最近在写后端接口的时候,需要对.c、.conf等类型的文件进行读写操作,在这里整理一下学习收获。
file库是python中用于处理文件的读取、修改等操作,引入方式为
import file
复制使用open()函数打开文件,语法为:
import file
f=open(file_name="xx.txt", mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
复制其中,file_name为文件名,mode为打开文件的模式,buffering为缓冲区大小,encoding为编码格式,errors为错误处理方式,newline为换行符,closefd为关闭文件描述符,opener为自定义开启方式。
比较常用的参数为:file_name、mode、encoding。
file_name是文件的绝对路径或者相对路径。mode的常用取值如下: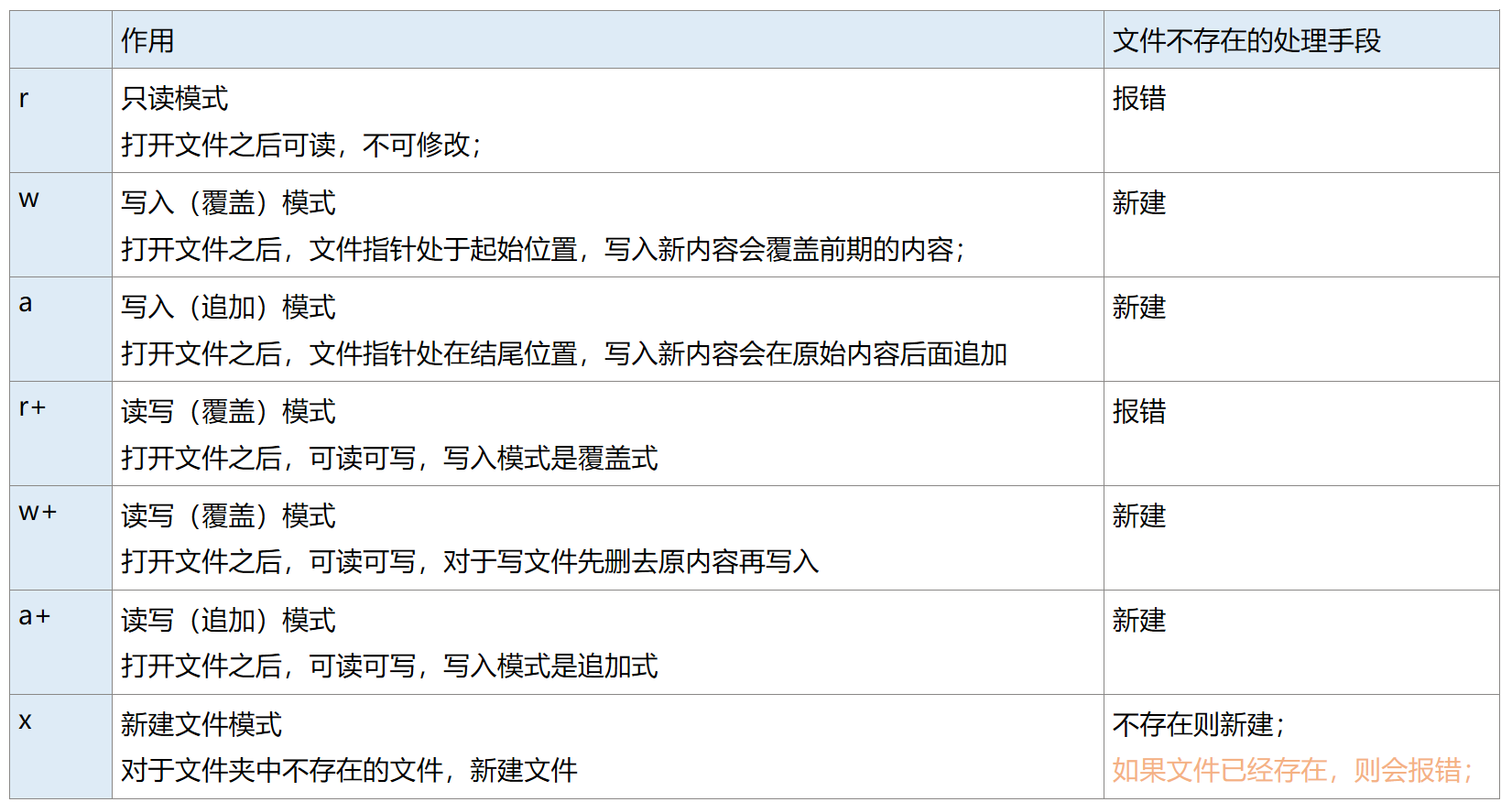
encoding的常用取值如下:UTF-8编码。文件读取的方式有两种:一种是一次性读取所有内容,一种是按行读取。
假设有文件xx.txt,内容如下:
第一行内容; 第二行内容, 第三行内容 第四行内容 ……复制
import file
with open(file_name="xx.txt", mode='r') as f:
content=f.read()#从头到尾进行文件读取
print(content)#打印整个文件内容
复制输入效果类似于:
第一行内容;第二行内容,第三行内容第四行内容……复制
read()还可以传入数字,形成read(n),表示读取n个字符。
readline()和readlines()。readline()是每次读取一行文件内容,readlines()是将文件内容按行读取到一个列表中。readline()的使用方法如下:import file
content_line="读取内容:\n"#设置起始内容
with open(file_name="xx.txt", mode='r') as f:
while content_line:##当读取内容不为空的时候
print(content_line)#打印整个文件内容
content_line=f.readline()#逐行读取文件内容
复制输入效果类似于:
第一行内容; 第二行内容, 第三行内容 第四行内容 ……复制
readlines()的使用方法如下:
import file
with open(file_name="xx.txt", mode='r') as f:
content=f.readlines()#读取全部文件内容,按行分割,形成列表
print(content)#打印整个文件内容,是一个列表格式
