日常开发中,相信大家都对 Kafka 有所耳闻,Kafka 作为一个分布式的流处理平台,一般用来存储和传输大量的消息数据。在 Kafka 中有三个重要概念,分别是 topic、partition 和 offset。
本文将给大家介绍 offset 的相关概念,大纲如下:
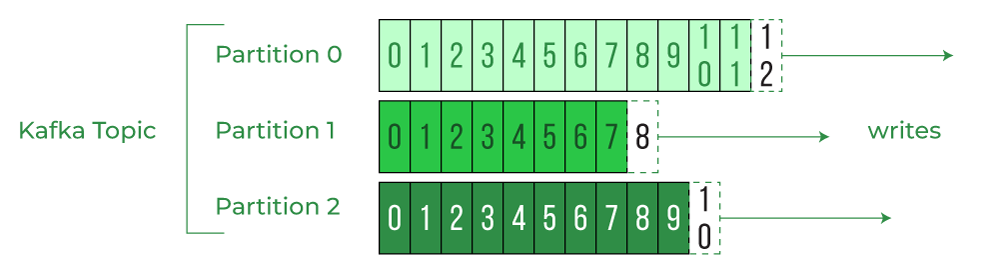
offset 是 Kafka 为每条消息分配的一个唯一的编号,它表示消息在分区中的顺序位置。offset 是从 0 开始的,每当有新的消息写入分区时,offset 就会加 1。offset 是不可变的,即使消息被删除或过期,offset 也不会改变或重用。
offset 的作用主要有两个:
offset 的存储和管理主要涉及到两个方面:生产者端和消费者端。
生产者在向 Kafka 发送消息时,可以指定一个分区键(Partition Key),Kafka 会根据这个键和分区算法来决定消息应该发送到哪个分区。如果没有指定分区键,Kafka 会采用轮询或随机的方式来选择分区。生产者也可以自定义分区算法。
当消息被写入到分区后,Kafka broker 会为消息分配一个 offset,并返回给生产者。生产者可以根据返回的 offset 来确认消息是否成功写入,并进行重试或其他处理。
消费者在消费 Kafka 消息时,需要维护一个当前消费的 offset 值,以及一个已提交的 offset 值。当前消费的 offset 值表示消费者正在消费的消息的位置,已提交的 offset 值表示消费者已经确认消费过的消息的位置。
消费者在消费完一条消息后,需要提交 offset 来更新已提交的 offset 值。提交 offset 的方式有两种:自动提交和手动提交。
无论是自动提交还是手动提交,offset 的实际存储位置都是在 Kafka 的一个内置主题中:__consumer_offsets。这个主题有 50 个分区(可配置),每个分区存储一部分消费组(Consumer Group)的 offset 信息。Kafka broker 会根据消费组 ID 和主题名来计算出一个哈希值,并将其映射到 __consumer_offsets 主题的某个分区上。
__consumer_offsets 主题是 Kafka 0.9.0 版本引入的新特性,之前的版本是将 offset 存储在 Zookeeper 中。但是 Zookeeper 不适合大量写入,因此后来改为存储在 Kafka 自身中,提高了性能和可靠性。
提交 offset 是消费者在消费完一条消息后,将当前消费的 offset 值更新到 Kafka broker 中的操作。提交 offset 的目的是为了记录消费进度,以便在消费者发生故障或重启时,能够从上次消费的位置继续消费。
重置 offset 是消费者在启动或运行过程中,将当前消费的 offset 值修改为其他值的操作。重置 offset 的目的是为了调整消费位置,以便在需要重新消费或跳过某些消息时,能够实现这个需求。
提交 offset 的方式有两种:自动提交和手动提交。前面已经介绍过这两种方式的区别和用法,这里不再赘述。需要注意的是,无论是自动提交还是手动提交,都不保证提交成功。因为 Kafka broker 可能发生故障或网络延迟,导致提交失败或延迟。因此,消费者需要处理提交失败或延迟的情况。
重置 offset 的方式有两种:手动重置和自动重置。手动重置是指消费者主动调用 seek 或 seekToBeginning 或 seekToEnd 方法来修改当前消费的 offset 值。自动重置是指消费者在启动时根据 auto.offset.reset 参数来决定从哪个位置开始消费。
offset 的消费和保证主要涉及到两个方面:顺序性和一致性。
顺序性是指 Kafka 消息是否按照发送和接收的顺序进行处理。Kafka 只保证分区内的顺序性,即同一个分区内的消息按照 offset 的顺序进行发送和接收。但是不保证主题内或跨主题的顺序性,即不同分区内的消息可能会乱序发送和接收。因此,如果需要保证主题内或跨主题的顺序性,需要在生产者和消费者端进行额外的处理,例如使用同一个分区键或同一个消费组。
一致性是指 Kafka 消息是否能够被正确地发送和接收,不会出现丢失或重复的情况。Kafka 提供了三种不同级别的一致性保证:最多一次(At most once),最少一次(At least once)和精确一次(Exactly once)。
最后,希望本文能够对您理解 kafka offset 有所帮助,感谢阅读。
关注公众号【waynblog】每周分享技术干货、开源项目、实战经验、国外优质文章翻译等,您的关注将是我的更新动力!
我们要介绍的扩散模型的理论基础和非常重要的DDPM,扩散模型的实现并不复杂,但其背后的数学原理却非常丰富。在这里我会介绍这些重要的数学原理,省去了这些公式的推导计算,如果你对这些推导感兴趣,可以学习参
文中的配置定义了 Actor-Critic 算法在 MindSpore 框架中的具体实现,包括 Actor 和 Learner 的设置、策略和网络的参数,以及训练和评估环境的配置。
借助ModelArts提供的AI开发能力,实现基于LangChain+ChatGLM3的本地知识库问答,通过具体案例让开发者更加清晰的了解大模型AI应用开发过程。