这是对Raft算法的一个粗略介绍,来源是
首先,我们定义一个节点为一台存储数据的服务器。
我们在体系中有很多这样的节点,也可以有一些客户来发送信息(例如值)给服务器。
显然的,如果只有一个节点,那么一致性(consensus)是非常容易达成的。但如果有很多台服务器,这件事情就没那么简单了(我们可能会面临几台服务器的断网,时钟错乱...这种问题)
这就引出了我们的主题:分布式一致性。本文所要介绍的Raft算法便是为了达成分布式一致性。
我们首先确定一个节点的三个状态:
追随者(follower)
候选者(candidate)
领导者(leader)
在刚开始的时候,所有的节点都处于追随者的状态,如果追随者没有听到领导者的信息,它们可以变成候选者。候选者会向其他节点发出选票请求,这些节点也会返回它们的选票。
如果一个候选人从大多数节点中获得了选票,那它就可以成为领导者。
上述过程被称为领导人选举(Leader Election)
有了领导者之后,所有对系统的改变信息都会发送到领导者这里。
领导者会将这条信息(例如set 5)存在自己的日志(log)中,作为一条新的条目(entry)。
需要注意的是,尽管这里我们加入了这条日志,但它并没有被提交,所以值并不会被修改,这本质上也是为了维持一致性。
这时领导者会把这条指令发给所有的追随者,并持续等待直到大部分追随者都写下了这一条指令(可以想象在写下指令后追随者会发送指令给领导者)。这时候领导人会提交这条指令(改变值)
相似地,领导者会将提交这条指令(改变值)的信息发送给所有追随者。
这时候,可以期待大部分节点之间构成了对系统状态的一致性。
上述过程被称为日志复制(Log Replication)
首先值得注意的是,在Raft中有两个计时器来控制选举。
选举倒计时:当选举倒计时(一般为150ms~300ms之间的一个随机数)结束,且在这段时间内追随者没有收到来自领导者的任何信息,那么它会变成一个候选者。自然,这个时候新的一次选举也就开始了
一个候选者先是为自己投票,然后再发送投票请求给其他节点。
如果接收节点在这一轮还没有投票,那么它就会给这个候选者投票。在投票后,该接收节点会重置选举倒计时。
如果候选者得到了大部分选票,它就能成为领导者。接下来就是发送各种信息了。这就要联系到第二个计时器了。
心跳倒计时:所有的和系统有关的信息(改变值,修改日志)都是以心跳倒计时为间隔发送的。当然,接收到这些信息也会使得它们的选举倒计时更新。
