敏感词过滤在社区发帖、网站检索、短信发送等场景下是很常见的需求,尤其是在高并发场景下如何实现敏感词过滤,都对过滤算法提出了更高的性能要求,Ahocorasick算法能够实现毫秒级的万字过滤匹配,能够很好的满足各种场景下的敏感词过滤需求。
Aho-Corasick算法通过将模式串预处理为确定有限状态自动机,对待匹配文本扫描一遍就能完成匹配。算法复杂度为O(n),即与模式串的数量和长度无关。AC自动机是多模式匹配的一个经典数据结构,原理是和KMP一样的构造Fail指针,不过AC自动机是在Trie树上构造的,但原理是一样的。
多模式匹配:
多模式匹配就是有多个模式串P1,P2,P3…,Pm,求出所有这些模式串在连续文本T1…n中的所有可能出现的位置。
例如:求出模式集合 {“nihao”,“hao”,“hs”,“hsr”} 在给定文本 sdmfhsgnshejfgnihaofhsrnihao 中所有可能出现的位置。
想要了解Aho-Corasick算法,就首先要从字典树与DFA开始说起:
https://www.cnblogs.com/vipsoft/p/17722820.html
字典树(Trie)是一种很特别的树状信息检索数据结构。利用字符串的公共前缀(common-prefix)来减少查询时间,搜索时间为O(d),d为树的深度。
字典树的原则:
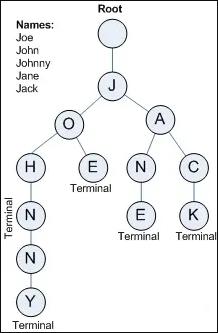
https://www.cnblogs.com/vipsoft/p/17759850.html
AC算法的主要思想就是构造的有限状态自动机,根据有限状态自动机会根据输入进行模式串匹配。有限状态自动机会随着字符的输入而发生状态转移,转移的状态有如下三种:
示例讲解
以经典的ushers为例,模式串是he/ she/ his /hers 构建字典树,如图:(红色表示接受态)
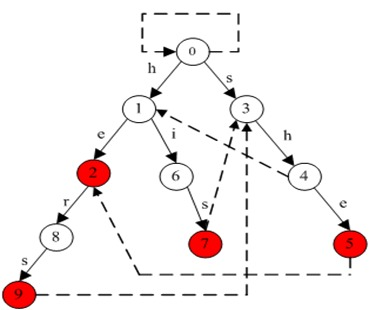
文本为ushers , 构建的自动机如图(带虚线)
自动机从根节点0出发,首先尝试按success表转移
按照文本的指示转移,也就是接收一个u, 此时success表中并没有相应路线,转移失败,失败了则按照failure表回去。
按照文本指示,这次接收一个s,转移到状态3,成功了继续按success表转移,h到状态4,e到状态5
r失败由5跳转步骤2,或者遇到output表中标明的“可输出状态”(she)。此时输出匹配到的模式串,然后将此状态视作普通的状态继续转移。