复制输入效果类似于:
[第一行内容;
第二行内容,
第三行内容
第四行内容
……]
复制文件写入的方式有两种:一种是一次性写入所有内容,一种是按行写入。
import file
content="待写入内容,可以很长"#设置写入内容
with open(file_name="xx.txt", mode='w') as f:
f.write(content)#写入文件,这是使用的是覆盖写入
复制writelines(),将列表中的内容按行写入文件。writelines()的使用方法如下:import file
content=["写入内容1\n","写入内容2\n","写入内容3\n"]#设置写入内容
with open(file_name="xx.txt", mode='w') as f:
f.writelines(content)#写入文件
复制此时,文件内容为:
写入内容1 写入内容2 写入内容3复制
需要注意的是,如果列表content中的元素没有添加换行符,writelines()不会自动添加换行符,因此可能会出现多行内容写入到一行的情况。
因此,如果需要换行,需要在列表中的元素中添加换行符。
tell()函数用于判断文件指针当前所处的位置
使用方式如下:
import file
with open(file_name="xx.txt", mode='r') as f:
print(f.tell())
f.read(1024)
print(f.tell())
复制输出结果为:
0
1024
复制而seek()函数用于移动文件指针到文件的指定位置。
常见的使用方式如下:
import file
with open(file_name="xx.txt", mode='r') as f:
print(f.tell())#输出:0
f.read(1024)
print(f.tell())#输出:1024
f.seek(203)#从文件头开始,移动到第203个字符处
print(f.tell())#输出:203
复制在这里介绍一下seek函数的参数:
seek(offset, whence)
# offset:必需参数,偏移量,相对于某一个基点的字符移动距离,正数表示按照文件流方向向后移动,负数表示逆着文件流方向向前移动
# whence:可选参数,可设置基点位置,0表示文件头(默认情况下),1表示当前位置,2表示文件尾
复制当然,在Python中,还有一个专门用于文本处理的库,那就是re库。
我们读取文件内容,肯定不是单纯为了输出或者重新写入,对于文本我们一定有一些查找、定位的需求。
在python中,使用正则表达式能应付大多数情况下的数据处理需要,这就需要用到re库,因此,我会在后续的更新中跟进正则表达式和re库的相关知识,敬请期待。