例如在上图中的情况中,当领导者宕机,A的选举倒计时结束的更快,那么就能更早地发出选票,所以它成为了领导者。
可以期待,如果有几个节点的选举倒计时结束的都很快,那么可能会出现票数相等的情况
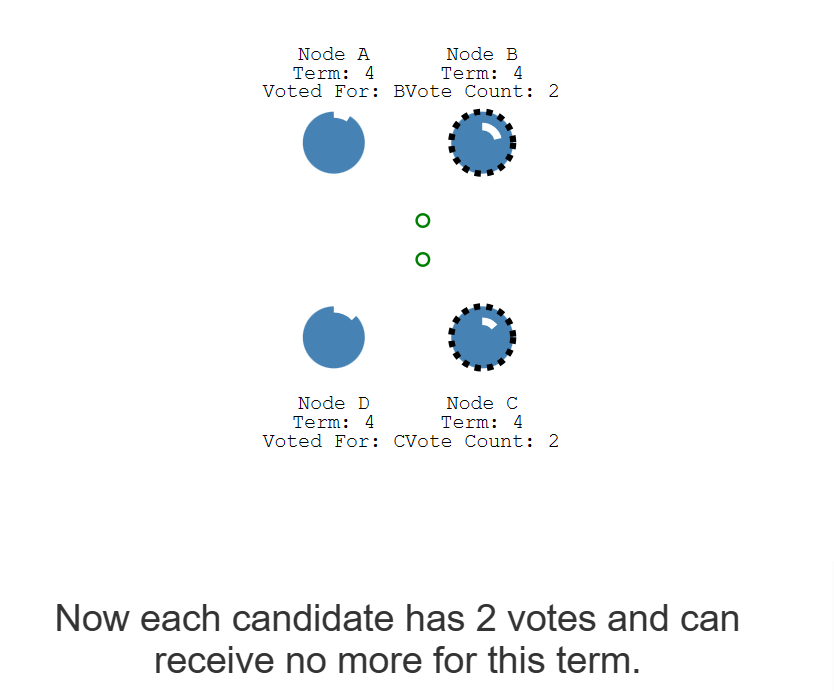
分票的时候,因为待机时间是随机的,所以可以期待,在剩下的节点中,选举倒计时结束的快的节点可能会成为领导者。
正如上文所说,如果我们有了领导者,我们就得经由领导者把所有系统的变化复制到所有节点,而这是通过上文中的”加入日志“请求和”改变值“请求实现的。
我们可以给出日志复制这一过程的步骤:
客户向领导者发出”修改值“的指令
领导者把”修改值“这件事情加入日志,作为条目
领导者向追随者们发出”把‘修改值’这件事情加入日志“的信息
领导者尝试接收信息,如果接收量超过一半,那么就把值修改了
领导者将修改的值(或者done的信号)返回给客户
领导者将”修改值“这件事情发送给追随者们
追随者们修改值,并返回修改成功这件事情
在上述过程中,我们介绍了日志复制的过程。那我们可以思考,如果系统遭受了攻击呢,这时候一致性该如何保证?
我们考察网络中出现隔离的过程:
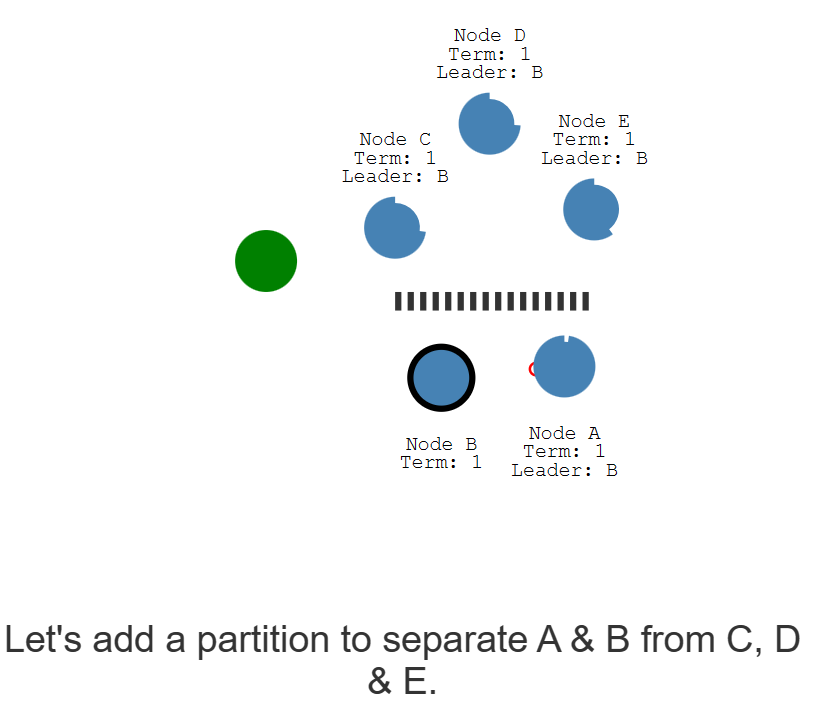
首先,可以想象的是,会有两领导者在不同的任期中(为什么?)。
我们接下来考察两个客户试图更新两个领导者的过程:
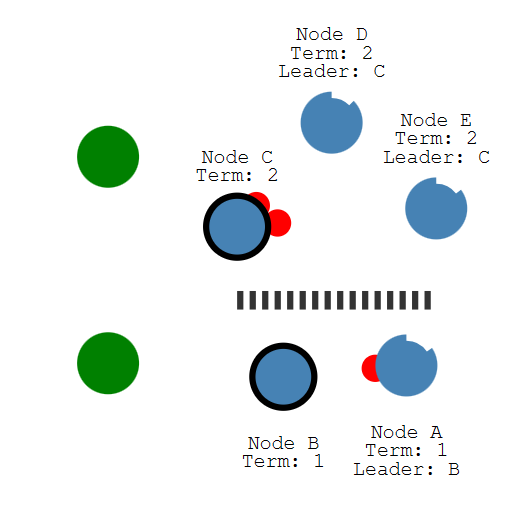
如果下面的客户想更新值为3,把这条信息传输给了B呢?好像值并不会改变,因为B接收到的追随者并未超过一半。
上面的客户希望把值设置为8,它把信息传给了C。这个操作则可以完成。
现在我们来修复这个隔离。
这时候,C的任期高于B,因而B不会当领导者。(退位的充要条件)
同时,A和B会回滚它们的日志来和C的日志相符。
以上内容只是对于Raft算法的感性理解,在细节上还有很多地方并未完善!!!
这是第一个任务,主要内容是完成Leader Election(难度:defined as moderate)
具体而言,应该选出一个领导者(他在没有出事之前一直都是),如果出事了,选出新的领导人。
提示如下:
在Raft这个结构体中加入信息,也要开一个LogEntry的结构体
在RequestVoteArgs/RequestVoteReply中加入信息,并修改Make()来产生一个Go程,使得每个服务器在一段时间没收到他人信息的时候开始领导人选举。同时,在RequestVote()中加入信息来获取投票这一机制。