算法高效之处在于,当自动机接受了“ushe”之后,再接受一个r会导致无法按照success表转移,此时自动机会聪明地按照failure表转移到2号状态,并经过几次转移后输出“hers”。来到2号状态的路不止一条,从根节点一路往下,“h→e”也可以到达。而这个“he”恰好是“ushe”的结尾,状态机就仿佛是压根就没失败过,也没有接受过中间的字符“us”,直接就从初始状态按照“he”的路径走过来一样。
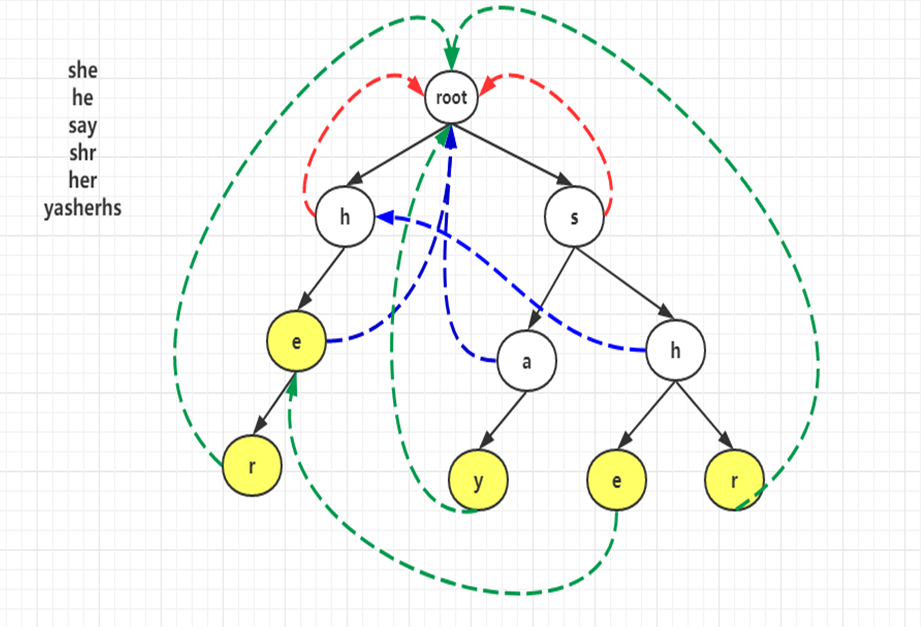
用 5 个模式串:"she","he","say","shr","her" 所建的字典树
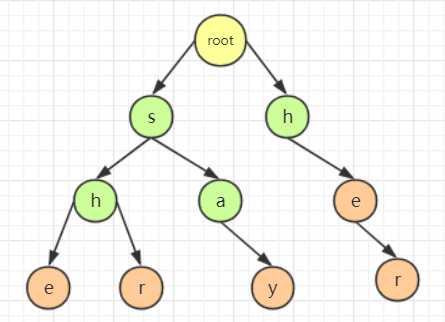
通过分析可知,"she" 具有后缀字符串 "he","her" 具有前缀字符串,因此当 "she" 模式串发生失配的时候,就可以通过失配指针继续匹配 "her" 模式串,那么就需要将 "she" 中的 "h" 结点的失配指针指向 "her" 的 "h" 结点,将 "she" 中的 "e" 结点的失配指针指向 "her" 的 "e" 结点。至于其他的结点,由于不存在共有的前缀字符串和后缀字符串,因此它们的失配指针指向根结点。因此对于如图字典树,失配指针的关系如图所示:

通过分析可以得知,进行跳转的另一个模式串的结点深度一定小于跳转之前的结点的深度,这是因为若跳转后的结点深度大于原结点的深度,就无法保证跳转后模式串的前缀字符串与进行跳转的模式串的后缀字符串相匹配,这样结点数量完全不够。
例如上文的例子中,通过失配指针联系的 "she" 中的 "h" 结点和 "her" 的 "h" 结点(蓝色标出)中前者的层数大于后者, "she" 中的 "e" 结点和 "her" 的 "e" 结点(紫色标出)中前者的层数也大于后者:
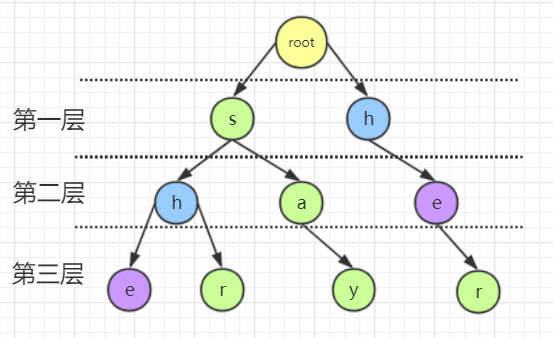
根据这个特点,我们可以通过访问当前结点的双亲结点的方式进行试探,对于某一个字母结点(原字母),通过对其双亲的失配指针的访问,寻找到其他的结点,这个结点满足其孩子结点中存在与原字母相同的结点,此时就把原字母结点的失配指针指向寻找到的结点中与原字母相同的孩子结点。若访问到了根结点,没有发现符合要求的结点,则失配指针指向根结点。
ahocorasick 目前改名为 pyahocorasick
https://pypi.tuna.tsinghua.edu.cn/simple/pyahocorasick/
#安装 ahocorasick 库
