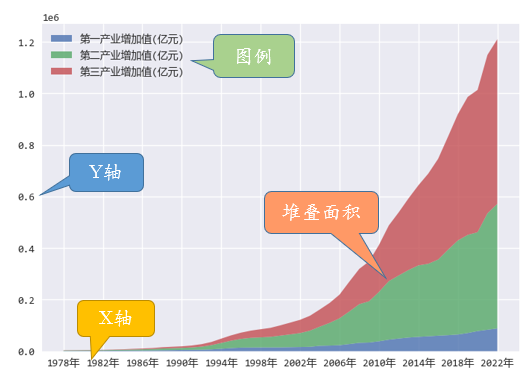
堆叠面积图适用于以下分析场景:
堆叠面积图不适用于以下分析场景:
这次使用三大产业的增加值来实战堆叠面积图的分析。
数据来源国家统计局公开数据,已经整理好的csv文件在:https://databook.top/nation/A02
本次分析使用其中的 A0201.csv 文件(国内生产总值数据)。
下面的文件路径 fp 要换成自己实际的文件路径。
fp = "d:/share/A0201.csv"
df = pd.read_csv(fp)
df
过滤出三大产业的数据:
key1 = "第一产业增加值(亿元)"
key2 = "第二产业增加值(亿元)"
key3 = "第三产业增加值(亿元)"
df = df[(df["zbCN"] == key1)
| (df["zbCN"] == key2)
| (df["zbCN"] == key3)]
df
绘制三大产业的堆叠面积图:
from matplotlib.ticker import MultipleLocator
key1 = "第一产业增加值(亿元)"
key2 = "第二产业增加值(亿元)"
key3 = "第三产业增加值(亿元)"
val1 = df[(df["zbCN"] == key1)].sort_values("sj")
val2 = df[(df["zbCN"] == key2)].sort_values("sj")
val3 = df[(df["zbCN"] == key3)].sort_values("sj")
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
ax.xaxis.set_major_locator(MultipleLocator(4))
ax.xaxis.set_minor_locator(MultipleLocator(2))
ax.stackplot(
val1["sjCN"],
[val1["value"], val2["value"], val3["value"]],
labels=[key1, key2, key3],
alpha=0.8,
)
ax.legend(loc="upper left")
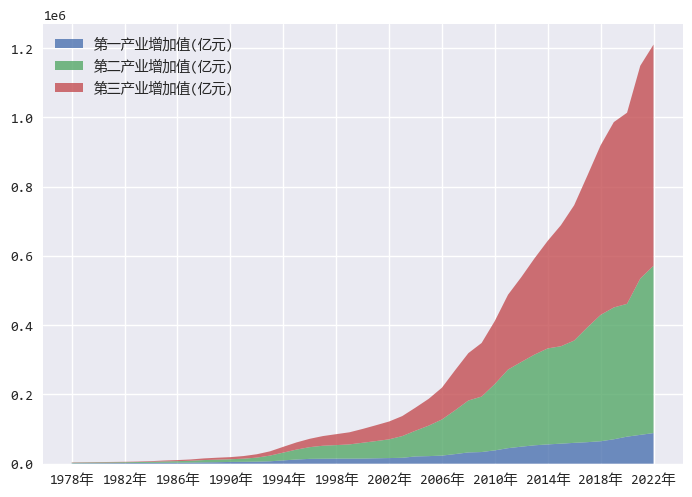
各个数据集在堆叠面积图中不会重合,
所以不仅可以看出各个产业的增长情况,还能看出整体的增长主要来自哪个产业的影响。
从分析结果可以看出,我国的经济增长主要来自于第二,第三产业的增长。
这个结果和之前的文章中关于人口的分析也是相吻合的,在那个文章中,我们发现农业人口大量减少,城镇人口大量增加。