为了有心跳,定义AppendEntries()这一结构体,并让领导人周期性地发送,同时这一函数也要重置选举倒计时。
用随机化来确保不是所有节点都同时结束冷却。
心跳不能超过10次每秒
测试希望领导人能在5秒内选出来,因而合适的选举倒计时很重要
论文中150ms~300ms的选举倒计时的使用条件是心跳远快于这个时间,所以可能我们的实现中选举倒计时会更长一些,但不能5秒内选不出领导人。
使用Go中的随机库
如果希望等一会儿,就用time.Sleep()
别忘了实现GetState()
实现的方法和结构体必须以大写字母开头,注意warnings
论文中的Figure2非常重要。它描述的十分准确,其中的每一条规则都应当被细化完成。
例子:
If election timeout elapses without receiving RPC from current leader or granting vote to candidate: convert to candidate。这意味着两种情况都要变成候选者。
在收到heartbeat的时候,不应该仅仅把election timer重置,仅仅返回`success`
在收到hearbeat的时候,不应该把这个条目之后的日志全部重置,因为可能我们告诉了领导者这些条目我们已经拥有,这样做意味着回滚。
除非严格遵循Figure2,不然很容易有很多错。错误的主要来源:活锁、对RPC的不当处理、不遵守文档,没理解部分术语。
可能说,你的程序每个线程都没阻塞,但是都没有做出实质性的结果(例如一直在选领导,领导一直没选出来等)。可能的例子如下:
选举倒计时的重置是否恰如Figure2所说?充要条件为收到当前领导(term >= 你)的信息/你要开始一轮选举了/你给别人投票了(如果不投,不用reset)
什么时候才要开始选举呢?特别地,如果是候选者,且选举倒计时归零,则应该开启新一轮选举。
注意Rules for Servers。举个例子,如果这一任期中你已经投票了,然后有更高级别任期的RPC发给了你,你应该先减小自己的任期(这也会重置一些东西),接着解决RPC,这可能让你再一次投票
这里面有挺多细节的,建议注意以下几点:
如果一步说要“返回错误”,那么就得立刻返回,并且不用执行下面的任何操作。
(后面的2A好像都用不着了...等待更新)