pip install pyahocorasick==1.4.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
复制# coding:utf-8
import ahocorasick
def make_AC(AC, word_set):
for word in word_set:
AC.add_word(word, word) # 向trie树中添加单词
return AC
def ac_demo():
'''
ahocosick:自动机的意思
可实现自动批量匹配字符串的作用,即可一次返回该条字符串中命中的所有关键词
'''
key_list = ["胀痛", "看东西有时候清楚有时候不清楚", "畏光"]
AC_KEY = ahocorasick.Automaton()
AC_KEY = make_AC(AC_KEY, set(key_list))
AC_KEY.make_automaton()
test_str_list = ["请问最近看东西有时候清楚有时候不清楚是怎么回事", "有时候眼睛胀痛,畏光"]
for content in test_str_list:
name_list = set()
for item in AC_KEY.iter(content): # 将AC_KEY中的每一项与content内容作对比,若匹配则返回
name_list.add(item[1])
name_list = list(name_list)
if len(name_list) > 0:
print("\n", content, "--->命中的关键词有:", "、".join(name_list))
if __name__ == "__main__":
ac_demo()
复制 请问最近看东西有时候清楚有时候不清楚是怎么回事 --->命中的关键词有: 看东西有时候清楚有时候不清楚
有时候眼睛胀痛,畏光 --->命中的关键词有: 畏光、胀痛
复制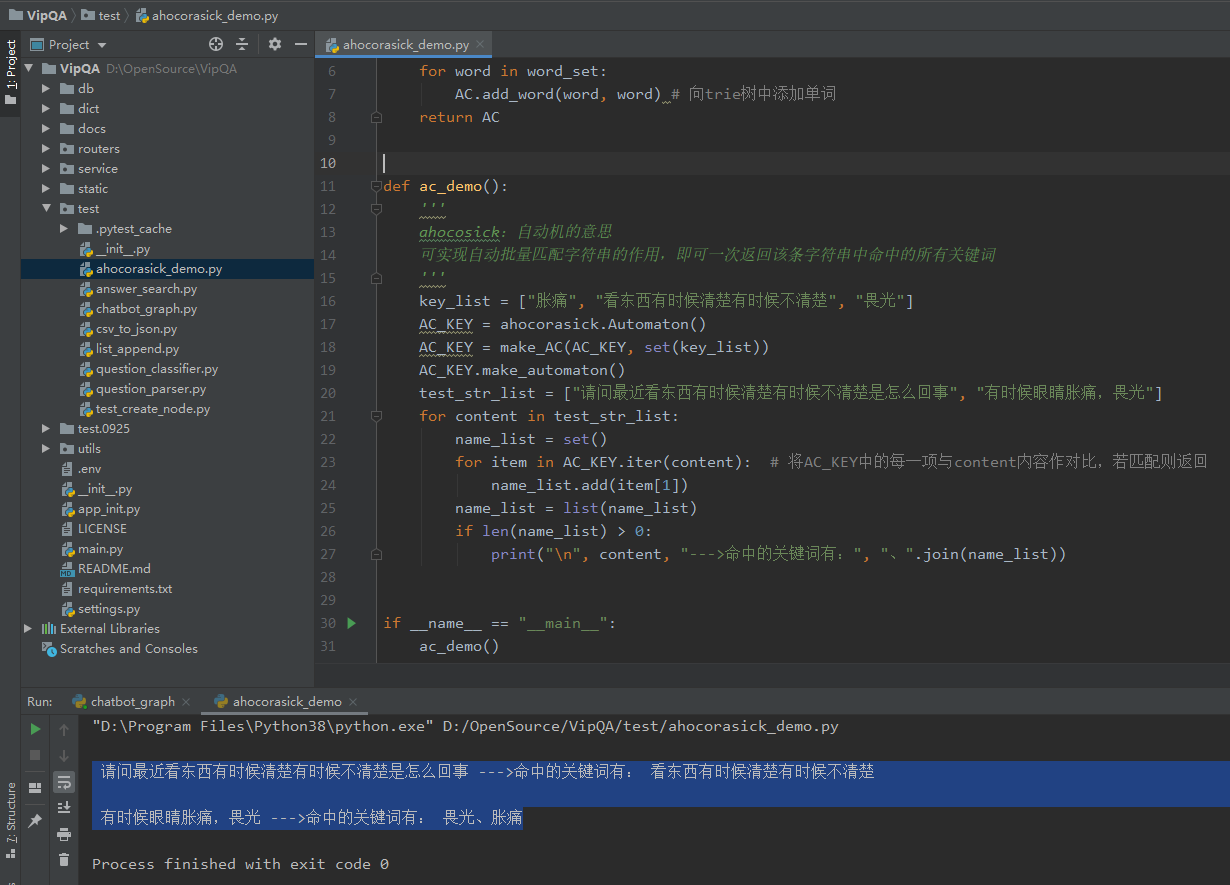
源代码地址:https://gitee.com/VipSoft/VipQA
在线问诊:https://www.cnblogs.com/vipsoft/p/17728136.html#构建-trie-字典树
参考:
https://www.cnblogs.com/linfangnan/p/12651873.html
https://www.cnblogs.com/cmmdc/p/7337611.html