环境:
- 内网,以下安装均为离线安装
- 系统:Linux cdh12 3.10.0-1160.e17.x86_64
- 内存(377G)、GPU(P40-25G)*8)
参考:
在回车接收许可时,可得按慢点,不然还得重新开始:
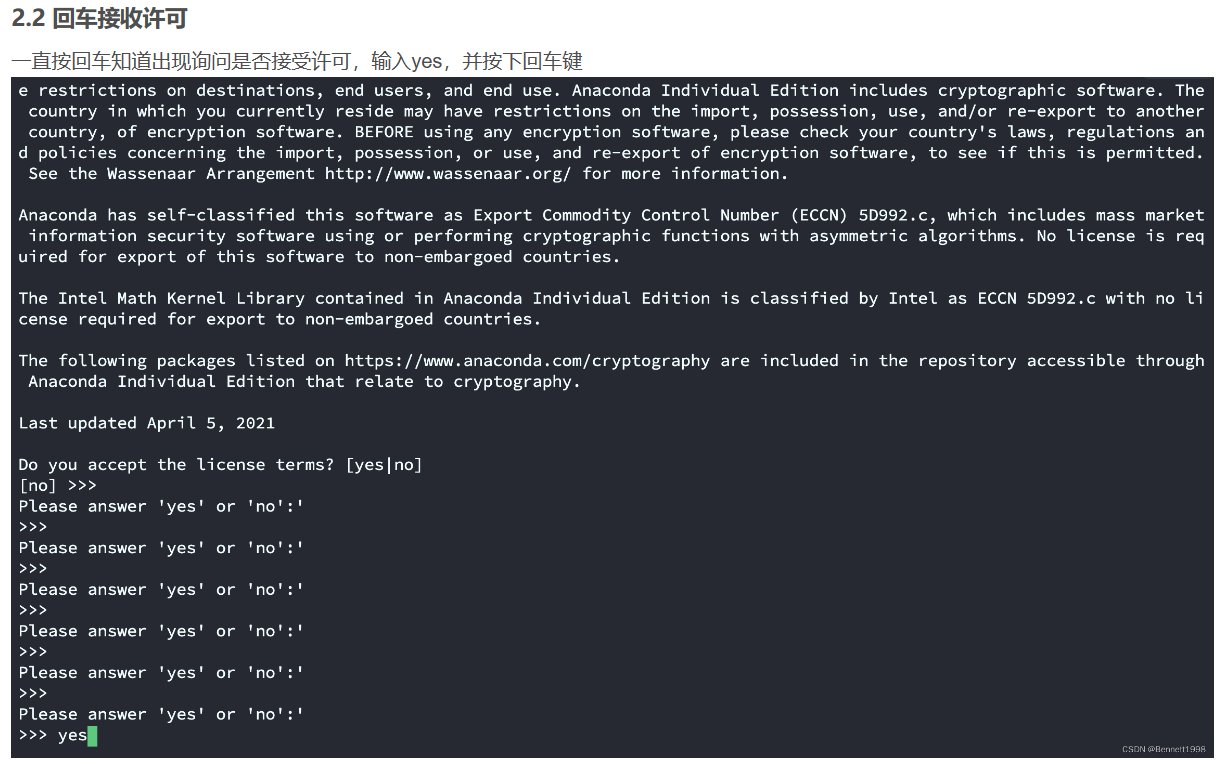
参考:https://blog.csdn.net/weixin_44864260/article/details/127770525
我拿到机器的时候已经安装好:
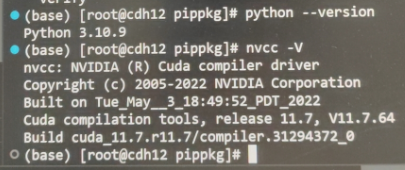
参考:https://blog.csdn.net/weixin_44864260/article/details/127770525
我这里选择的是:
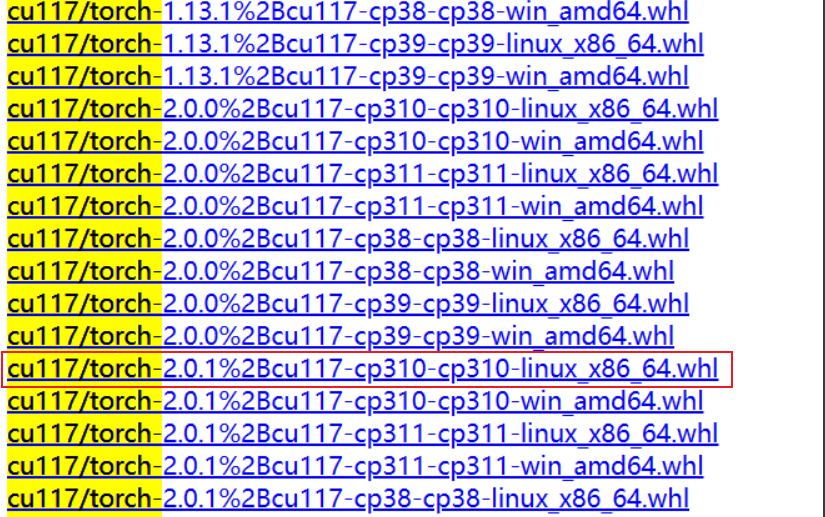
没有创建虚拟环境,直接在base中执行安装,但报错了,是依赖包没有安装:
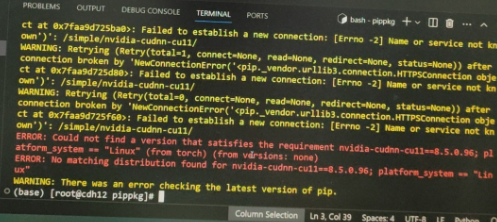
开始逐个安装依赖,阿里源地址(https://mirrors.aliyun.com/pypi/simple/),Pypi源(https://mirrors.aliyun.com/pypi/simple/):
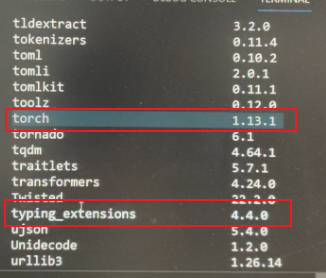
最好安装torch 2.0以上版本,但通过这种方式一直安装不上!!!
我这里的环境是:

所以需要下载,下载地址:清华源:
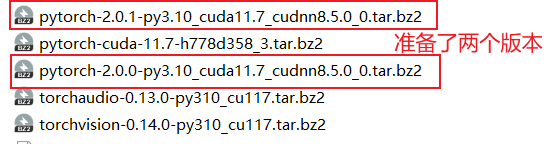
然后逐个安装即可:

检测一下:

主机:Windows,目标主机:Linux
重点就是密钥生成:
ssh-keygen复制
然后上传公钥至服务器!
注意:下载对应的ms-vscode-remote.remote-ssh插件时,内网和外网的VScode版本一定得一直,不然安装失败。
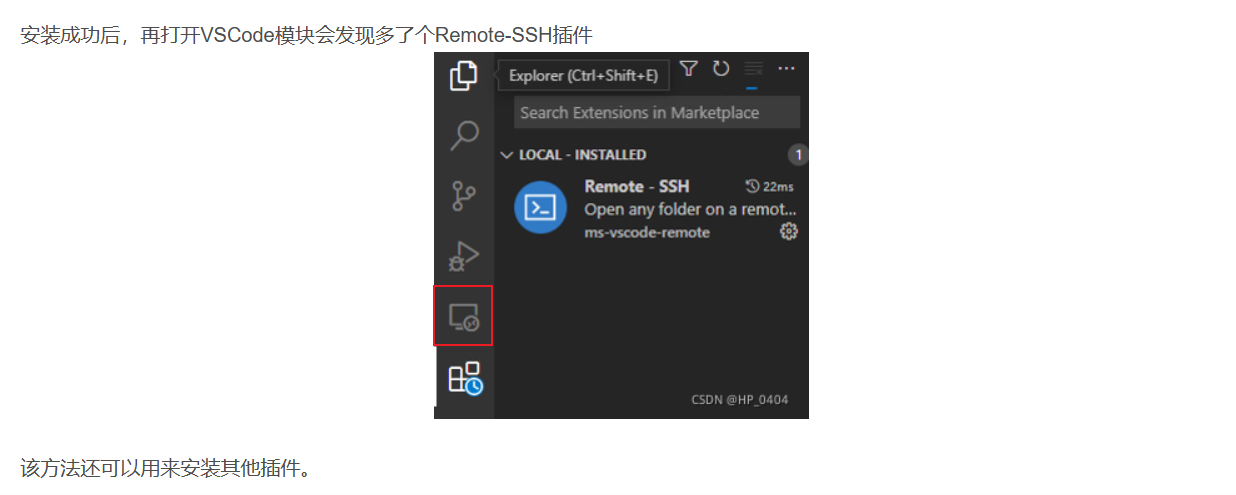
在执行完第2步时,我这在侧边栏中并不会出现远程连接的符号:
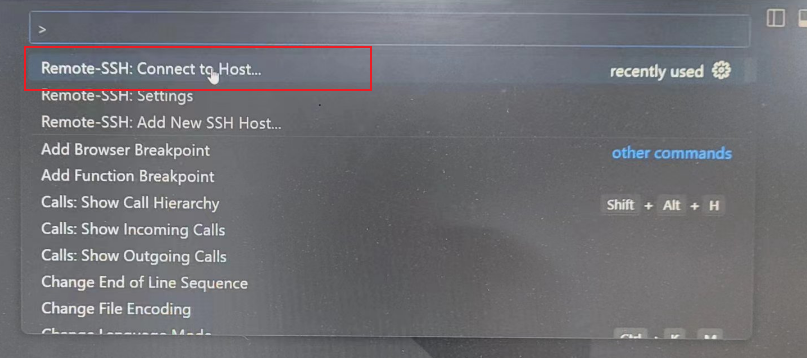
为了继续执行(),按F1调出命令控制,输入ssh ,选择:
在设置好连接信息后,选择对应的别名,根据提示填入密码,即可控制:
在远程给服务器安装vscode-server-linux-x64.tar.gz时,需要注意,替换commit_id即可,不加${}:
mkdir -p ~/.vscode-server/bin/commit_id
tar -zxvf /tmp/vscode-server-linux-x64.tar.gz -C ~/.vscode-server/bin/commit_id --strip 1
touch ~/.vscode-server/bin/commit_id/0
复制这样就可以了!
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]